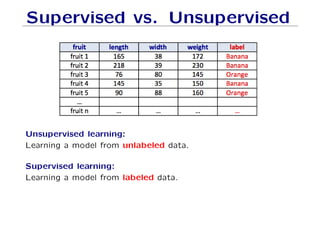
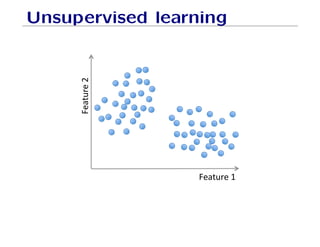
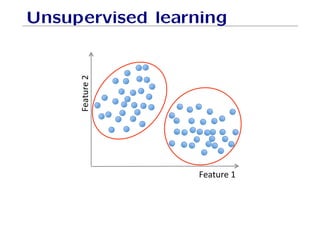
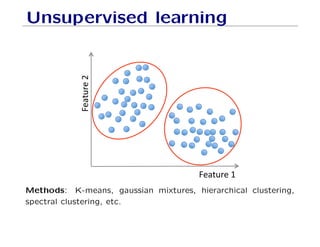
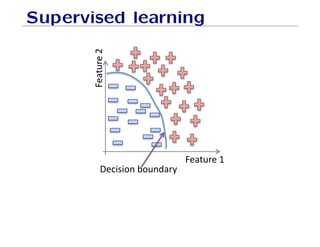
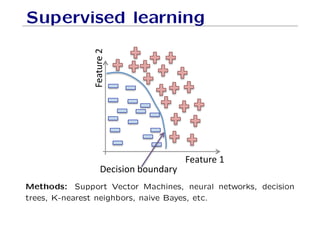
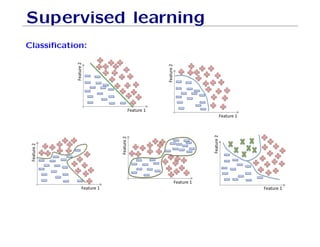
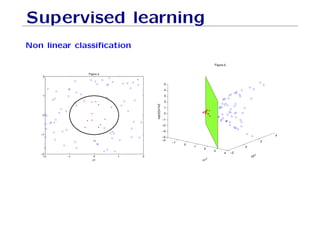
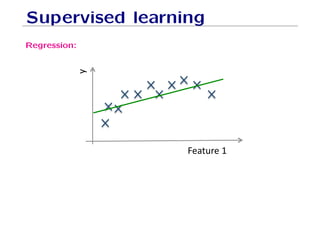
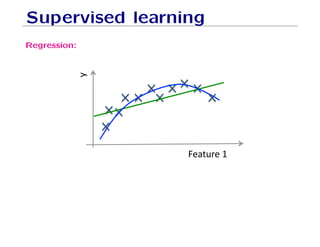
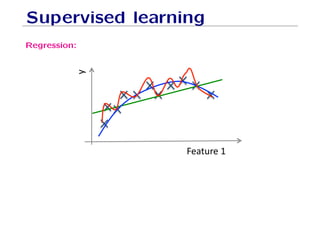
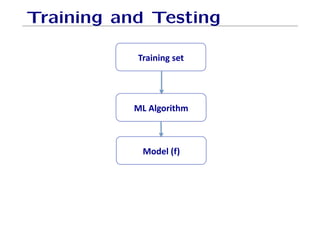
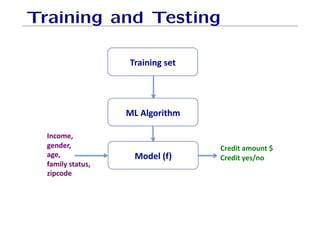
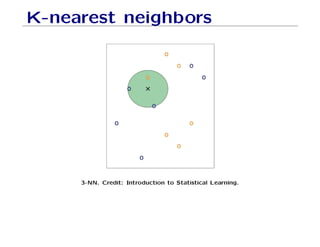
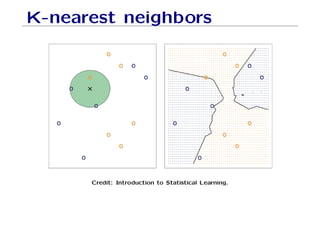
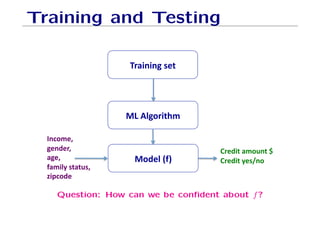
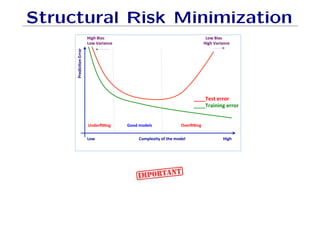
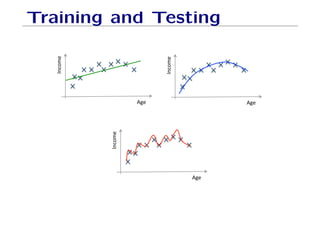
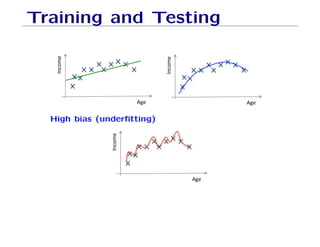
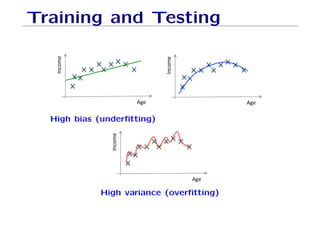
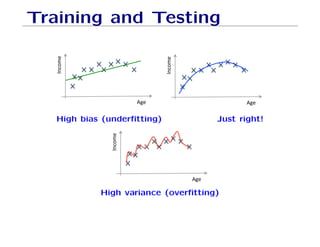
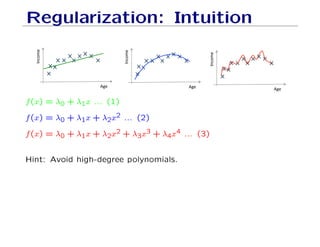
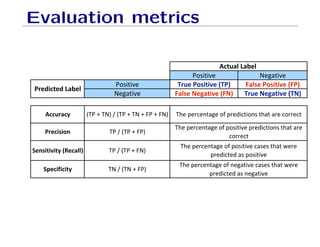
The document outlines fundamental concepts of machine learning, including various types of data and the importance of data science in processing vast amounts of information. It differentiates between supervised and unsupervised learning, explains key methodologies such as k-nearest neighbors and the necessity of training, validation, and testing in model development. Additionally, it discusses potential issues like overfitting and underfitting, emphasizing the need for regularization and cross-validation to improve model performance.