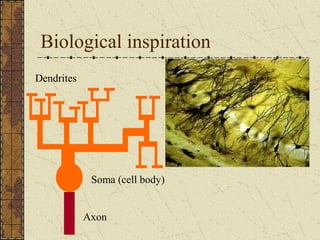
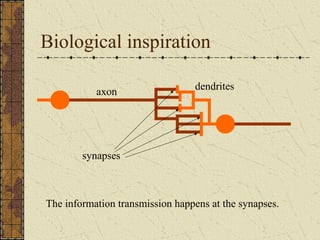
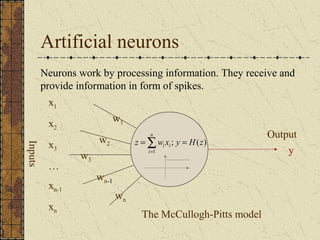
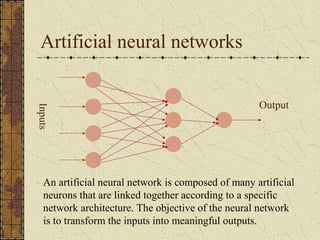
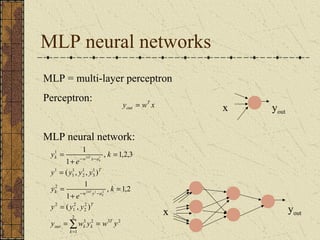
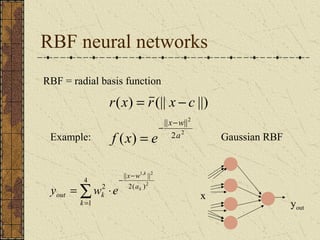
This document discusses artificial neural networks and their learning processes. It provides an overview of biological inspiration for neural networks from the nervous system. It then describes artificial neurons and how they are modeled, including the McCulloch-Pitts model. Neural networks are composed of interconnected artificial neurons. Learning in neural networks and biological systems involves changing synaptic strengths. The document outlines learning rules and processes for artificial neural networks, including minimizing an error function through optimization techniques like backpropagation.