


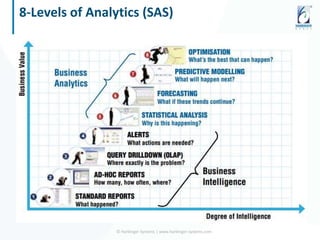



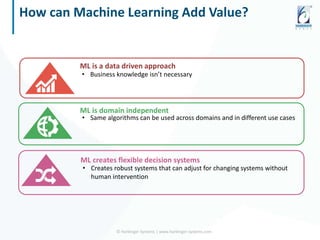
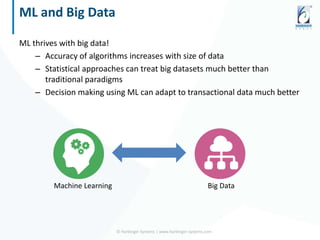


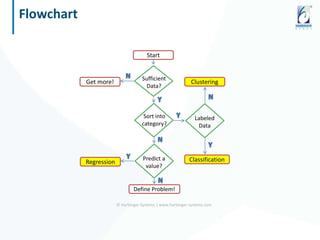










The document discusses the application of data science and machine learning to enhance government services by extracting valuable insights from complex data. It highlights the benefits of machine learning across various sectors, including fraud detection, product recommendations, and medical diagnosis, while emphasizing the importance of tools and technologies that integrate seamlessly with existing data systems. The conclusion stresses the necessity of utilizing data for delivering high-value services and remaining competitive in the future.





























































































