Downloaded 209 times






















The document discusses machine learning methods for predicting preventable diseases and enhancing healthcare outcomes, highlighting various studies and technologies. It outlines the importance of disease prediction, success rates of different algorithms, and the future potential of wearable devices and digital twins in healthcare. Key topics include the effectiveness of machine learning in anticipating conditions like septic shock, heart disease, and Alzheimer's, with a promise to transform disease management and save lives.
Introduces Machine Learning in disease prediction, outlines key topics: preventable diseases, studies, and future.
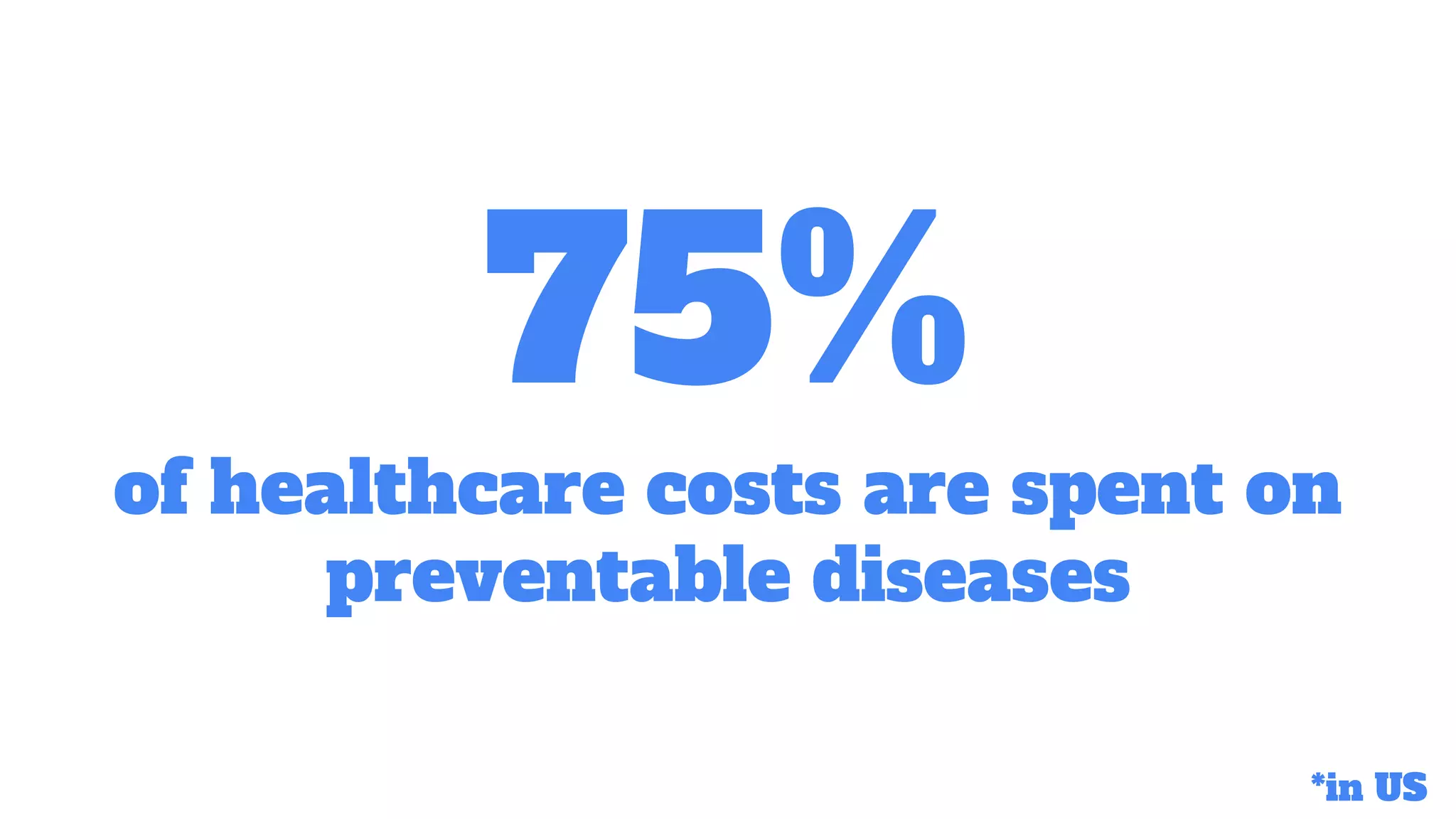
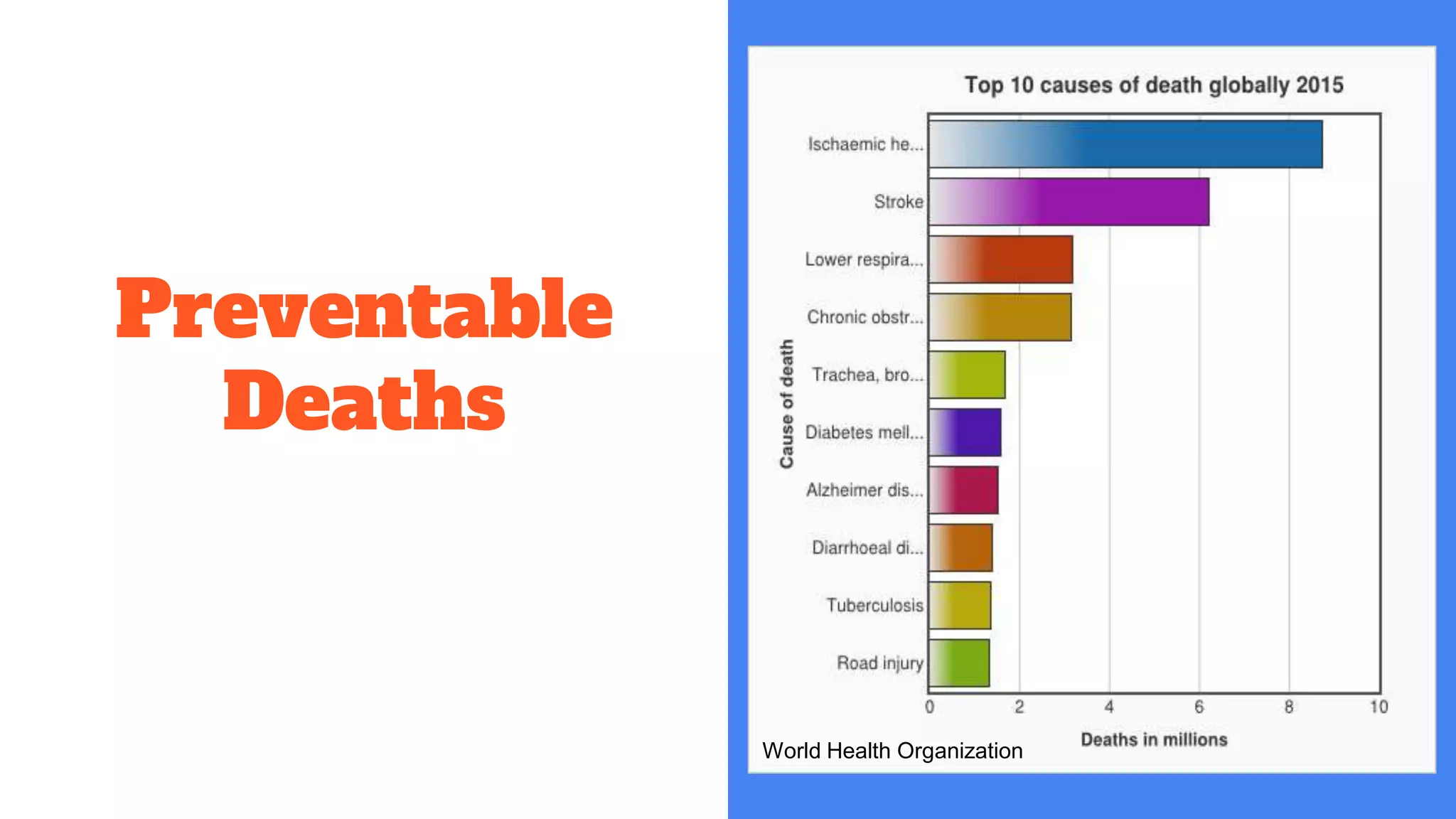
Focuses on preventable diseases and deaths, highlighting statistics like 75% healthcare costs related to preventable diseases.
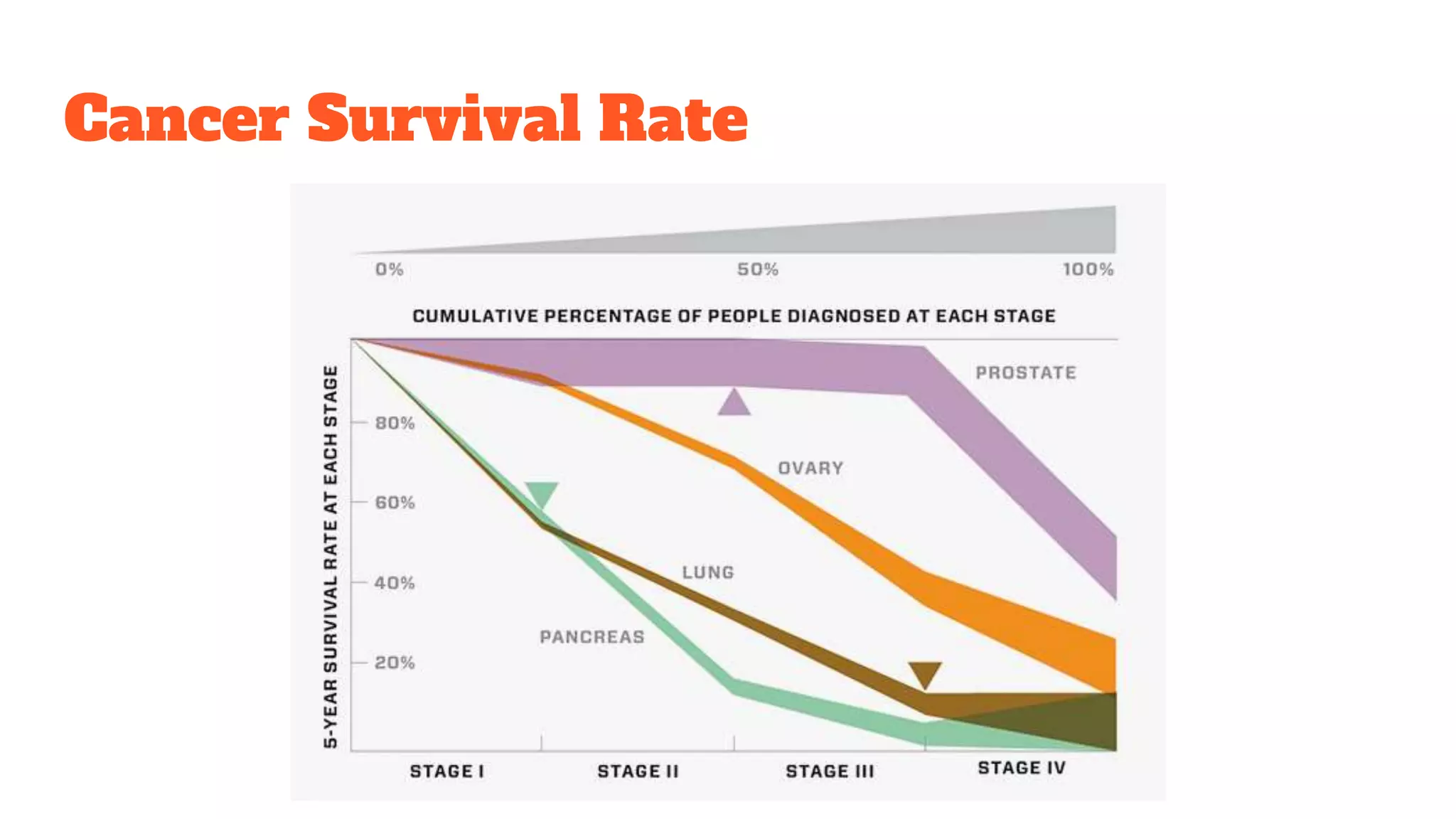
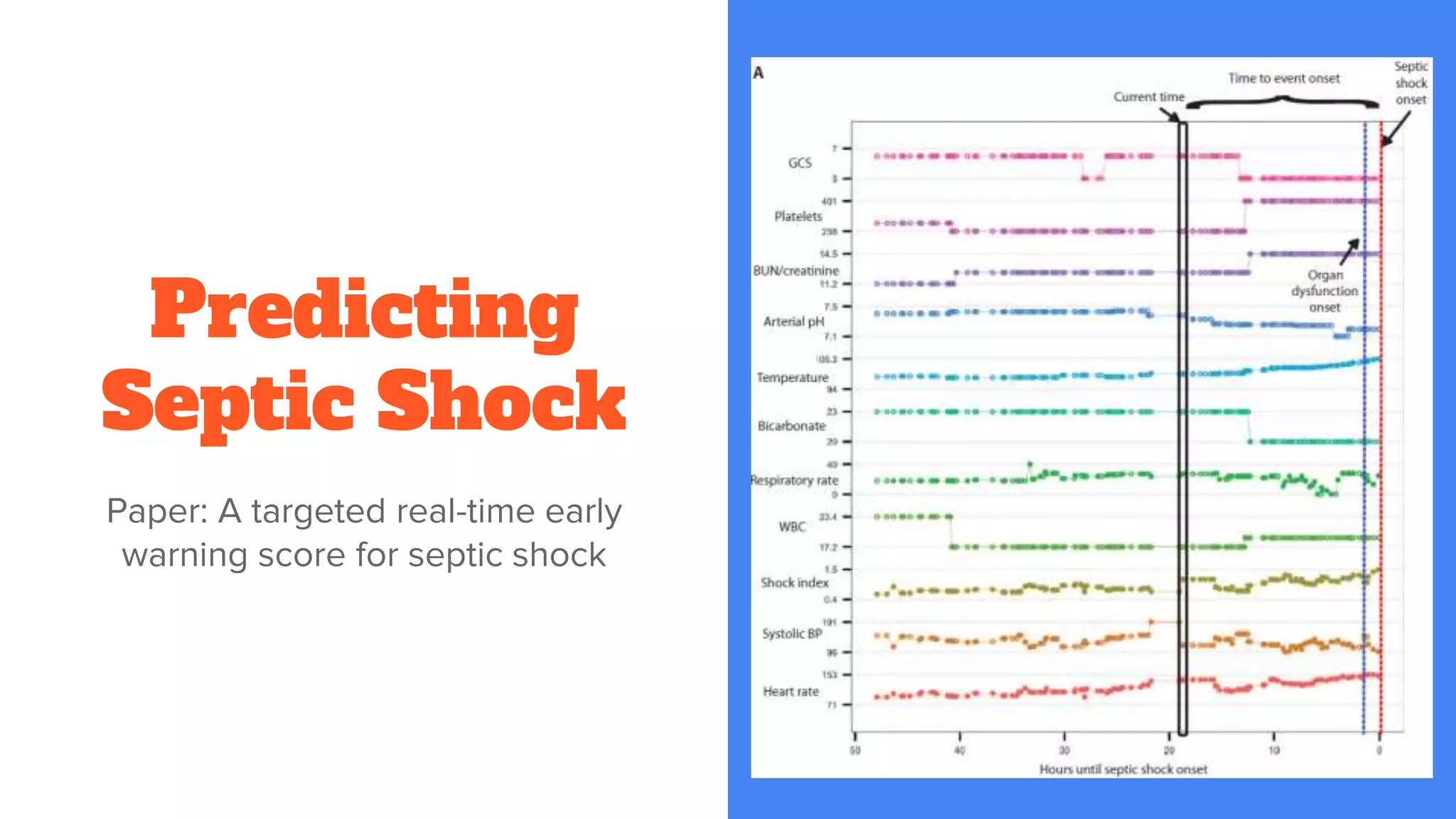
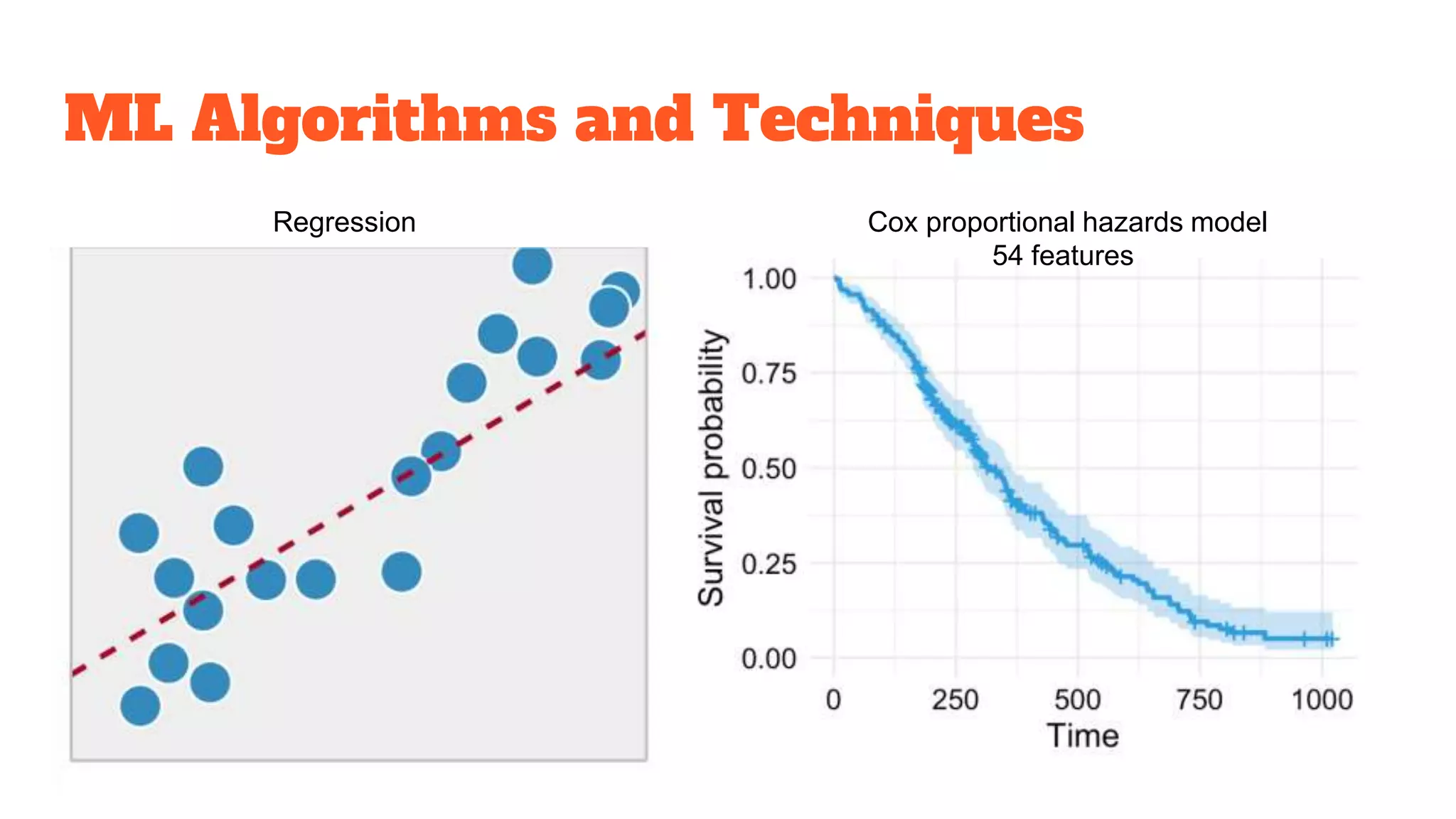
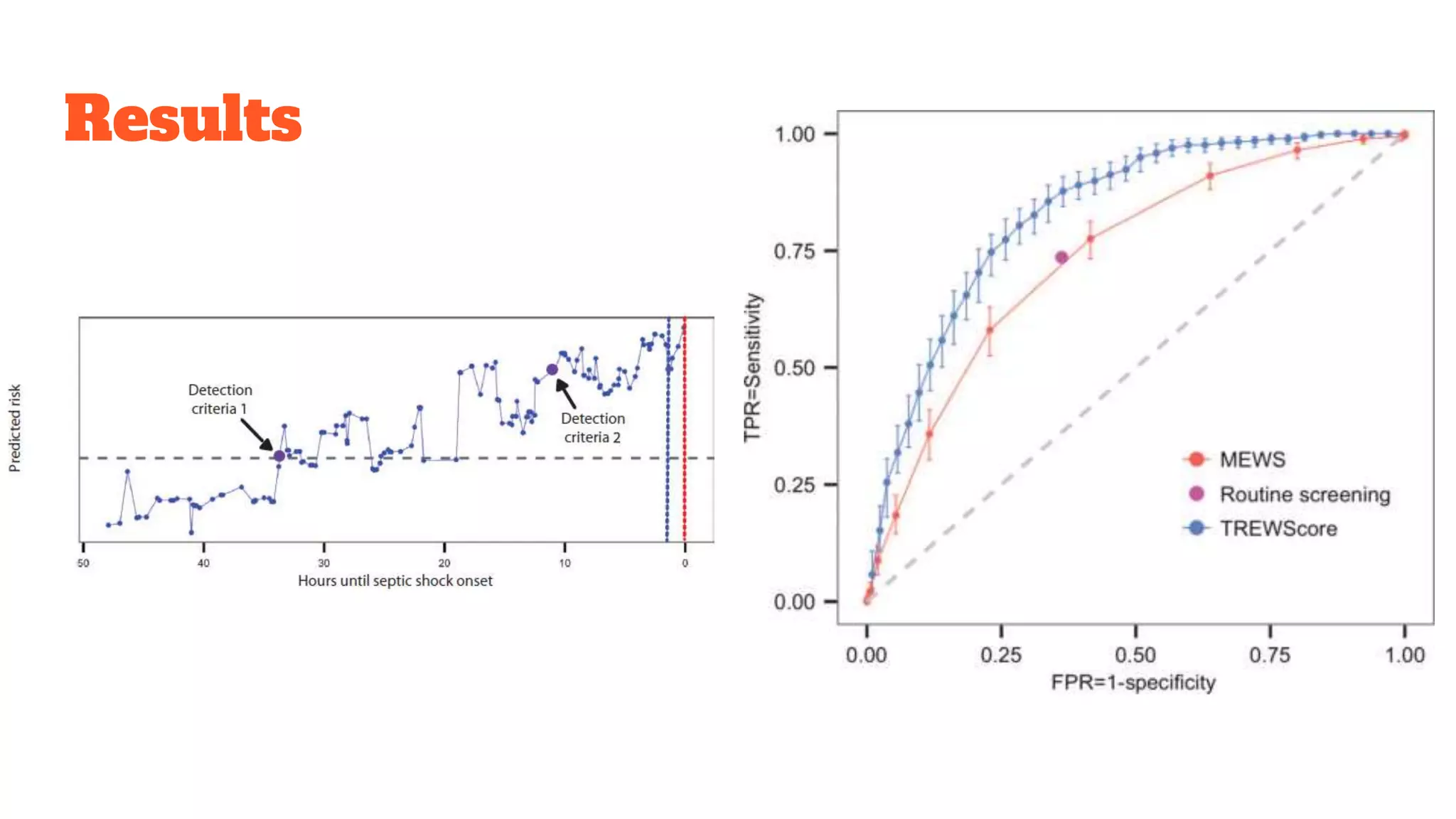
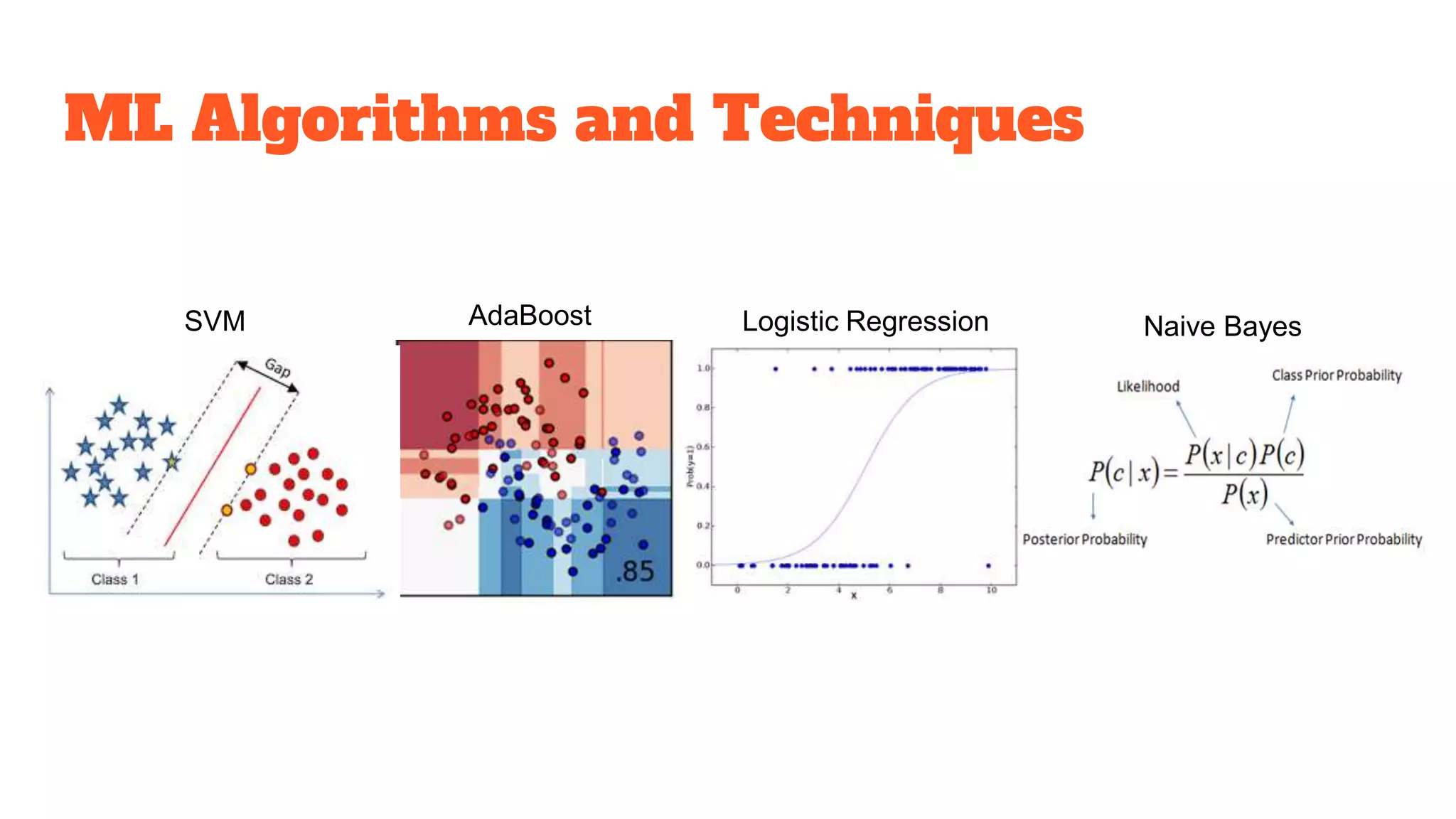
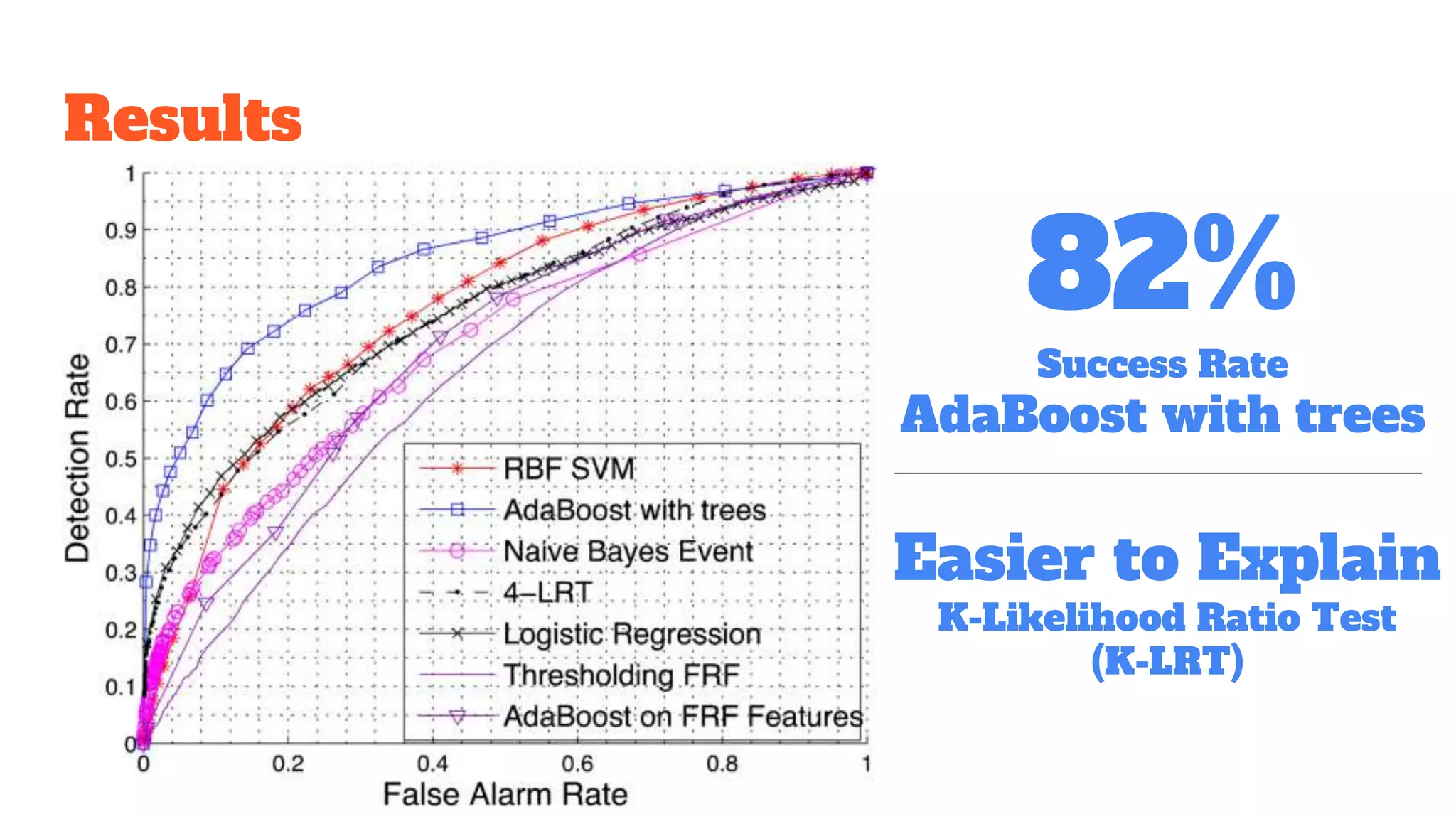
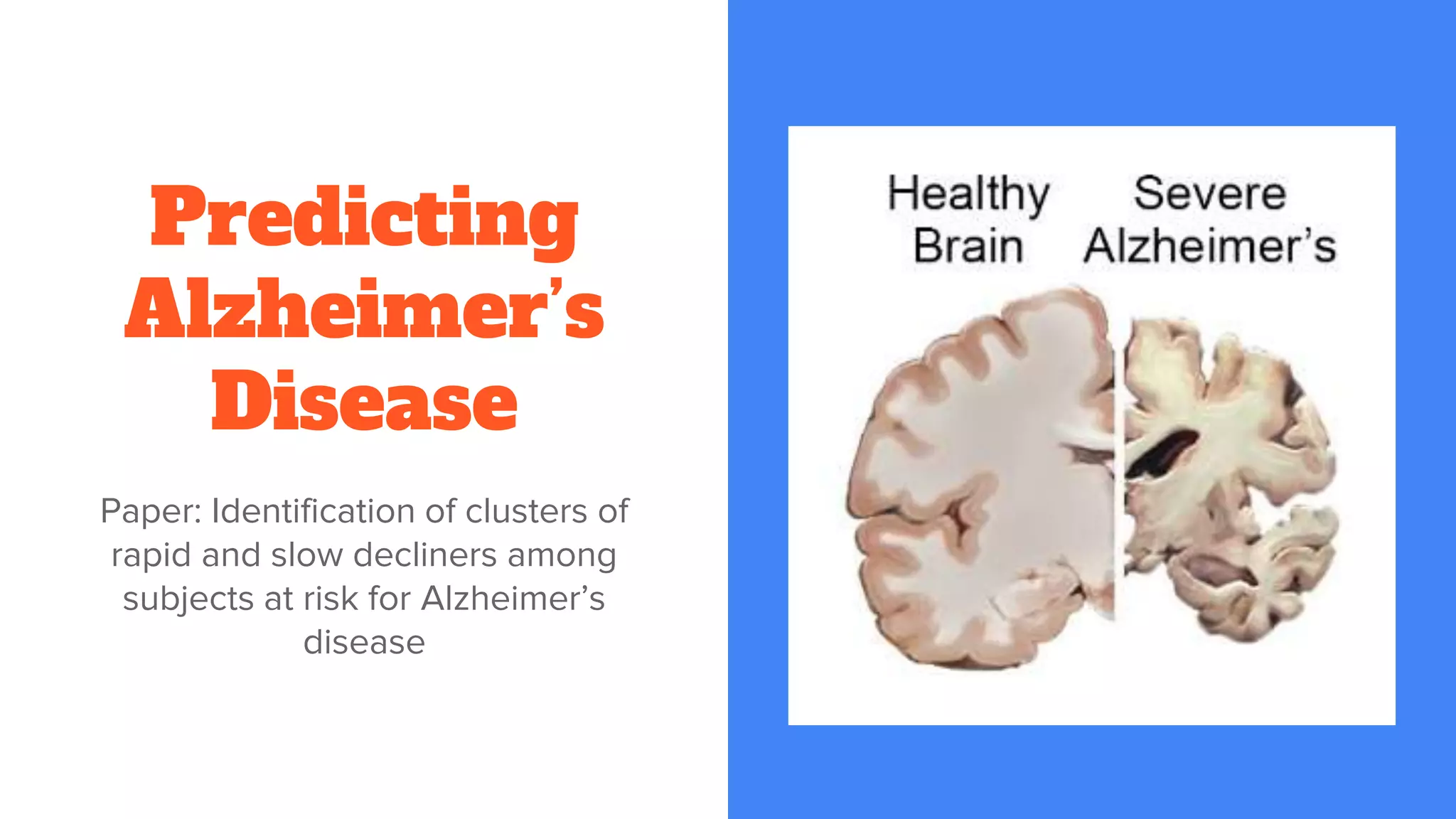
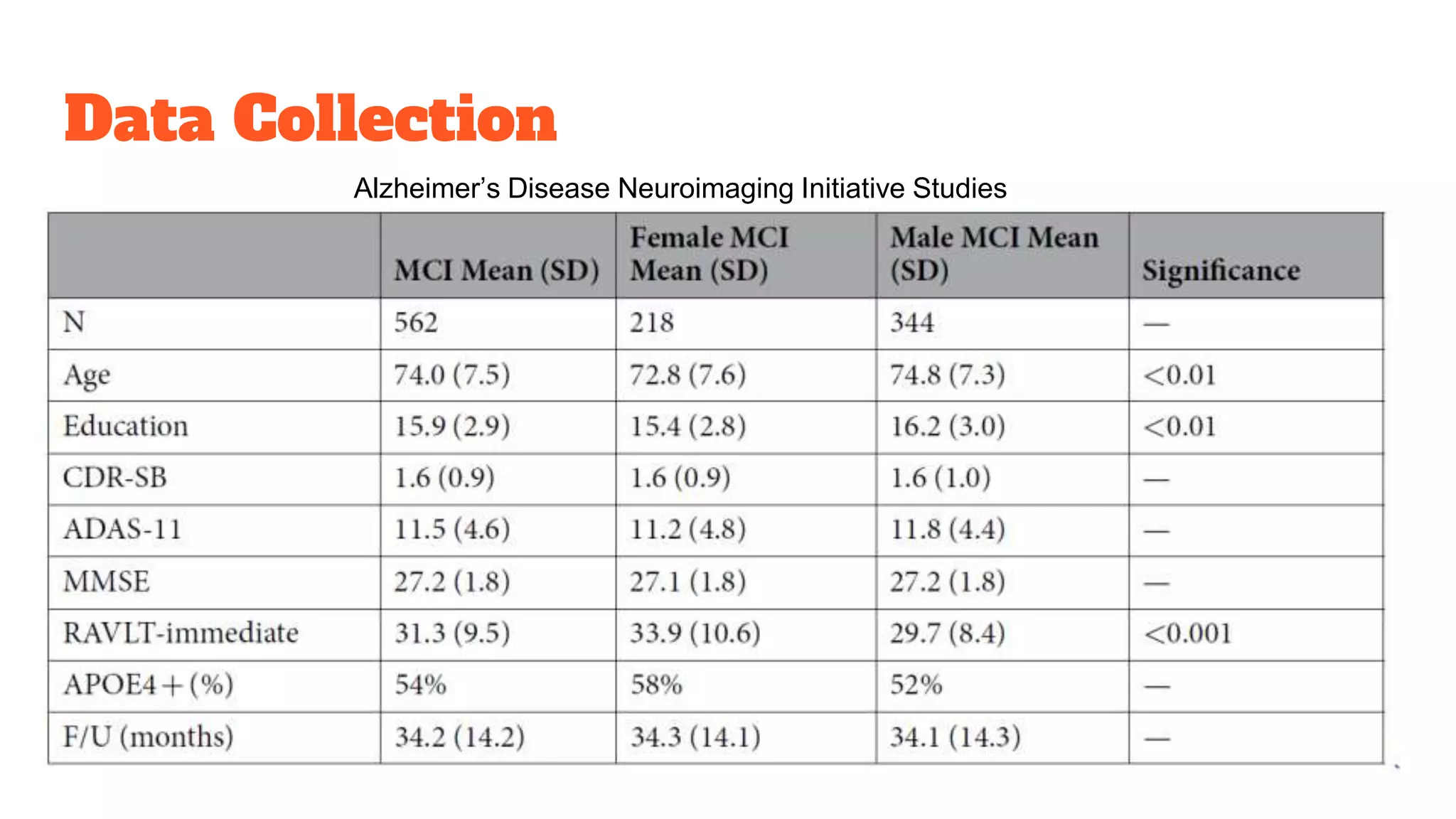
Detailed exploration of ML methods used for predicting diseases like septic shock, heart disease, and Alzheimer's, with data collection and results.
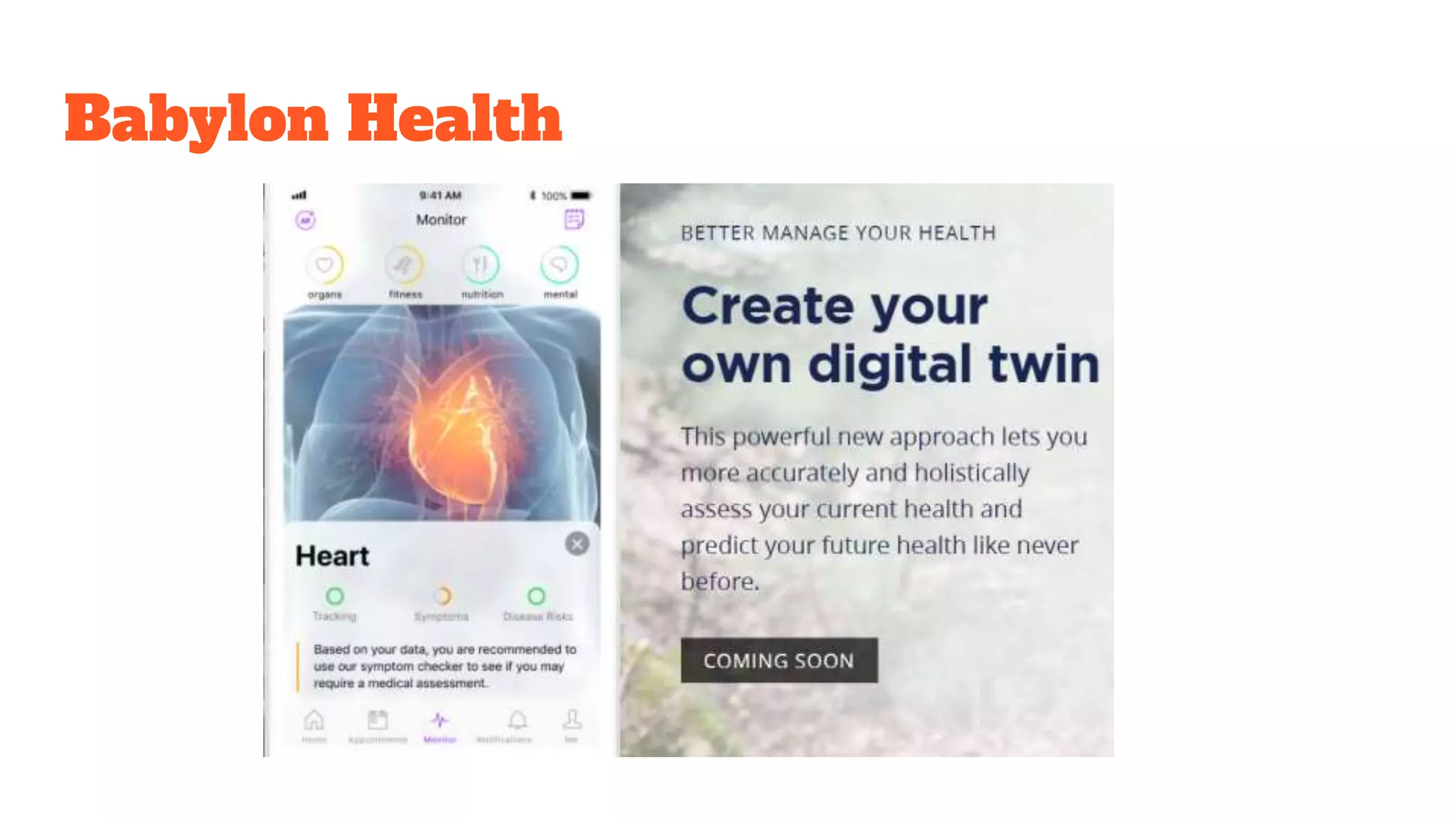
Discusses the future of disease prediction through wearable technology, digital twins, and challenges in data utilization.































![PPT-HEART-DISEASE[1].pptx presentationss](https://cdn.slidesharecdn.com/ss_thumbnails/ppt-heart-disease1-250901140846-bb7a7155-thumbnail.jpg?width=640&height=640&fit=bounds)










































