







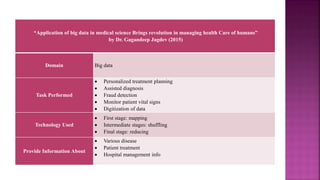
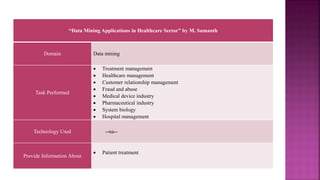
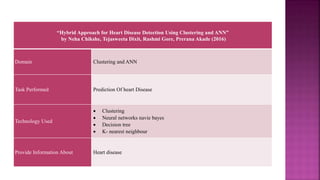









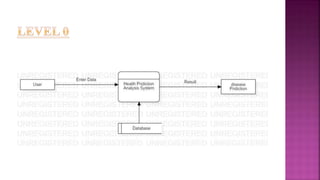
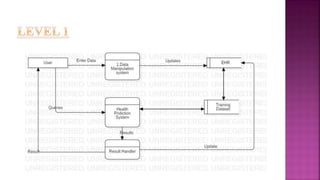
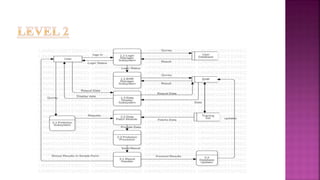
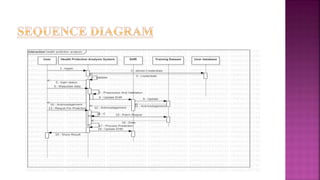





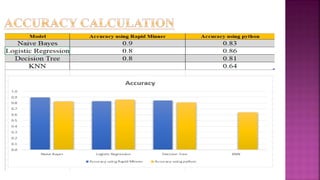





The document presents a project on health prediction analysis using data mining, highlighting the necessity and benefits of data mining in healthcare, such as preventing epidemics and reducing treatment costs. It discusses various applications including personalized treatment planning, disease prediction, and hospital management, while detailing the algorithms and technologies used in implementing the project. The ultimate goal is to develop a model that predicts patient health status from electronic health records, thereby improving diagnosis and treatment decisions.





























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)





