Downloaded 80 times









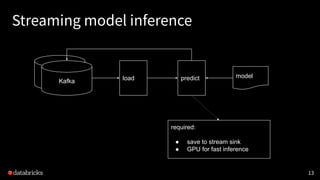




















![37
Retrieve assigned GPUs
User can retrieve assigned GPUs from task context (#24374)
context = TaskContext.get()
assigned_gpu = context.getResources()[“gpu”][0]
with tf.device(assigned_gpu):
# training code ...](https://image.slidesharecdn.com/032001xiangruimeng-190513184402/85/Updates-from-Project-Hydrogen-Unifying-State-of-the-Art-AI-and-Big-Data-in-Apache-Spark-37-320.jpg)





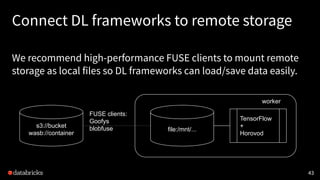


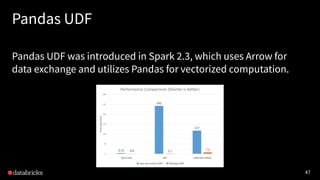


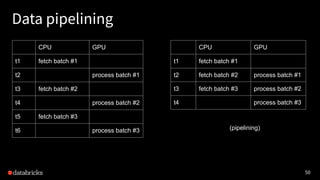







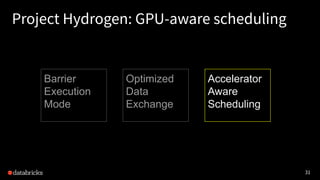
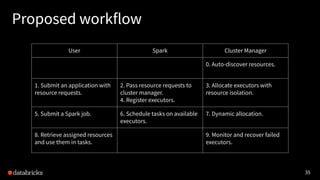
Project Hydrogen aims to integrate state-of-the-art AI and big data workloads using Apache Spark, fostering distributed training and efficient data exchange. It introduces features like barrier execution mode, accelerator-aware scheduling, and optimized data exchange to enhance Spark's capabilities for machine learning scenarios. Collaborations with frameworks like Horovod are underway to improve integration, streamline workflows, and leverage GPU resources effectively.























































































