Download as PDF, PPTX






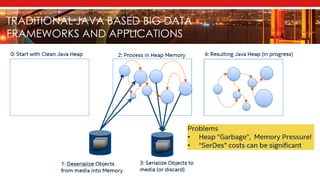

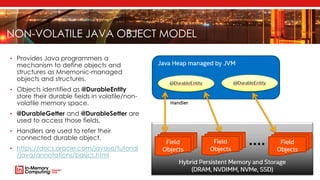

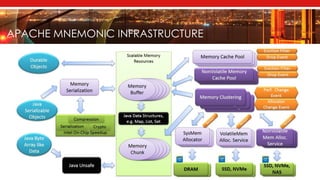
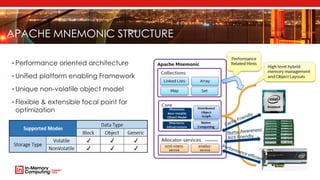

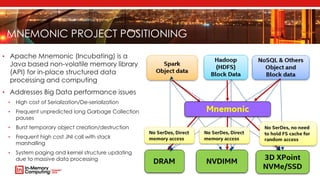


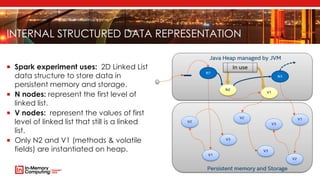
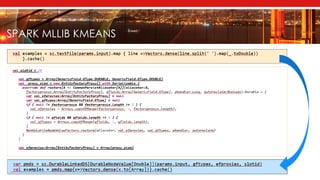





The document introduces Apache Mnemonic, a non-volatile programming model aimed at improving in-memory computing performance for Java applications by leveraging advanced storage media. It focuses on creating a non-volatile object model that allows Java programmers to manage data in place, minimizing serialization costs and improving performance in big data frameworks like Spark. The document also outlines practical use cases and provides insights into performance improvements, particularly in machine learning applications.























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)



