Download as PDF, PPTX


















![Policy Gradients
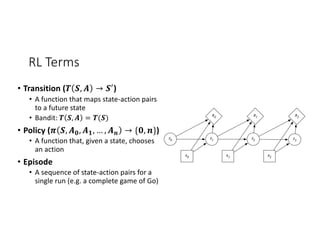
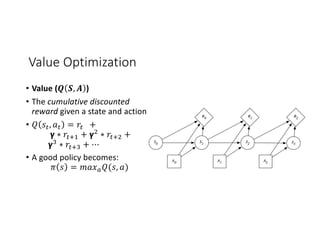
• Q-Learning: 𝑄 𝑠G, 𝑎G = 𝑟G + 𝛾 ∗ 𝑚𝑎𝑥" GM. [𝑄 𝑠GM., 𝑎GM. ]
• What if we can’t do 𝑚𝑎𝑥" GM. [… ]?
• Policy Gradient
• Approximate 𝑚𝑎𝑥" GM. [𝑄 𝑠GM., 𝑎GM. ]
• 𝑄 𝑠G, 𝑎G = 𝑟G + 𝛾 ∗ 𝐴 𝑠GM.
• Learn 𝐴 𝑠GM. assuming Q is perfect:
• Deep Deterministic Policy Gradient
• 𝐿 𝐴 𝑠GM. = min(−𝑄 𝑠GM., 𝑎GM. )
• Soft Actor Critic
• 𝐿 𝐴 𝑠GM. = min(log(𝑃(𝐴 𝑠GM. = 𝑎GM.)) − 𝑄 𝑠GM., 𝑎GM. )](https://image.slidesharecdn.com/012002jasongauci-190506222402/85/Horizon-Deep-Reinforcement-Learning-at-Scale-24-320.jpg)










The document discusses the application of deep reinforcement learning (RL) in large-scale recommender systems, highlighting its importance in various control aspects such as retrieval, event prediction, and ranking. It introduces a framework for recommendation, emphasizing the significance of learning value functions and optimizing metrics using RL principles. It also covers the implementation strategies and challenges of deploying personalized RL models to billions of users through platforms like Horizon, which utilize distributed training and counterfactual policy evaluation.























































































