Download as PDF, PPTX








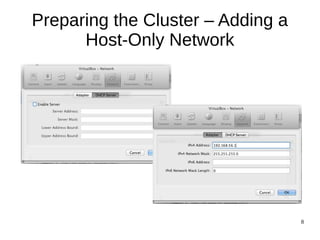

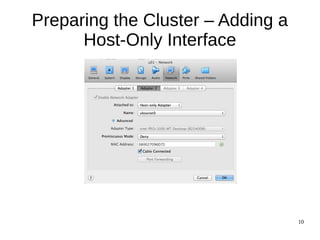

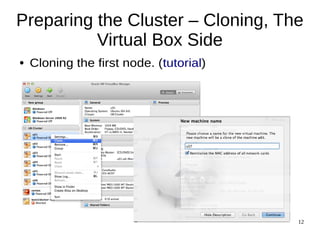





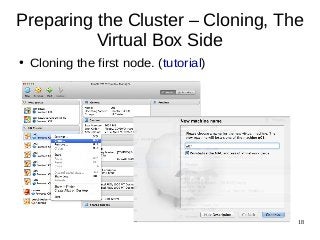






This document provides an overview of a workshop on setting up a Linux cluster using VirtualBox to try distributed data processing frameworks like Elasticsearch and Apache Hadoop. The workshop will involve preparing the cluster by installing Linux, configuring networking, cloning virtual machines, setting up password-less login, and installing tools to manage the cluster remotely. Future sessions will provide introductions to Elasticsearch for log management and search and Apache Hadoop for distributed data processing and hands-on exercises to use these tools on the cluster.






































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)










