Download as PDF, PPTX





















![Recipes:
HDFS Block Size (2/3)
● Option 2: During file upload
○ Applies only to the specific file paths
> bin/hadoop fs -Ddfs.blocksize=134217728 -put data.in /user/foo
● Use fsck command
> bin/hadoop fsck /user/foo/data.in -blocks -files -locations
/user/foo/data.in 215227246 bytes, 2 block(s): ....
0. blk_6981535920477261584_1059len=134217728 repl=1 [hostname:50010]
1. blk_-8238102374790373371_1059 len=81009518 repl=1 [hostname:50010]](https://image.slidesharecdn.com/hadoopoperations-basic-130808235007-phpapp02/85/Hadoop-operations-basic-29-320.jpg)


![Recipes:
File Replication Factor (3/3)
● Set replication factor during file upload
> bin/hadoop fs -D dfs.replication=1 -copyFromLocal non-criticalfile.txt
/user/foo
● Change the replication factor of files or file
paths that are already in the HDFS
○ Use setrep command
○ Syntax: hadoop fs -setrep [-R] <path>
> bin/hadoop fs -setrep 2 non-critical-file.txt
Replication 3 set: hdfs://myhost:9000/user/foo/non-critical-file.txt](https://image.slidesharecdn.com/hadoopoperations-basic-130808235007-phpapp02/85/Hadoop-operations-basic-32-320.jpg)
![Recipes:
Merging files in HDFS
● Use HDFS getmerge command
● Syntax:
hadoop fs -getmerge <src> <localdst> [addnl]
● Copies files in a given path in HDFS to a
single concatenated file in the local
filesystem
> bin/hadoop fs -getmerge /user/foo/demofiles merged.txt](https://image.slidesharecdn.com/hadoopoperations-basic-130808235007-phpapp02/85/Hadoop-operations-basic-33-320.jpg)





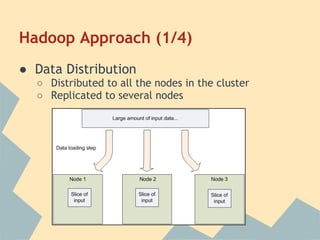
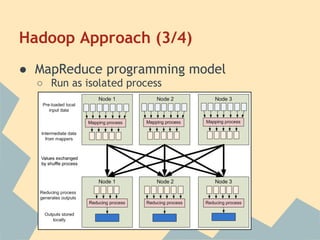
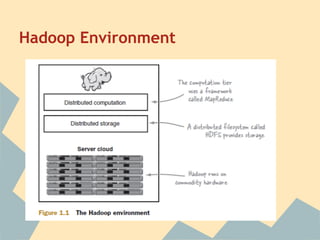
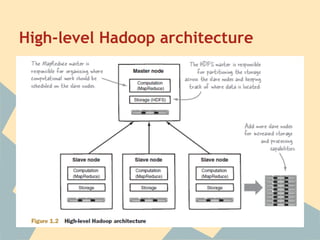
This document provides an overview of Hadoop, including its architecture, installation, configuration, and commands. It describes the challenges of large-scale data that Hadoop addresses through distributed processing and storage across clusters. The key components of Hadoop are HDFS for storage and MapReduce for distributed processing. HDFS stores data across clusters and provides fault tolerance through replication, while MapReduce allows parallel processing of large datasets through a map and reduce programming model. The document also outlines how to install and configure Hadoop in pseudo-distributed and fully distributed modes.



































































