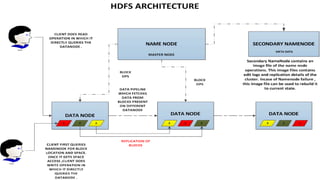
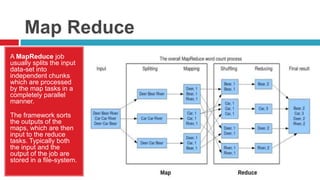
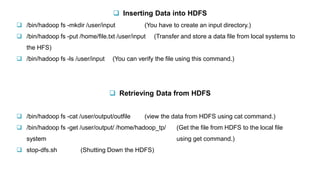
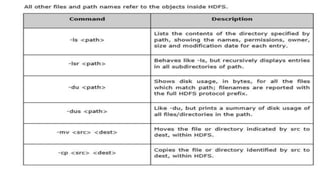
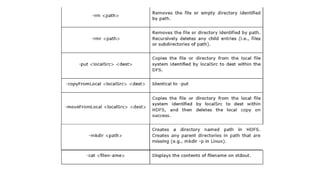
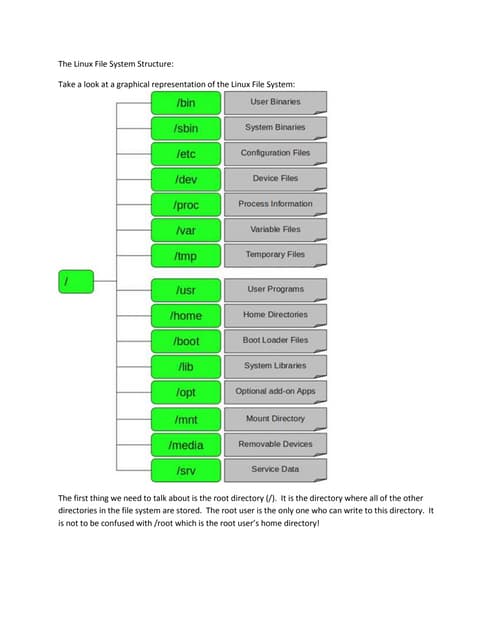
Hadoop is a framework for distributed processing of large datasets across clusters of computers using a simple programming model. It provides reliable storage through HDFS and processes large amounts of data in parallel through MapReduce. The document discusses installing and configuring Hadoop on Windows, including setting environment variables and configuration files. It also demonstrates running a sample MapReduce wordcount job to count word frequencies in an input file stored in HDFS.