Downloaded 60 times







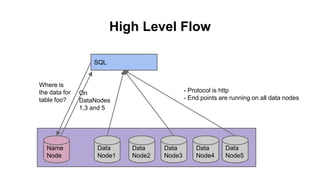

![PXF Architecture
HAWQ
Master
M/R,
Pig,
Hive
Data Node
Container with End-Points
PXF Fragmenter
Local HDFS
Hadoop
Pivotal Green
Zookeeper
3
1
6
PSQL
select * from external table foo
location=”pxf://namenode:50070/financedata”
0
splits[..]
HAWQ
Segment
getSplit(0)
PXFWritable
A
B
0 6To
A BTo
MetaData
Data
Native
PHD
5
4
PXF Accessor/Resolver
Local HDFS
2](https://image.slidesharecdn.com/accessingexternalhadoopdatasourcesusingpivotalextensionframeworkpxf-noanimation-140409012344-phpapp02/85/Accessing-external-hadoop-data-sources-using-pivotal-e-xtension-framework-pxf-no-animation-17-320.jpg)
![Classes
• The four major components are defined as interfaces and
base classes that can be extended. e.g. Fragmenter
/*
* Class holding information about fragments (FragmentInfo)
*/
public class FragmentsOutput {
public FragmentsOutput();
public void addFragment(String sourceName, String[] replicas, byte[] metadata );
public void addFragment(String sourceName, String[] replicas, byte[] metadata,
String userData);
public List<FragmentInfo> getFragments();
}](https://image.slidesharecdn.com/accessingexternalhadoopdatasourcesusingpivotalextensionframeworkpxf-noanimation-140409012344-phpapp02/85/Accessing-external-hadoop-data-sources-using-pivotal-e-xtension-framework-pxf-no-animation-18-320.jpg)











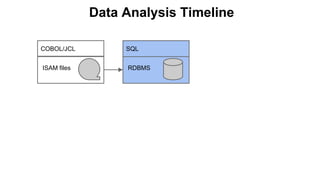
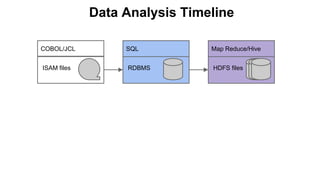
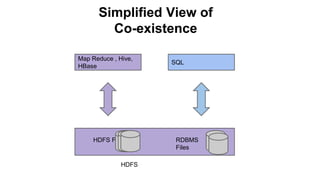
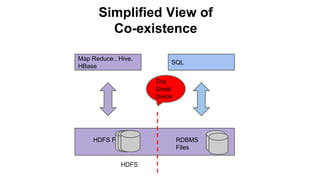
The Pivotal eXtension Framework (PXF) allows SQL queries to access data stored in various data stores like HDFS, HBase, Hive, and others. PXF uses a pluggable architecture with components like a fragmenter, accessor, resolver, and analyzer that can be extended to connect to new data sources. It addresses the divide between SQL and MapReduce/Hive by enabling SQL queries to retrieve data without needing to copy it to the database first. PXF provides a single hop access to external data and fully parallel processing for high throughput queries across data stores.



































































