Downloaded 46 times











































































![ReadFile.java Example
public class ReadFile {
public static void main(String[] args) throws IOException {
Path fileToRead = new Path("/user/sample/sonnets.txt");
FileSystem fs = FileSystem.get(new Configuration()); // 1: Open FileSystem
InputStream input = null;
try {
input = fs.open(fileToRead); // 2: Open InputStream
IOUtils.copyBytes(input, System.out, 4096); // 3: Copy from Input to Output
} finally {
IOUtils.closeStream(input); // 4: Close stream
}
}
}
$ yarn jar my-hadoop-examples.jar hdfs.ReadFile
82](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-81-320.jpg)


![SeekReadFile.java Example
public class SeekReadFile {
public static void main(String[] args) throws IOException {
Path fileToRead = new Path("/user/sample/readMe.txt");
FileSystem fs = FileSystem.get(new Configuration());
FSDataInputStream input = null;
try {
input = fs.open(fileToRead);
System.out.print("start postion=" + input.getPos() + ": ");
IOUtils.copyBytes(input, System.out, 4096, false);
input.seek(11);
System.out.print("start postion=" + input.getPos() + ": ");
IOUtils.copyBytes(input, System.out, 4096, false);
input.seek(0);
System.out.print("start postion=" + input.getPos() + ": ");
IOUtils.copyBytes(input, System.out, 4096, false);
} finally {
IOUtils.closeStream(input);
}
}
}
85](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-84-320.jpg)


![WriteToFile.java Example
public class WriteToFile {
public static void main(String[] args) throws IOException {
String textToWrite = "Hello HDFS! Elephants are awesome!n";
InputStream in = new BufferedInputStream(
new ByteArrayInputStream(textToWrite.getBytes()));
Path toHdfs = new Path("/user/sample/writeMe.txt");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf); // 1: Create FileSystem instance
FSDataOutputStream out = fs.create(toHdfs); // 2: Open OutputStream
IOUtils.copyBytes(in, out, conf); // 3: Copy Data
}
}
88](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-87-320.jpg)




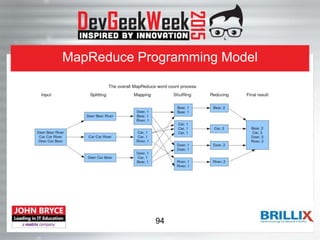














![1: Configure Job - Specify Input
TextInputFormat.addInputPath(job, new Path(args[0]));
job.setInputFormatClass(TextInputFormat.class);
• Can be a file, directory or a file pattern
– Directory is converted to a list of files as an input
• Input is specified by implementation of InputFormat - in this
case TextInputFormat
– Responsible for creating splits and a record reader
– Controls input types of key-value pairs, in this case LongWritable
and Text
– File is broken into lines, mapper will receive 1 line at a time
112](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-110-320.jpg)

![1: Configure Job – Specify Output
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputFormatClass(TextOutputFormat.class);
• OutputFormat defines specification for outputting data from
Map/Reduce job
• Count job utilizes an implemenation of
OutputFormat - TextOutputFormat
– Define output path where reducer should place its output
• If path already exists then the job will fail
– Each reducer task writes to its own file
• By default a job is configured to run with a single reducer
– Writes key-value pair as plain text
114](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-112-320.jpg)




![1: Configure Count Job
public class StartsWithCountJob extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "StartsWithCount");
job.setJarByClass(getClass());
// configure output and input source
TextInputFormat.addInputPath(job, new Path(args[0]));
job.setInputFormatClass(TextInputFormat.class);
// configure mapper and reducer
job.setMapperClass(StartsWithCountMapper.class);
job.setCombinerClass(StartsWithCountReducer.class);
job.setReducerClass(StartsWithCountReducer.class);
119](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-117-320.jpg)
![StartsWithCountJob.java (cont.)
// configure output
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(
new StartsWithCountJob(), args);
System.exit(exitCode);
}
}
120](https://image.slidesharecdn.com/dgwhadoopecosystemengv4-150706181703-lva1-app6891/85/The-Hadoop-Ecosystem-for-Developers-118-320.jpg)






































































































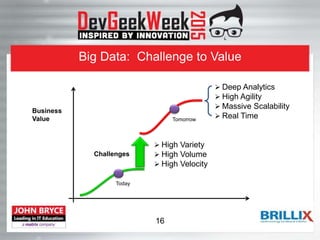
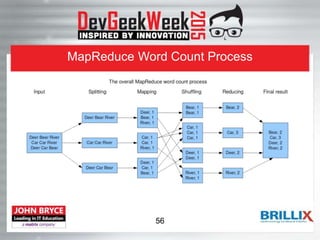
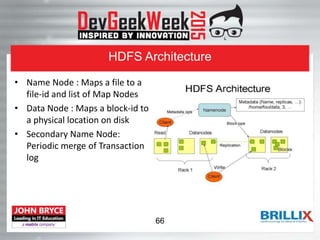
This document provides an overview of the Hadoop ecosystem. It begins with introducing big data challenges around volume, variety, and velocity of data. It then introduces Hadoop as an open-source framework for distributed storage and processing of large datasets across clusters of computers. The key components of Hadoop are HDFS (Hadoop Distributed File System) for distributed storage and high throughput access to application data, and MapReduce as a programming model for distributed computing on large datasets. HDFS stores data reliably using data replication across nodes and is optimized for throughput over large files and datasets.





































































































