Download as PDF, PPTX



































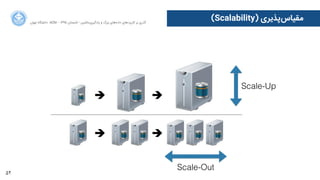
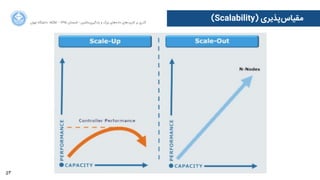





![76
ﺍاﻥنﺮﺗﻬ ﺩدﺍاﻧﺸﮕﺎﻩه ACM - ۱۳۹۵ ﺗﺎﺑﺴﺘﺎﻥن - ﻣﺎﺷﯿﻦﯼیﯾﺎﺩدﮔﯿﺮ ﻭو ﺑﺰﺭرﮒگ ﻫﺎﯼیﻩهﺩدﺍاﺩد ﻫﺎﯼیﺩدﮐﺎﺭرﺑﺮ ﺑﺮ ﮔﺬﺭرﯼی
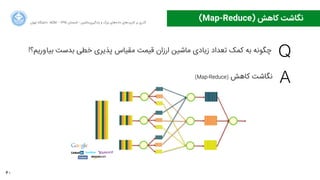
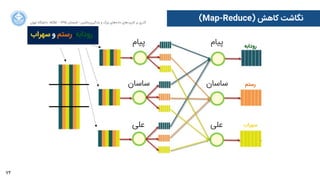
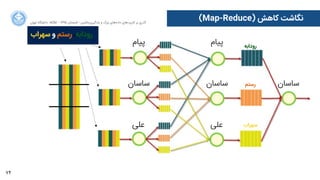
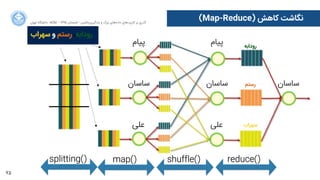
(Map-Reduce) ﮐﺎﻫﺶ ﻧﮕﺎﺷﺖ
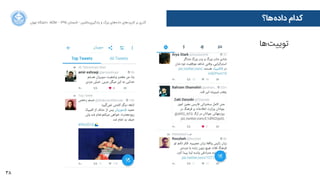
ﭘﯿﺎﻡم
ﺳﺎﺳﺎﻥن
ﻋﻠﯽ
ﭘﯿﺎﻡم
ﺳﺎﺳﺎﻥن
ﻋﻠﯽ
ﺳﻬﺮﺍاﺏب ﻭو ﺭرﺳﺘﻢ ،ﺭرﻭوﺩدﺍاﺑﻪ
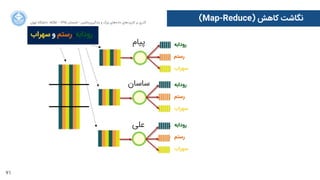
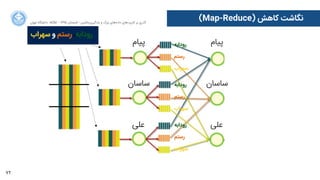
ﭘﯿﺎﻡم
ﺳﺎﺳﺎﻥن
ﻋﻠﯽ
ﺭرﻭوﺩدﺍاﺑﻪ
ﺭرﺳﺘﻢ
ﺳﻬﺮﺍاﺏب
ﺳﺎﺳﺎﻥن
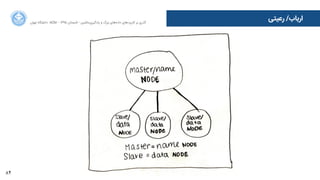
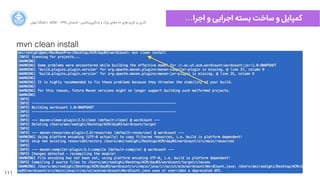
map() shuffle() reduce()
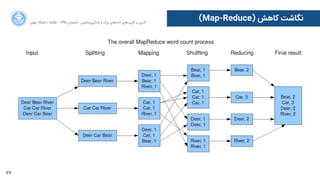
[k1,v1] by k1 [k1,[v1, v2, v3 …]]](https://image.slidesharecdn.com/bigdataandmlcourse03-160817205653/85/Big-Data-and-Machine-Learning-Workshop-Day-3-UTACM-76-320.jpg)

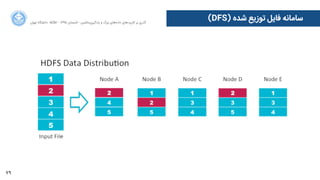
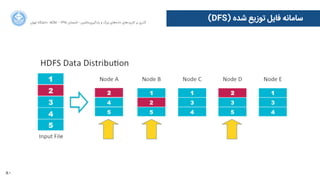
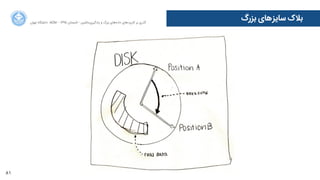

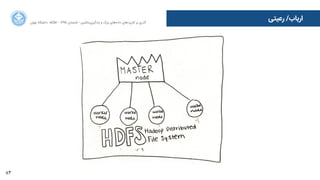


















![110
ﺟﺎﻭوﺍاﺍاﻥنﺮﺗﻬ ﺩدﺍاﻧﺸﮕﺎﻩه ACM - ۱۳۹۵ ﺗﺎﺑﺴﺘﺎﻥن - ﻣﺎﺷﯿﻦﯼیﯾﺎﺩدﮔﯿﺮ ﻭو ﺑﺰﺭرﮒگ ﻫﺎﯼیﻩهﺩدﺍاﺩد ﻫﺎﯼیﺩدﮐﺎﺭرﺑﺮ ﺑﺮ ﮔﺬﺭرﯼی
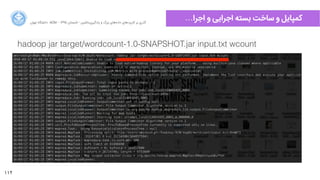
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
Complete WordCount.java](https://image.slidesharecdn.com/bigdataandmlcourse03-160817205653/85/Big-Data-and-Machine-Learning-Workshop-Day-3-UTACM-110-320.jpg)



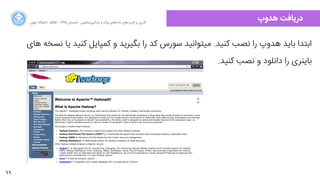
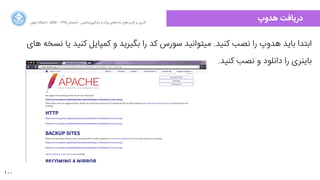
اسلاید سومین روز از کارگاه ۷ روزه دادههای بزرگ و یادگیری ماشین با معرفی راهکارهای متن باز پردازش دادههای بزرگ و راهحلهای پردازش جریانداده برگزار شد. مفاهیم مورد بررسی قرار گرفت. یک نمونه کوچک اجرایی از بهره گیری هدوپ ارائه شد. این دوره به همت ایسیام دانشگاه تهران برگزار میشود زمان هر جلسه ۲ ساعت است






![[논문발표] 20160725 A Random Walk Around the City: New Venue Recommendation in Lo...](https://cdn.slidesharecdn.com/ss_thumbnails/20160725arandomwalkaroundthecity-160726112403-thumbnail.jpg?width=640&height=640&fit=bounds)




































