Download to read offline



![What is
Algorithm ?
1. Cormen et al. (2001), Introduction to Algorithms
An algorithm is any well-defined
computational procedure that takes
some value, or set of values, as input
and produces some value, or set of
values as output.[1]
Example: Price monitoring algorithms,
recommendation algorithms, and
price-setting algorithms.](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-3-320.jpg)
![What is Bias ?
Presence of any prejudice or favoritism
toward an individual or a group based on their
inherent or acquired characteristics [1].
Example: A search word "nurse" in google
shows picture of women as nurse.
1. Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman and Aram Galstyan. “A
Survey on Bias and Fairness in Machine Learning”, arXiv:1908.09635v2 [cs.LG], 2019.](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-4-320.jpg)
![EXAMPLES OF BIASES
• Bias in online forecaster tools to
reoffend [1]
1. Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. 2016.
Machine Bias: There’s software used across the country to predict
future criminals. And it’s biased against blacks. ProPublica 2016.](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-5-320.jpg)
![Algorithmic
Bias
[1]Ricardo Baeza-Yates. 2018. Bias on the Web. Commun. ACM 61, 6 (May 2018), 54–61. https://doi.org/10.1145/3209581
Algorithmic bias is when the
bias is not present in the
input data and is added
purely by the algorithm [1].
Example : Price-fixing
algorithm, Biased robo-seller
algorithm](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-6-320.jpg)

![Messenger
- Humans agree to collude by
fixing the optimization
algorithm for their competing
products and use algorithms
to facilitate their collusion.
Categories of Algorithmic Bias
Fig. : Explicit coordination implemented or facilitated by algorithms [1]
1. CMA. Pricing Algorithms. October 2018. Available at https://www.icsa.org.uk/knowledge/governance-and-compliance/indepth/technical/pricing-algorithms](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-8-320.jpg)
![Messenger Model Example
Poster Cartel:
David Topkins and his co-conspirators
(Trol Ltd. In U.K.) adopted specific pricing
algorithms that collected competitors’
pricing information, with the goal of
coordinating changes to their pricing
strategies for the sale of posters on
Amazon Marketplace [1].
Fig. : Using different kind and sources of data to find the prices that improve
profits [2].
1. Michal S. Gal. Illegal pricing algorithms. Commun. ACM 62, 1 (December 2018), 18–20. DOI: https://doi.org/10.1145/3292515
2. Javier Couto. How Machine Learning is reshaping Price Optimization. 2018. Available at https://tryolabs.com/blog/price-optimization-machine-learning/
Categories of Algorithmic Bias](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-9-320.jpg)
![Hub and Spoke
• Same algorithm or data pool
Categories of Algorithmic Bias
1. CMA. Pricing Algorithms. October 2018. Available at https://www.icsa.org.uk/knowledge/governance-and-compliance/indepth/technical/pricing-algorithms
2.Sam Schechner, Why Do Gas Station Prices Constantly Change? Blame the Algorithm, WALL ST. J. (May 8, 2017), https://www.wsj.com/articles/why-do-gas-station-prices-constantly-changeblame-
the-algorithm-1494262674 [https://perma.cc/UR8H-KX8E].
• Common intermediary [2]
Fig. : Tacit coordination due to common pricing algorithms [1]. Fig. : Tacit coordination due to common intermediary [1].](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-10-320.jpg)
![Hub and Spoke Model Example
Fig. : Eturas hub-and-spoke using one hub [1] Fig. : Hub-and-spoke using same third-party algorithm [2]
1.Steptoe & Johnson LLP. Cartel Liability in the Online Space Requires More Than a Sent E-mail. 2016. Available at https://www.steptoe.com/en/news-publications/cartel-liability-in-the-online-space-requires-more-than-a-sent-e-mail.html
2.Sam Schechner, Why Do Gas Station Prices Constantly Change? Blame the Algorithm, WALL ST. J. (May 8, 2017), https://www.wsj.com/articles/why-do-gas-station-prices-constantly-changeblame-the-algorithm-1494262674 [https://perma.cc/UR8H-KX8E].
Categories of Algorithmic Bias](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-11-320.jpg)
![Predictive Agents
– where humans program their
optimization algorithms to
monitor and respond to rivals’
outcome (e.g. pricing) and other
keys terms of sale, and they
know that the likely outcome
will be conscious parallelism and
higher gain (e.g. gain in prices).
"Conscious Parallelism"
Categories of Algorithmic Bias
Fig. : Process of defining prices in retail with price optimization using
Machine Learning [1].
1. Javier Couto. How Machine Learning is reshaping Price Optimization. 2018. Available at https://tryolabs.com/blog/price-optimization-machine-learning/](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-12-320.jpg)
![Predictive Agents Model
1. Freshfields Bruckhaus Deringer LLP, “Pricing algorithms: the digital collusion scenarios”. 2017. Available at https://www.freshfields.com/digital/
2.Competition and Markets Authority (2016), CMA issues final decision in online cartel case. Available at https://www.gov.uk/government/news/cma-issues-final-decision-in-online-cartel-case
Fig. : Tacit coordination without agreement
between rival companies [1].
Fig. : Tacit coordination without agreement between firm and
algorithms but responding fast with the market change [2].
Categories of Algorithmic Bias](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-13-320.jpg)
![Predictive Agents Model Scenario
Company
A
Collect
Price
pb
Set Price
pa = pb
Company
B
Collect
Price
pa
Set Price
pb = pa *
80%
Fig. : Company A collects Company B's price and sets its own price to match Company B. Company B also collects Company A's
price and sets its price 20% less [1].
1. Lee, Kenji, Algorithmic Collusion & Its Implications for Competition Law and Policy (April 12, 2018). Available at SSRN: https://ssrn.com/abstract=3213296 or http://dx.doi.org/10.2139/ssrn.3213296
Categories of Algorithmic Bias](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-14-320.jpg)
![Predictive Agents Model Example
Tacit collusion on Steroid result = $23,698,655.93
1. Michael Eisen. Amazon’s $23,698,655.93 book about flies. Available at https://blogs.berkeley.edu/2011/04/26/amazon%E2%80%99s-23698655-93-book-about-flies/
Fig. : The price of a biology textbook on Amazon Marketplace in 2011 [1]
Categories of Algorithmic Bias
Fig. : Pattern of price changes for the biology textbook on Amazon
Marketplace in 2011 [1]](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-15-320.jpg)

![Digital Eye Model
‘Win-Continue Lose-Reverse’ rule
Fig. : Reinforcement/Automated learning
between intelligent machine [2].
1. David Silver, Thomas Hubert, Julian Schrittwieser, nIoannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy P. Lillicrap, Karen Simonyan,
Demis Hassabis.Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. CoRR. 2017.
2. Freshfields Bruckhaus Deringer LLP, “Pricing algorithms: the digital collusion scenarios”. 2017. Available at https://www.freshfields.com/digital/
Categories of Algorithmic Bias
Fig. : AlphaZero by Google playing chess game using reinforcement learning [1]](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-17-320.jpg)
![Digital Eye Model
Example
Constraint: Trade-off "Higher price
and lower sale"
Goal : Meeting sales target/ specific
share of "Buy Box" Sale
Algorithm : Automated re-pricer
Data : Amazon seller’s past
pricing/profit/revenue data,
competing firms’ prices, and market
information [2]. Fig: Automated repricer algorithm outmaneuvering competitors [1,2]
1.Alexander Galkin. Marketplace Pricing or All You Must Know on Amazon Repricer; How to use Amazon repricer and why do you need it now? Available
at https://competera.net/resources/articles/amazon-repricer
2. Monica Axinte. Quick Introduction to Amazon Pricing Strategies. Available at https://www.datafeedwatch.com/blog/quick-introduction-to-amazon-pricing-strategies
Categories of Algorithmic Bias](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-18-320.jpg)
![Explainable AI
Fig. : LIME model explains the symptoms that in the patient ‘s history that led to
the prediction “flu “. Model explains that sneeze and headache are used as
contributing factor for the prediction and no fatigue was used against it. This
explanation helps doctor to trust the model’s prediction [1].
Local Interpretable Model-
agnostic Explanations
(LIME)[1] :
1. Marco Tulio Ribeiro,Sameer Singh, Carlos Guestrin, "Why Should I Trust You?": Explaining the Predictions of Any Classifier, CoRR, 2018](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-19-320.jpg)
![Figure : Explaining a prediction of classifiers to determine the class “Christianity” or “Atheism” based on text in documents.
The bar chart showing the importance on the words which determine the prediction. And highlighted in the document. Blue
color indicate “Atheism” and orange indicates “Christianity” [1].
1. Marco Tulio Ribeiro,Sameer Singh, Carlos Guestrin, "Why Should I Trust You?": Explaining the Predictions of Any Classifier, CoRR, 2018
Explainable AI](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-20-320.jpg)



![• A search (Q) from San Jose, CA (start node) to Tampa, FL (stop node).
• Total distance , value[f(x)] = 3049 miles ( A same search in google map provides 2797 miles)
• Route, x = : [ San Jose, CA => San Bernardino, CA => Tucson, AZ => Roswell, NM => Waco, TX =>
Vicksburg, MS => Valdosta, GA => Tampa, FL ]
Case Study 1: Detecting bias by Explaining the black box
Fig. : An instance of optimal class visualization](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-24-320.jpg)
![Unbiased: [ San Jose, CA => San Bernardino, CA => Tucson, AZ => Roswell, NM => Waco, TX => Vicksburg, MS
=> Valdosta, GA => Tampa, FL ]
Biased: [ San Jose, CA => San Bernardino, CA => Tucson, AZ => Roswell, NM => Wichita, MS => Saint Louis,
MO=> Tuscalosa, AL => Tampa, FL ]
Case Study 1: Detecting bias by Explaining the black box](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-25-320.jpg)

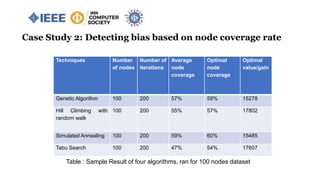
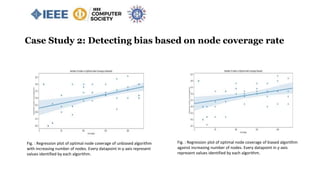
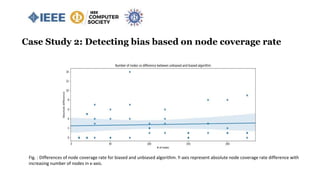
![Case Study 2: Detecting bias based on node coverage rate
Problem Definition:
Maximize 𝑖=1
𝑛
𝑣𝑖 𝑥𝑖
Subject to 𝑖=1
𝑛
𝑤𝑖 𝑥𝑖 ≤ 𝑊
Where 𝑣𝑖 is the value of item 𝑖, 𝑤𝑖 is the weight
of item 𝑖, and 𝑥𝑖 ∈ {0,1}
Knapsack 0/1 Test Case:
value = [4,2,10] and weight = [8,1,4], Total capacity W = 10
Unbiased result = 2+10=12
Biased result = 4+2=6
66% node coverage rate.
Fig. : Knapsack 0/1 Problem](https://image.slidesharecdn.com/anempiricalstudyonalgorithmicbiasaiml-compsac2020-200605195114/85/An-empirical-study-on-algorithmic-bias-aiml-compsac2020-27-320.jpg)





The document discusses algorithmic bias, its types, and examples, highlighting the role of algorithms in perpetuating bias in various domains such as pricing and hiring. It examines explicit and implicit biases, explores the implications of artificial intelligence, and showcases case studies to illustrate how algorithmic decisions can lead to unintended biases. The conclusion emphasizes the need for explainability in AI systems to ensure trust and ethical considerations in their implementation.























































































