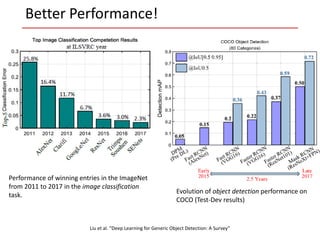
The document discusses the concept of robustness in deep learning, highlighting the vulnerability of current models to adversarial examples, which are slight perturbations designed to cause misclassifications. It reviews various attack strategies and models detailing how adversarial attacks are executed, including threat models and the challenges they pose in safety-critical applications. Additionally, the document emphasizes the need for improved defenses and evaluations of machine learning algorithms against adversarial attacks to ensure their reliability in real-world environments.