Download to read offline


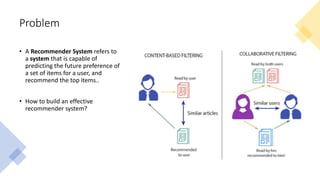
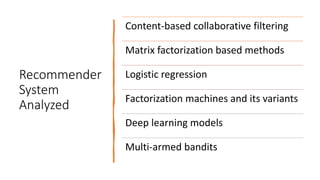
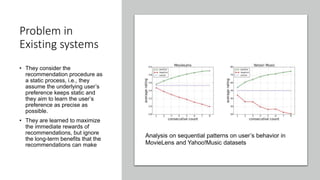

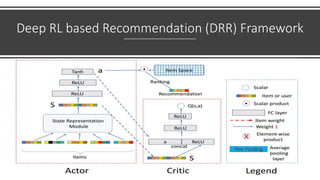

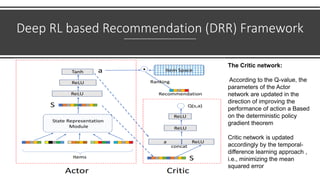






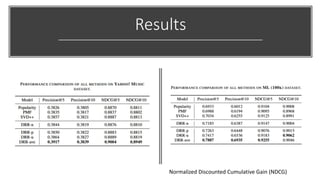




The document presents a deep reinforcement learning (DRL) framework for recommendation systems, addressing the limitations of existing methods that treat recommendations as static. The proposed DRL framework uses an actor-critic structure to optimize recommendations by considering both immediate and long-term rewards, incorporating user-item interactions and sequential decision-making processes. Experiments show that this approach outperforms traditional recommendation methods across various datasets.












































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










