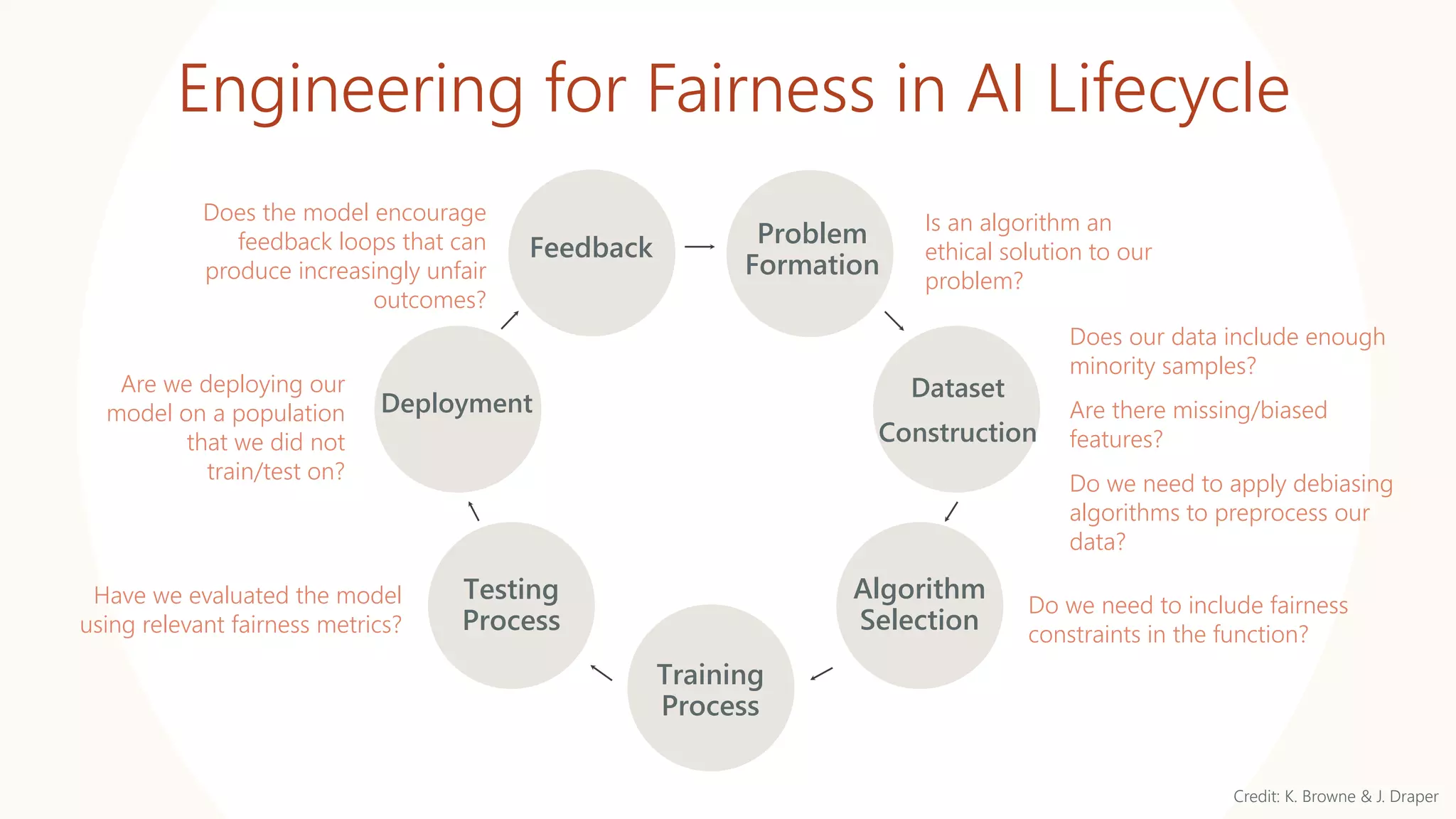
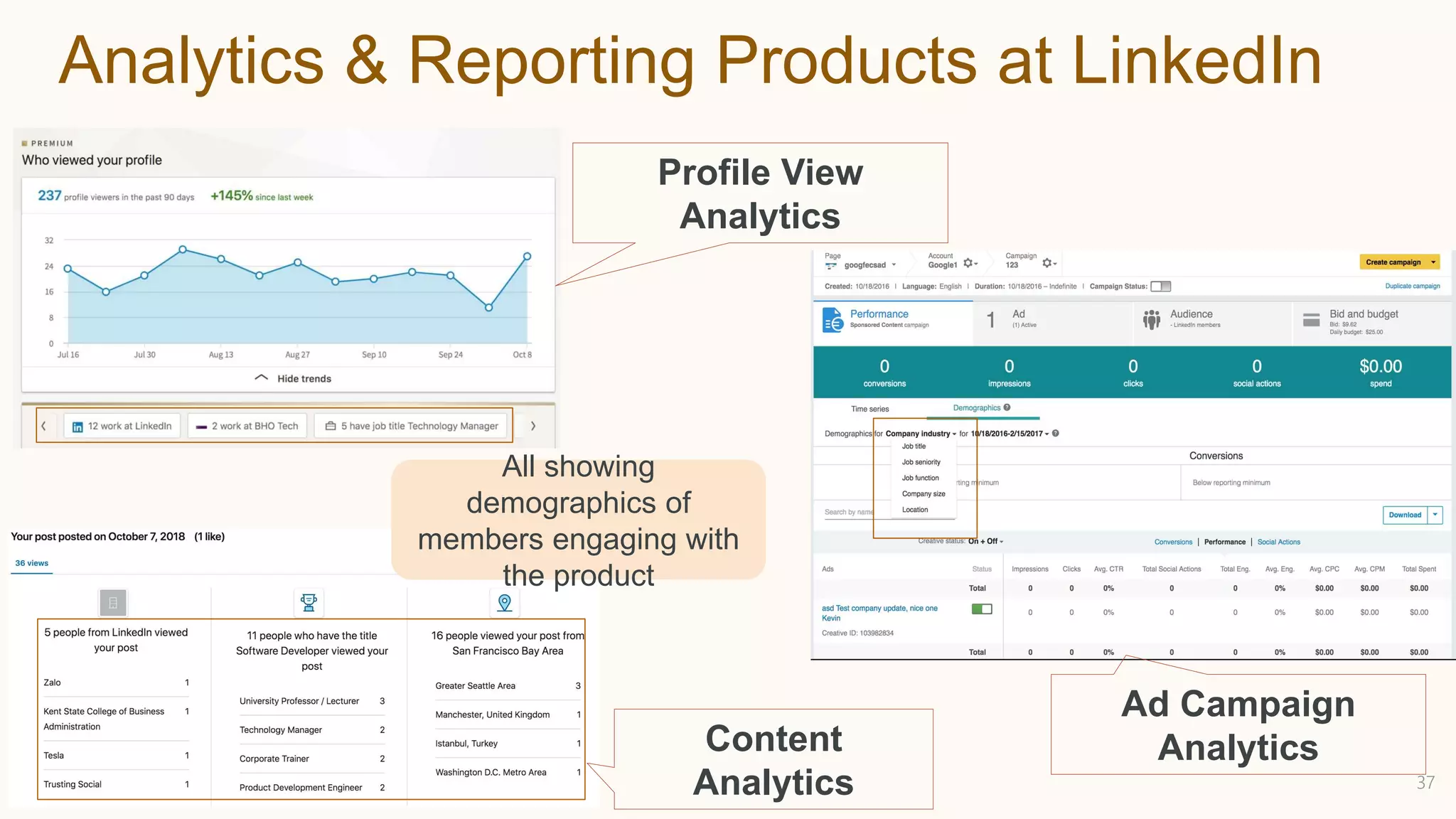
The document discusses fairness and privacy challenges in AI/ML systems, highlighting the consequences of algorithmic biases and the importance of integrating fairness and privacy by design. It illustrates initiatives taken by LinkedIn and AWS to promote diversity in talent search, along with the development of privacy-preserving analytics tools like Pripearl and secure salary data systems. The document emphasizes the need for collaboration among stakeholders to ensure ethical AI applications while addressing both business metrics and societal impacts.

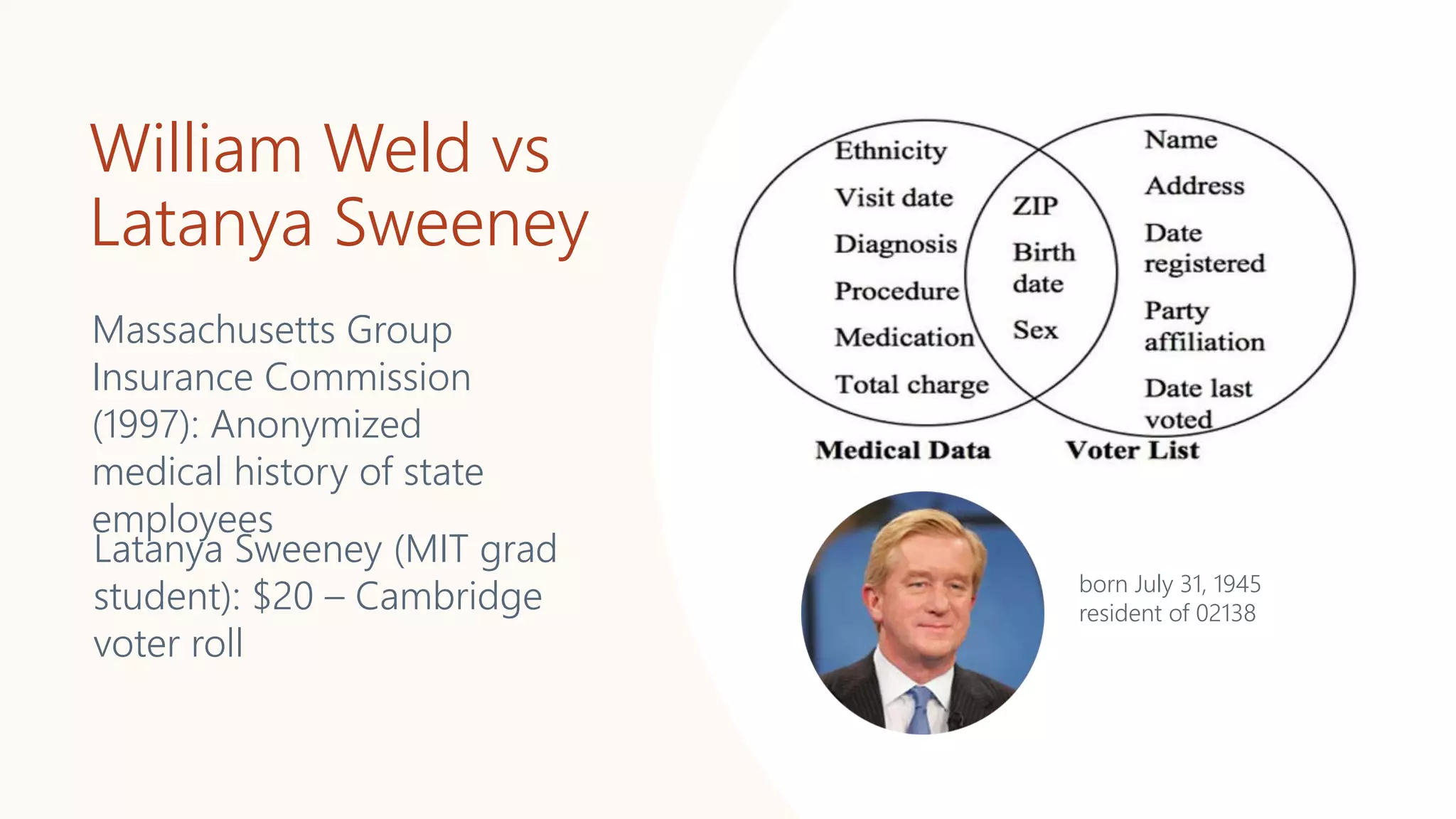
![The Coded Gaze [Joy Buolamwini 2016]
Face detection software: Fails for some darker faces
https://www.youtube.com/watch?v=KB9sI9rY3cA](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-4-2048.jpg)
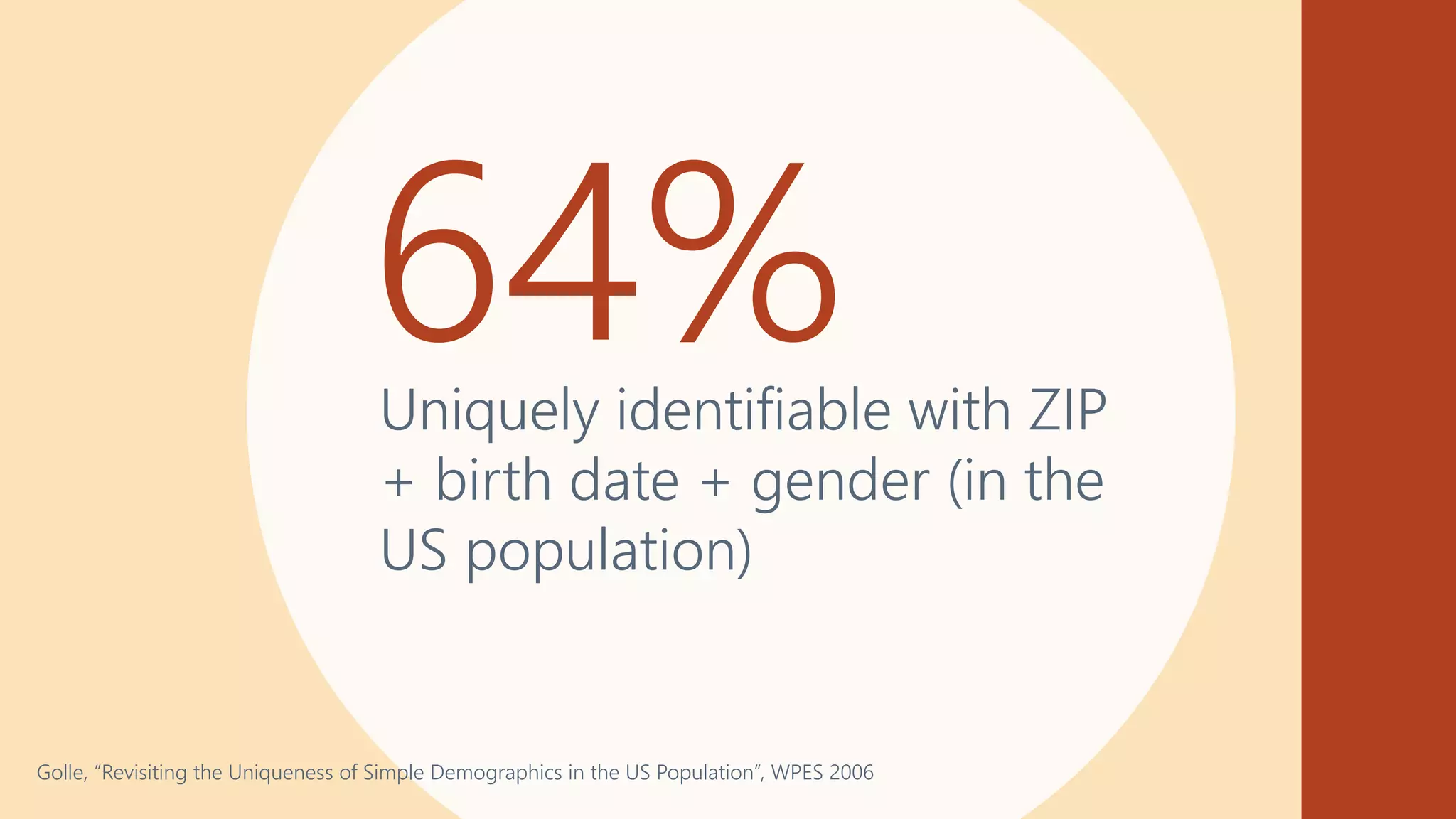
![• Facial analysis software:
Higher accuracy for light
skinned men
• Error rates for dark skinned
women: 20% - 34%
Gender Shades
[Joy Buolamwini &
Timnit Gebru,
2018]](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-5-2048.jpg)











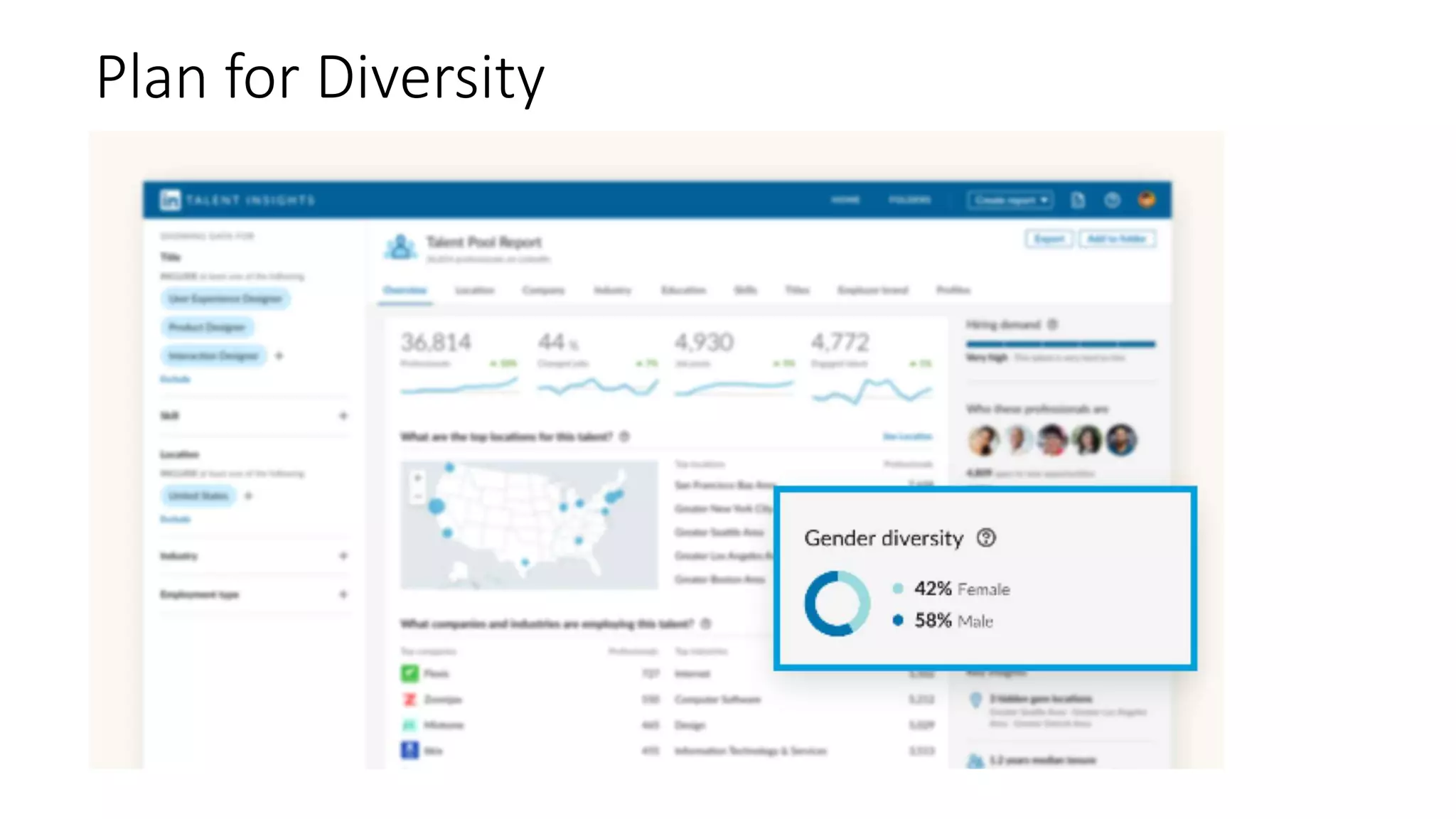
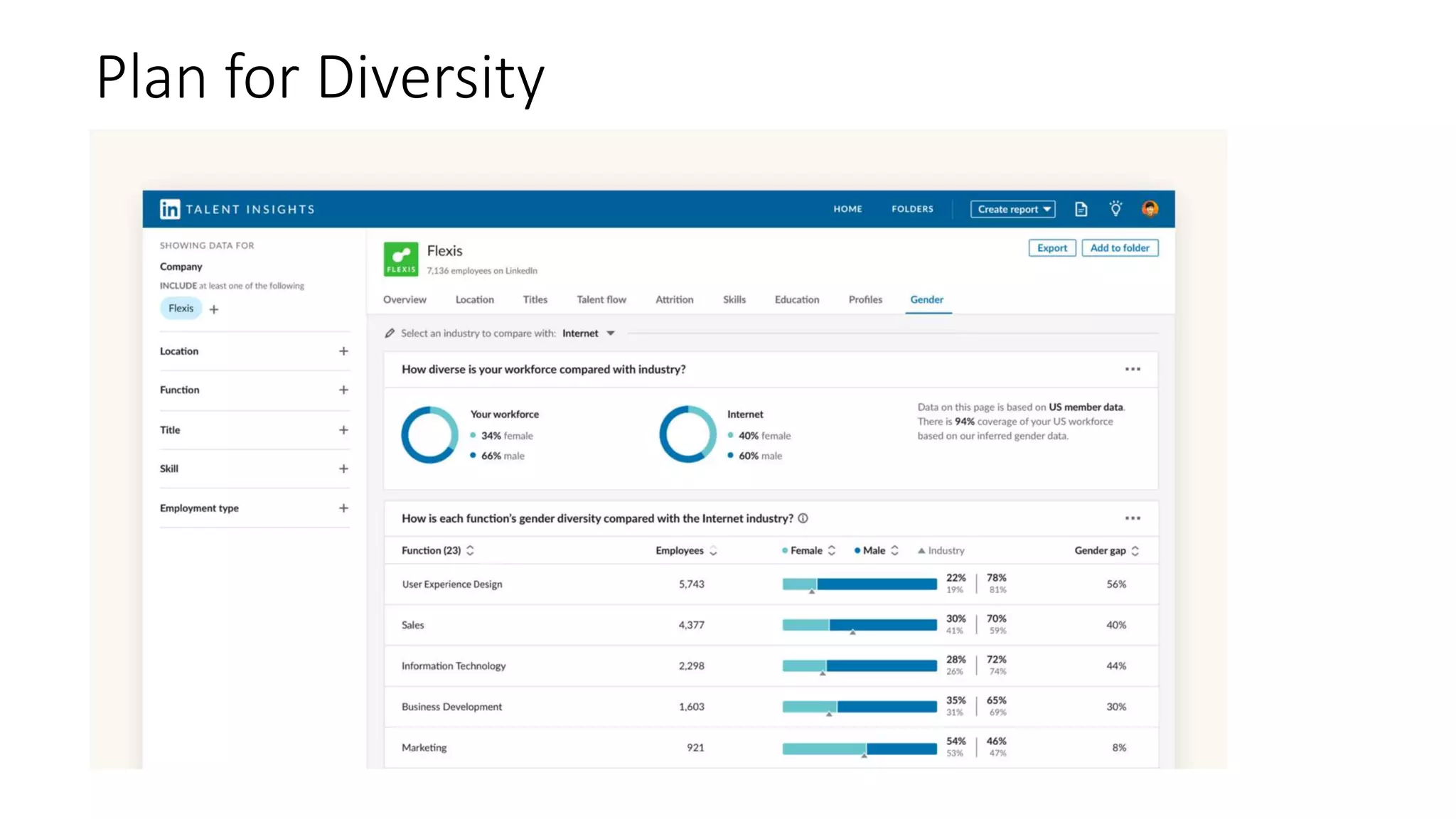
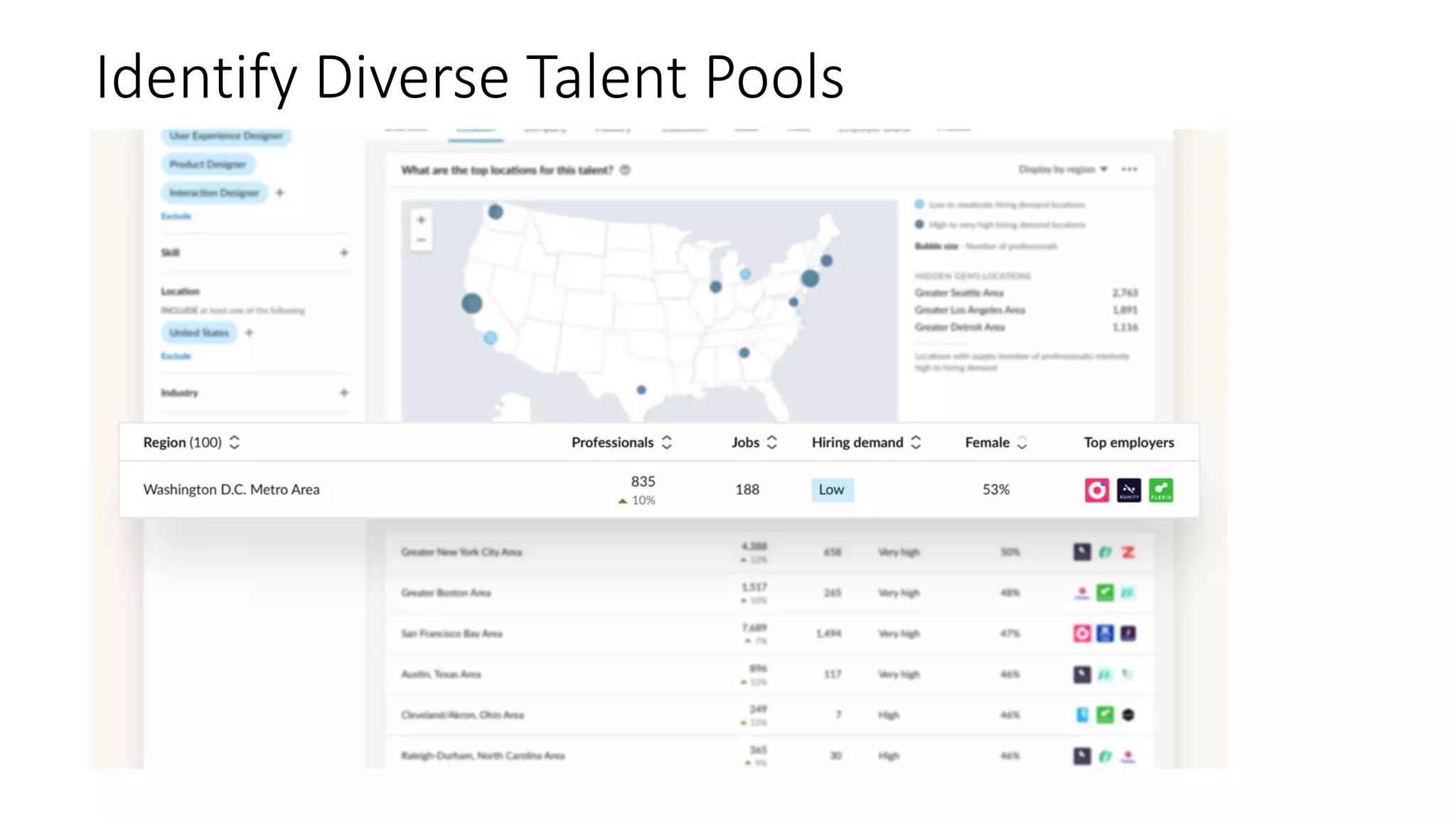
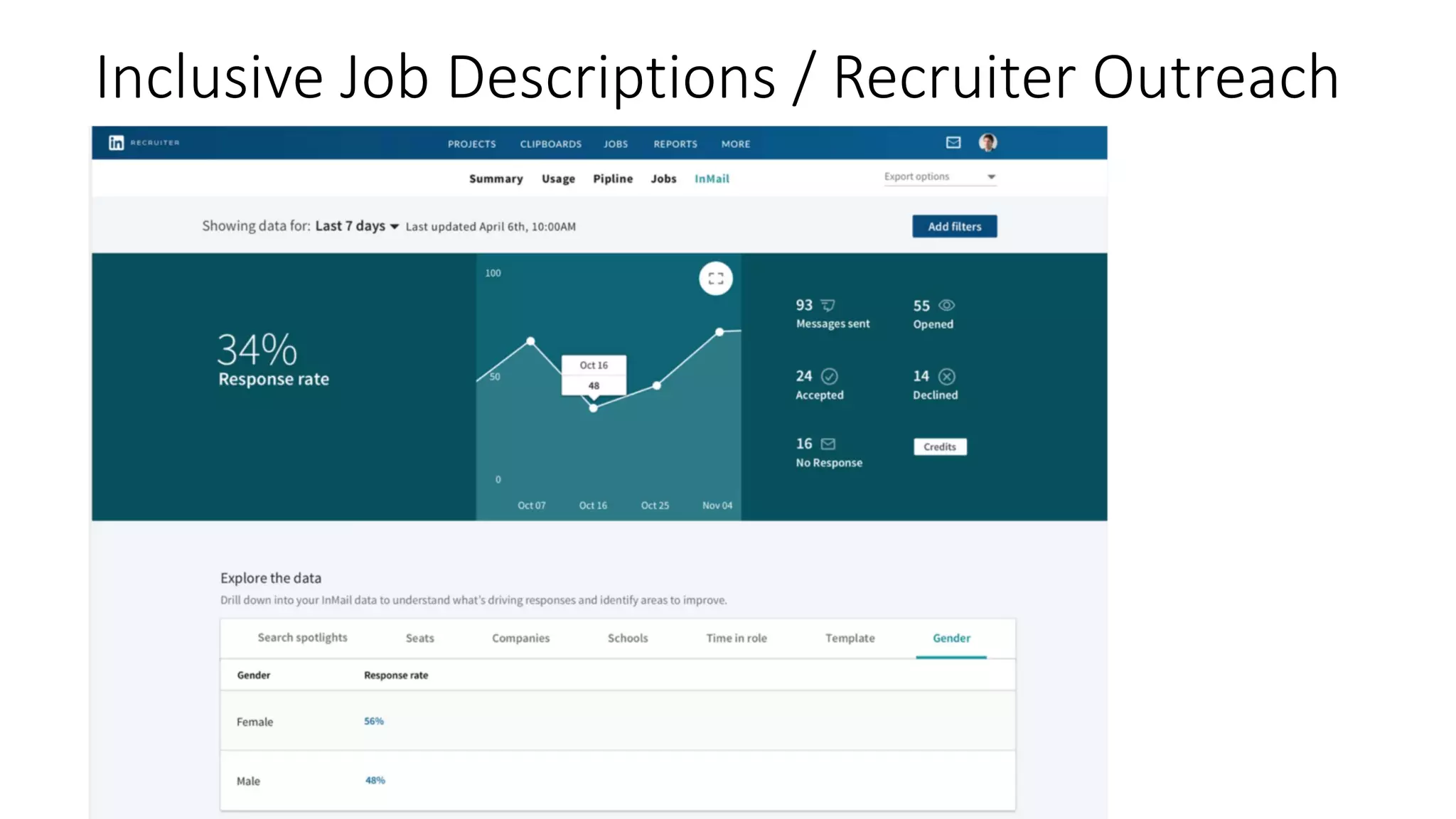
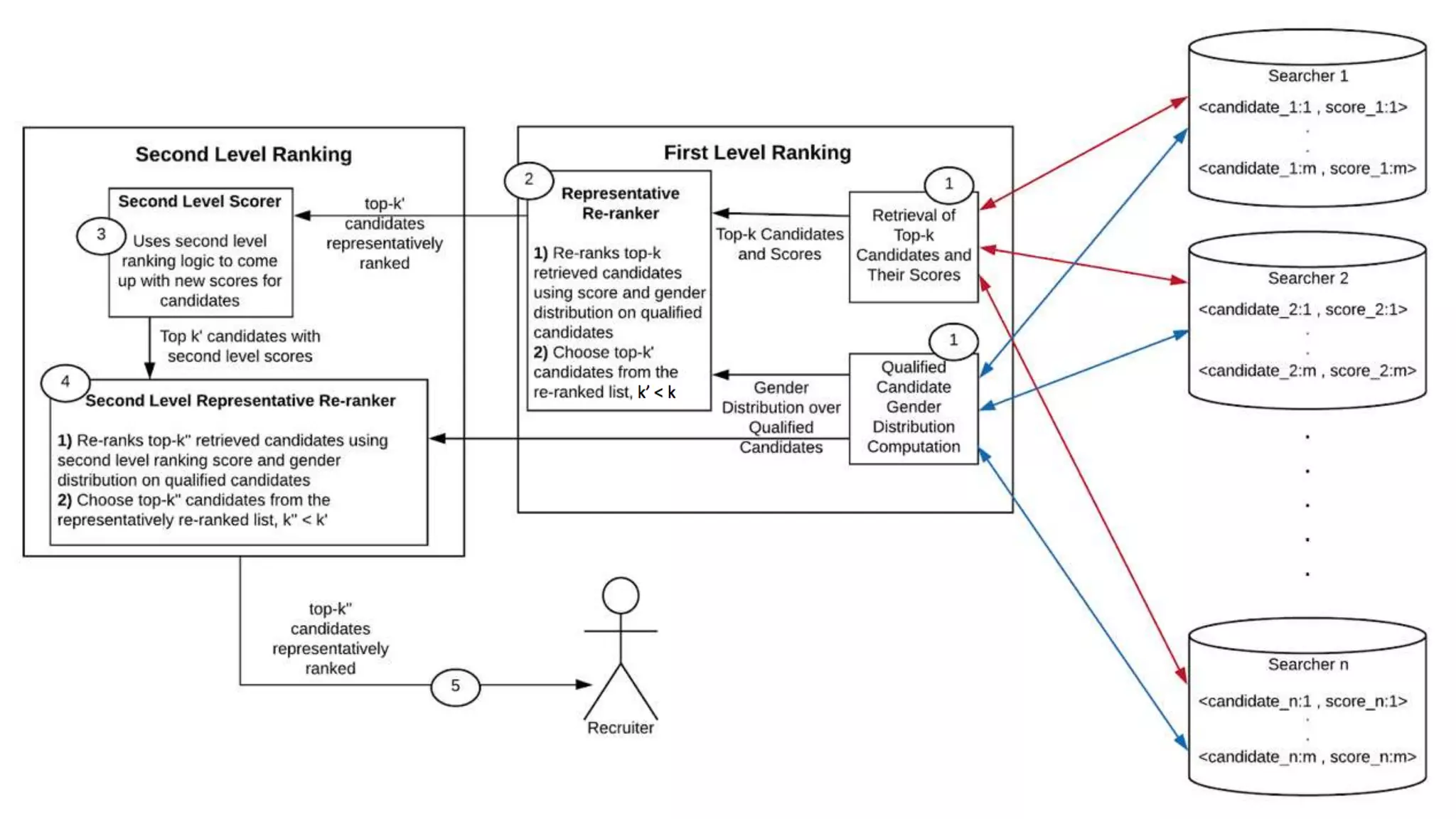
![Representative Ranking for Talent Search
S. C. Geyik, S. Ambler,
K. Kenthapadi, Fairness-
Aware Ranking in Search &
Recommendation Systems with
Application to LinkedIn Talent
Search, KDD’19.
[Microsoft’s AI/ML
conference
(MLADS’18). Distinguished
Contribution Award]
Building Representative
Talent Search at LinkedIn
(LinkedIn engineering blog)](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-23-2048.jpg)
![Intuition for Measuring and Achieving Representativeness
Ideal: Top ranked results should follow a desired distribution on
gender/age/…
E.g., same distribution as the underlying talent pool
Inspired by “Equal Opportunity” definition [Hardt et al, NIPS’16]
Defined measures (skew, divergence) based on this intuition](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-24-2048.jpg)





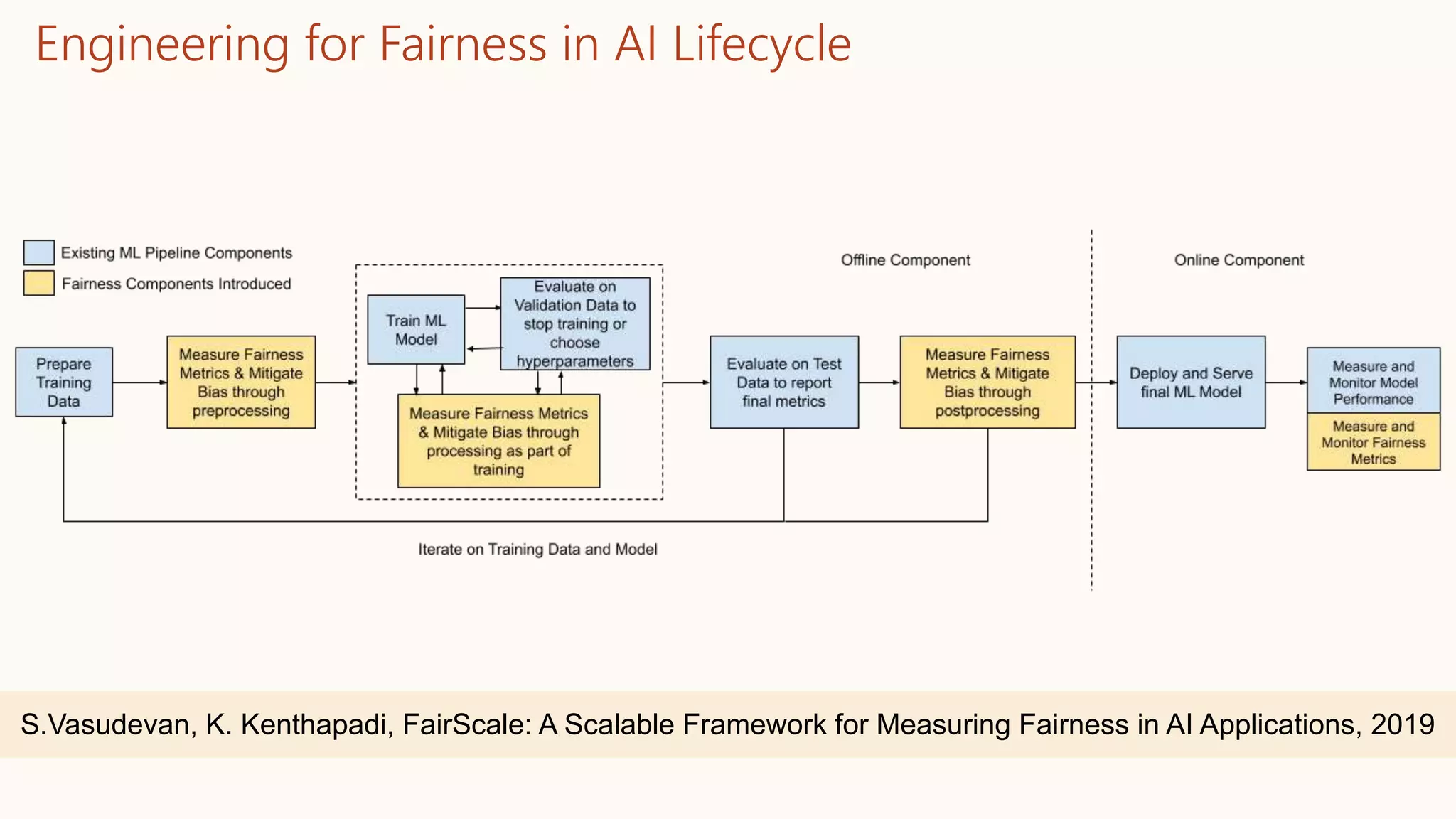
![FairScale System Architecture [Vasudevan & Kenthapadi, 2019]
• Flexibility of Use
(Platform agnostic)
• Ad-hoc exploratory
analyses
• Deployment in offline
workflows
• Integration with ML
Frameworks
• Scalability
• Diverse fairness
metrics
• Conventional fairness
metrics
• Benefit metrics
• Statistical tests](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-33-2048.jpg)
![Fairness-aware Experimentation
[Saint-Jacques & Sepehri, KDD’19 Social Impact Workshop]
Imagine LinkedIn has 10 members.
Each of them has 1 session a day.
A new product increases sessions by +1 session per member on average.
Both of these are +1 session / member on average!
One is much more unequal than the other. We want to catch that.](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-34-2048.jpg)





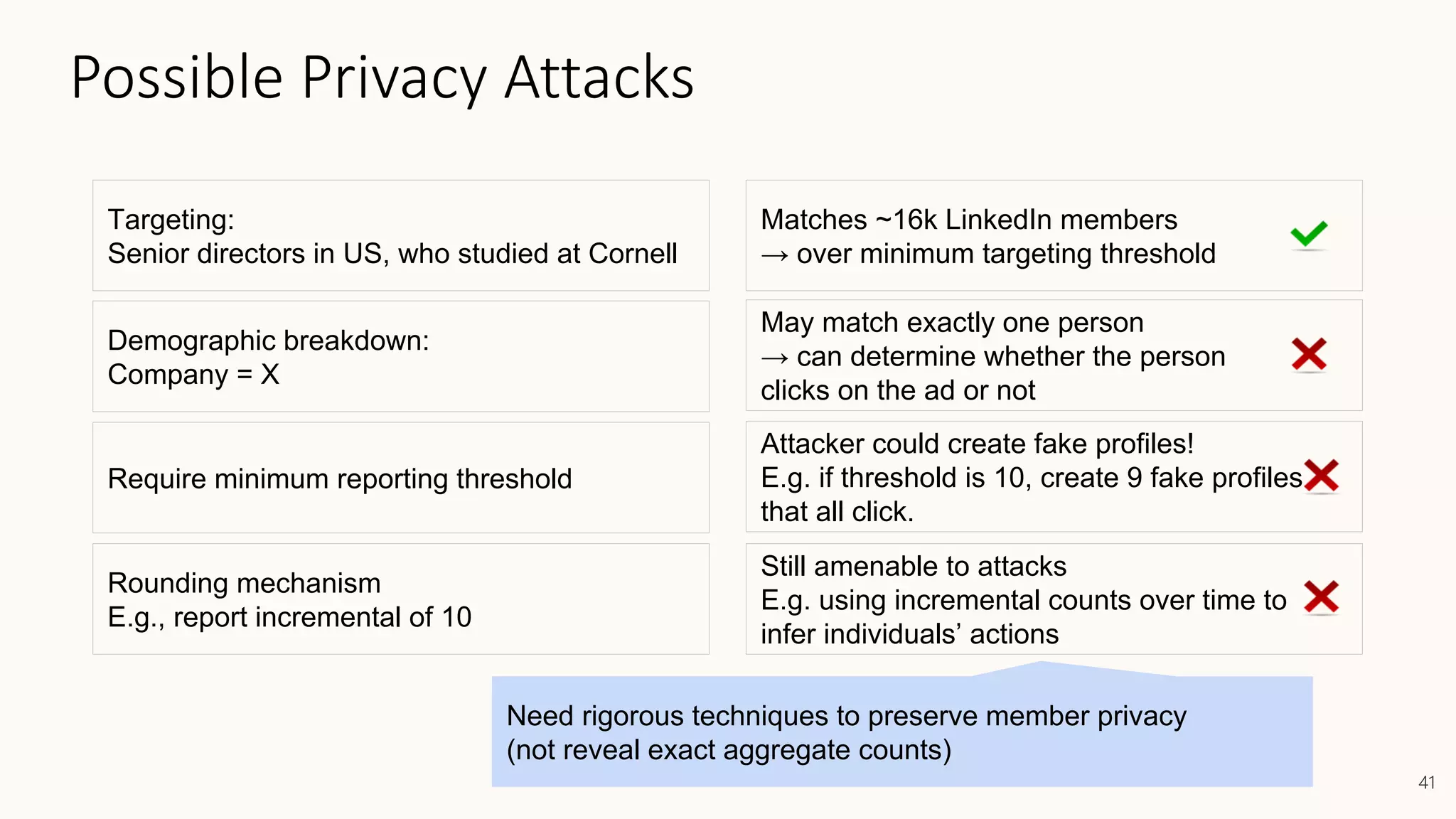


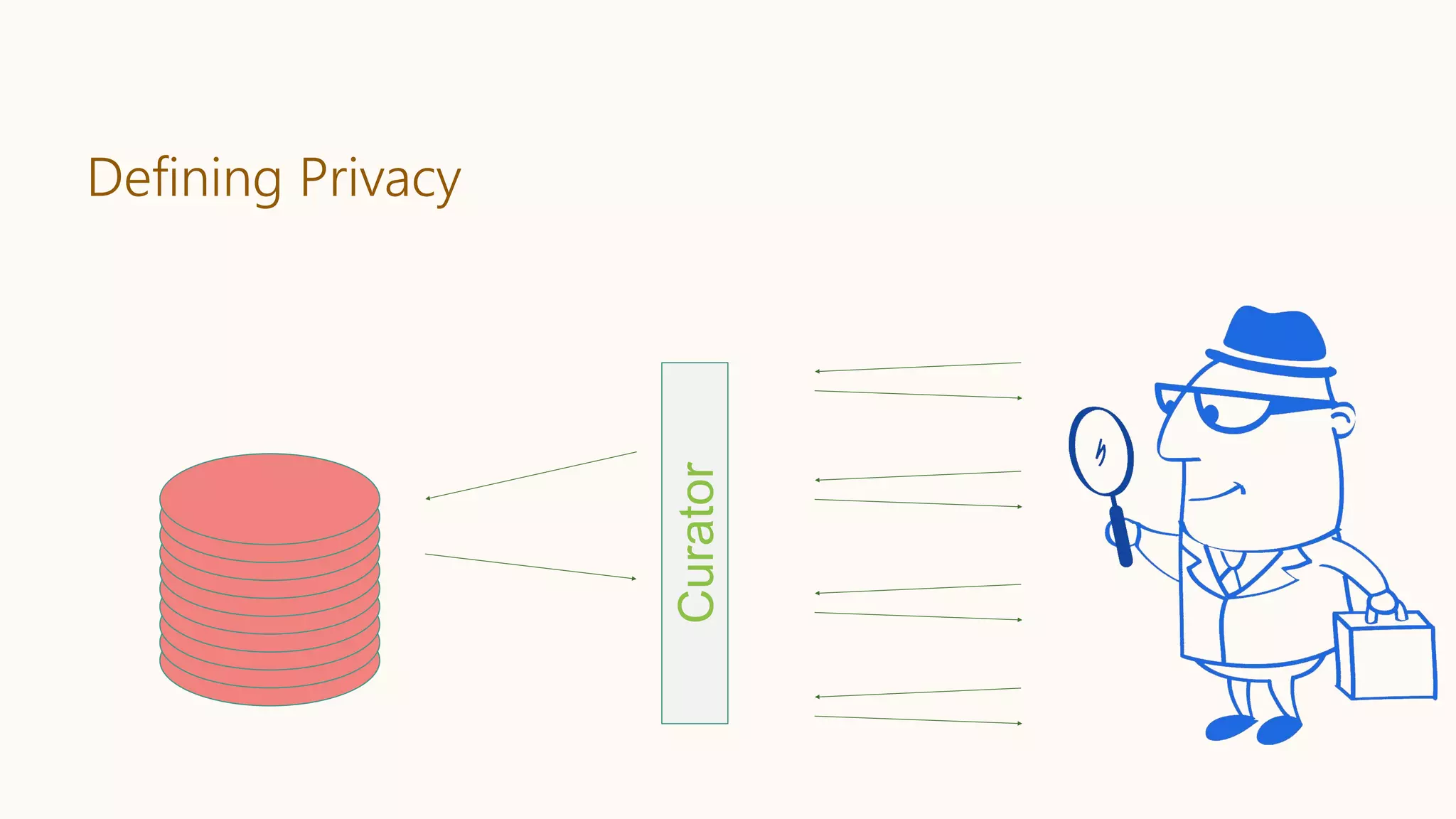
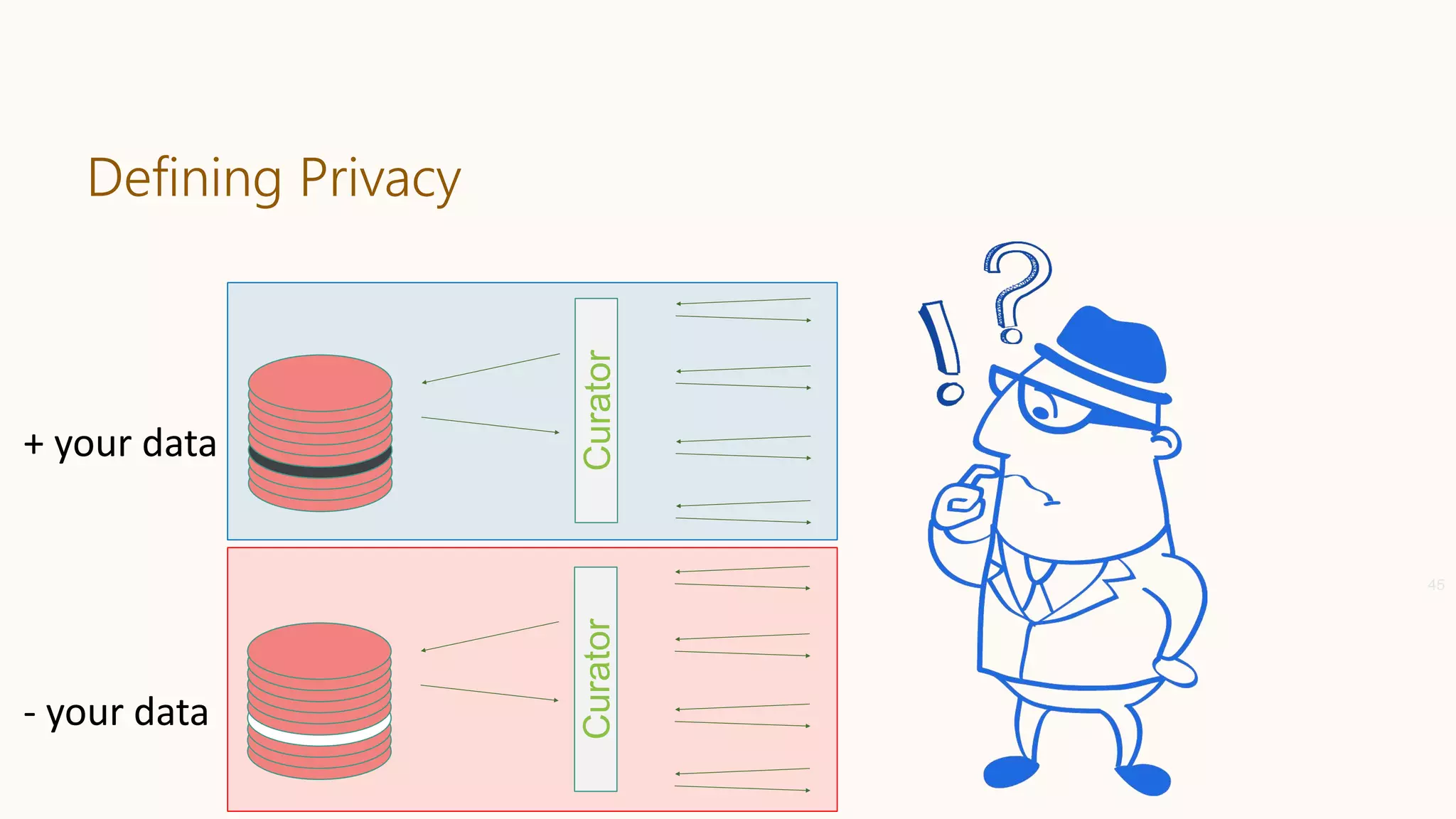
![Differential Privacy
46
Databases D and D′ are neighbors if they differ in one person’s data.
Differential Privacy: The distribution of the curator’s output M(D) on database
D is (nearly) the same as M(D′).
Curator
+ your data
- your data
Dwork, McSherry, Nissim, Smith [TCC 2006]
Curator](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-46-2048.jpg)
![(ε, 𝛿)-Differential Privacy: The distribution of the curator’s output M(D) on
database D is (nearly) the same as M(D′).
Differential Privacy
47
Curator
Parameter ε quantifies
information leakage
∀S: Pr[M(D)∊S] ≤ exp(ε) ∙ Pr[M(D′)∊S]+𝛿.Curator
Parameter 𝛿 gives
some slack
Dwork, Kenthapadi, McSherry, Mironov, Naor [EUROCRYPT 2006]
+ your data
- your data
Dwork, McSherry, Nissim, Smith [TCC 2006]](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-47-2048.jpg)
![Differential Privacy: Random Noise Addition
If ℓ1-sensitivity of f : D → ℝn:
maxD,D′ ||f(D) − f(D′)||1 = s,
then adding Laplacian noise to true output
f(D) + Laplacen(s/ε)
offers (ε,0)-differential privacy.
Dwork, McSherry, Nissim, Smith [TCC 2006]](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-48-2048.jpg)
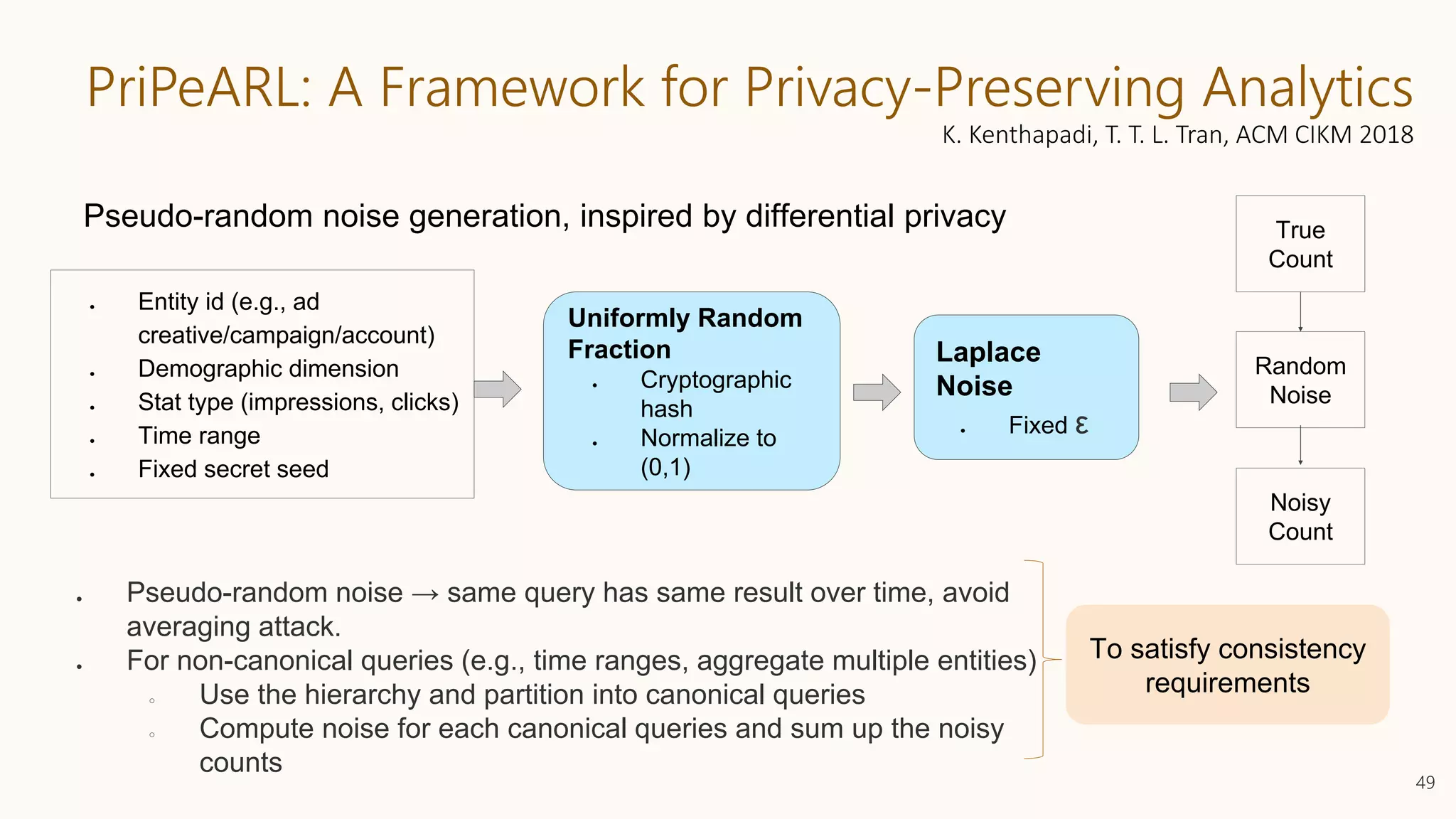













![Thanks! Questions?
S. C. Geyik, S. Ambler, K. Kenthapadi, Fairness-Aware Ranking in Search &
Recommendation Systems with Application to LinkedIn Talent Search, KDD’19
[Microsoft’s AI/ML conference (MLADS’18). Distinguished Contribution Award]
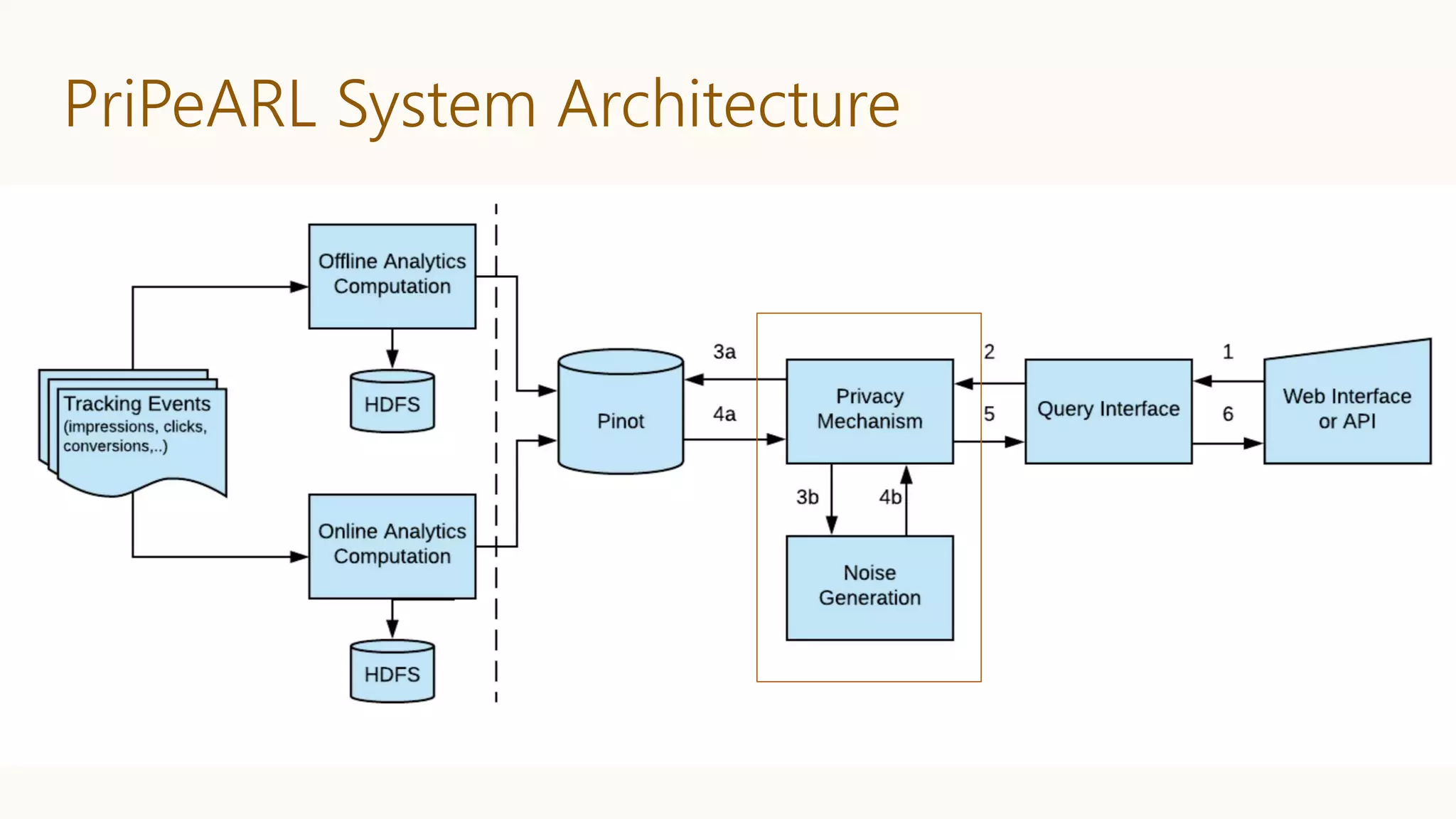
K. Kenthapadi, T. T. L. Tran, PriPeARL: A Framework for Privacy-Preserving
Analytics and Reporting at LinkedIn, CIKM’18
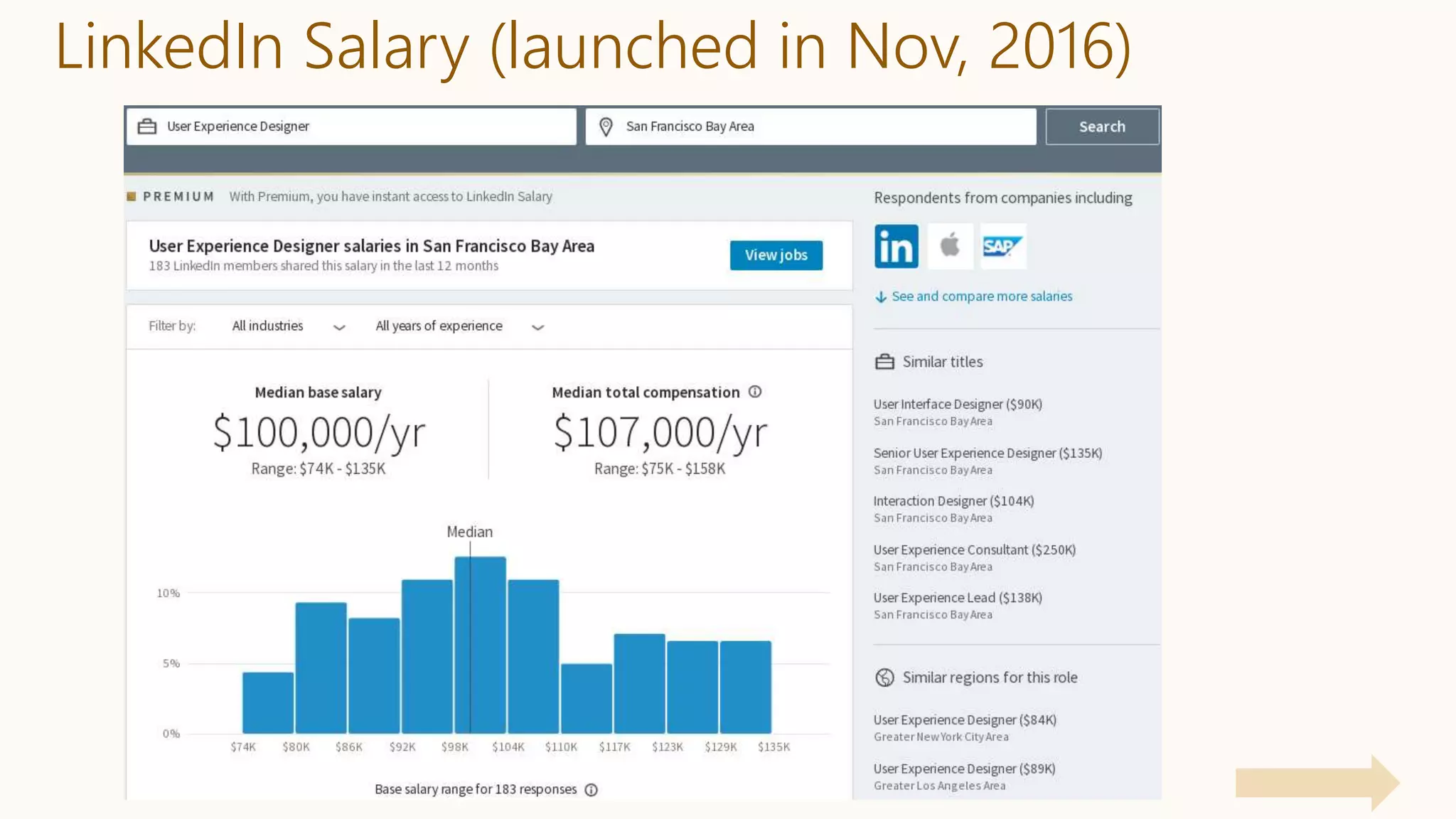
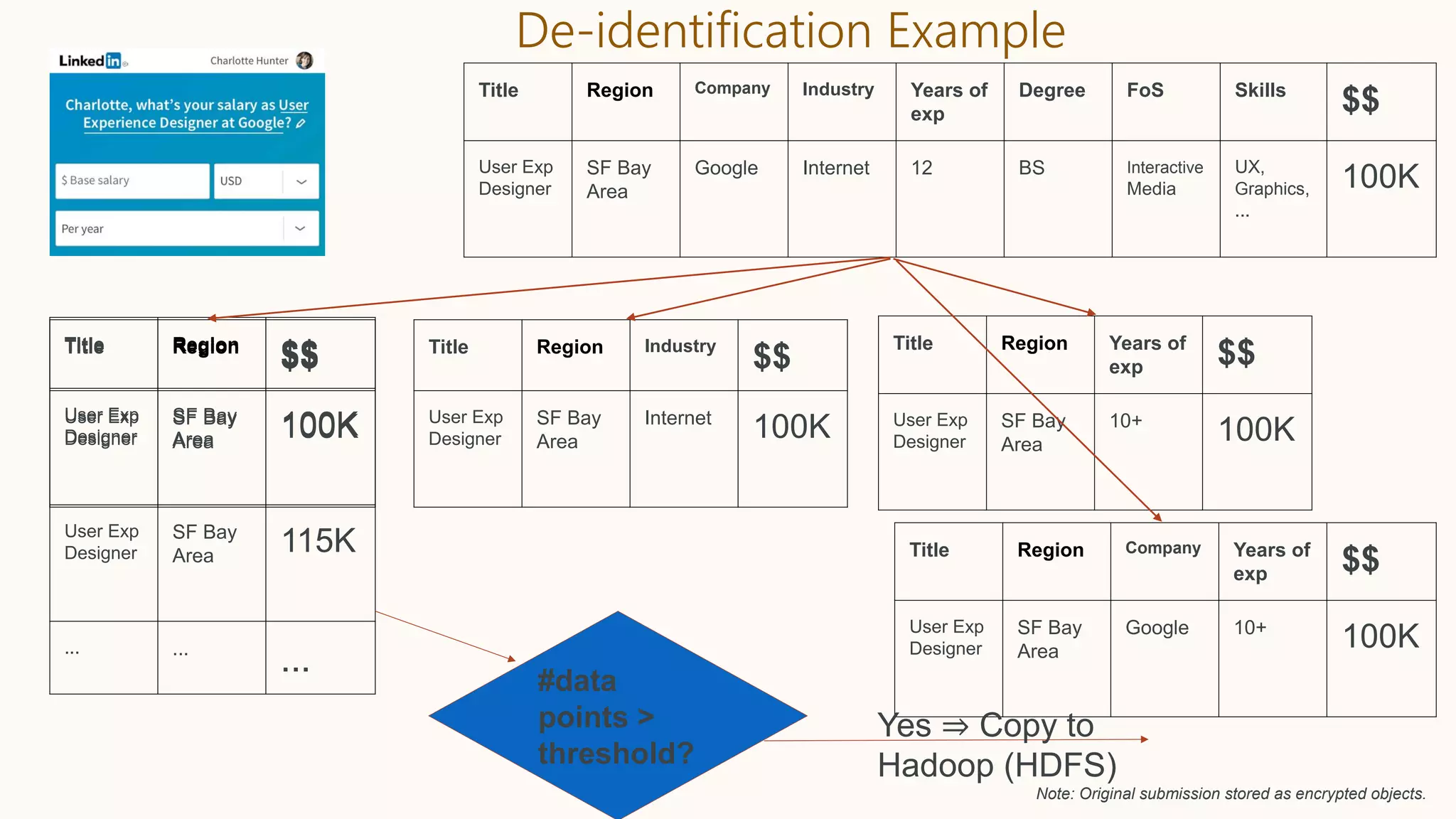
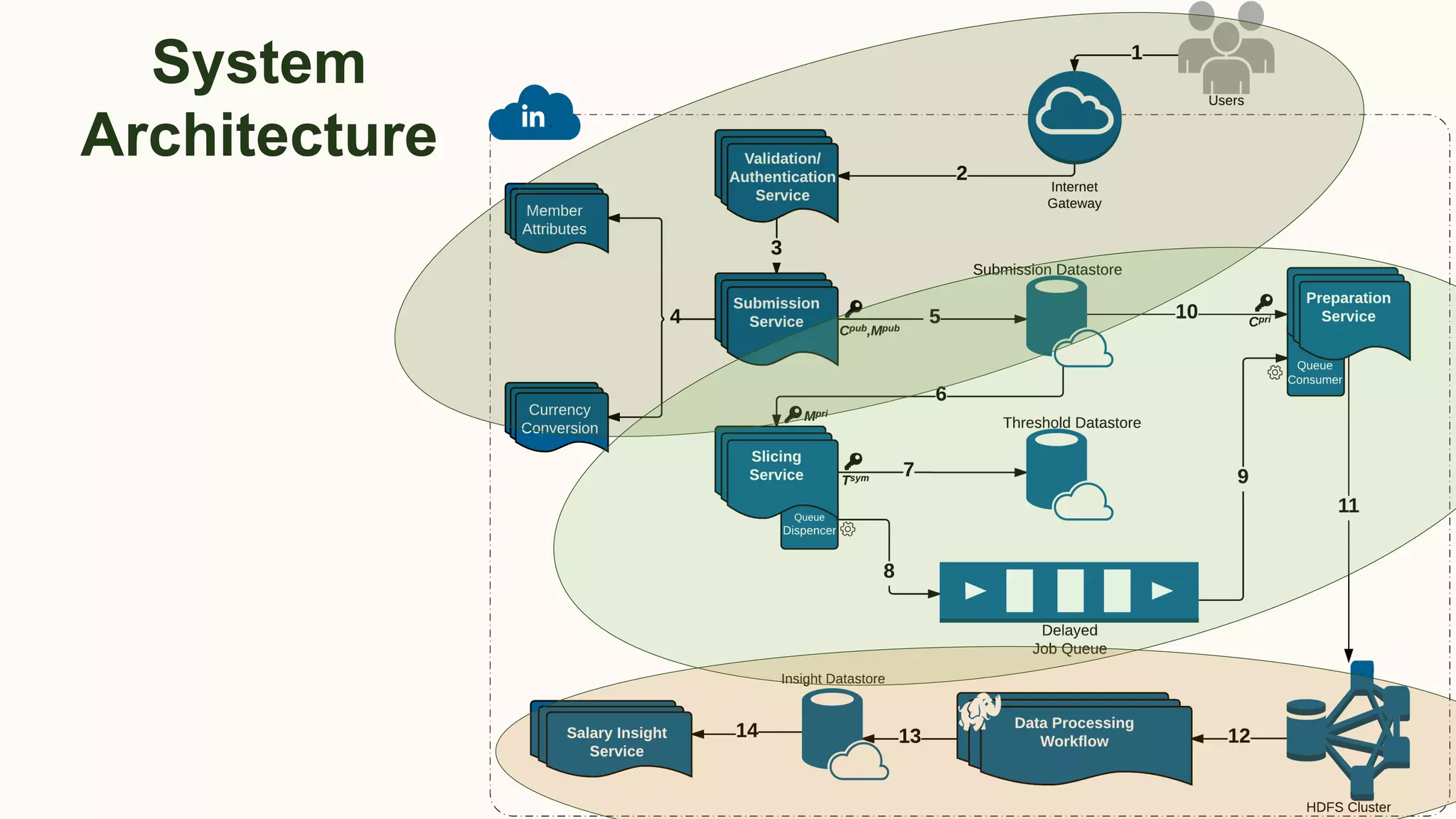
K. Kenthapadi, A. Chudhary, S. Ambler, LinkedIn Salary, IEEE Symposium on
Privacy-Aware Computing (PAC), 2017 [Related: our KDD’18 & CIKM’17 (Best
Case Studies Paper Award) papers]
Our tutorials on privacy, on fairness, and on explainability in industry at
KDD/WSDM/WWW/FAccT/AAAI (combining experiences at Apple, Facebook,
Google, LinkedIn, Microsoft)](https://image.slidesharecdn.com/202001-fairnessandprivacyinaimlsystems-kenthapadi-nobackup-200201220031/75/Fairness-and-Privacy-in-AI-ML-Systems-67-2048.jpg)


































































![Computer Networks 01[1 using all terms].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/computernetworks011-251214040533-327dd9f8-thumbnail.jpg?width=640&height=640&fit=bounds)








