Download as PDF, PPTX




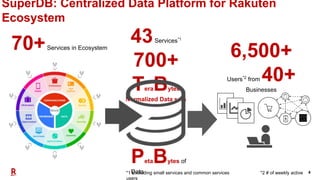
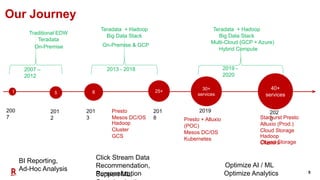
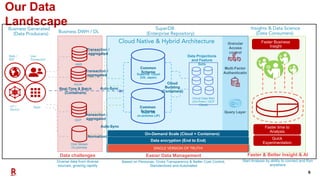
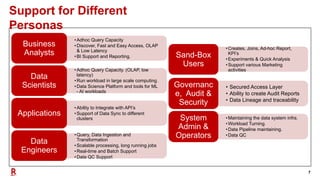


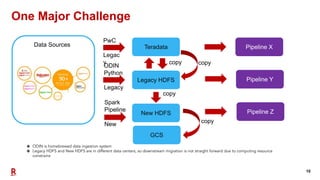
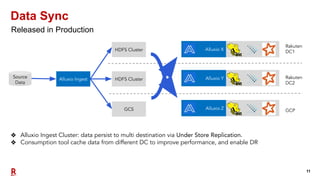
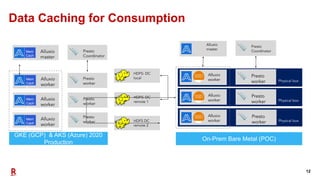
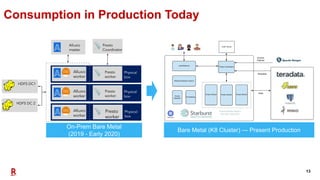
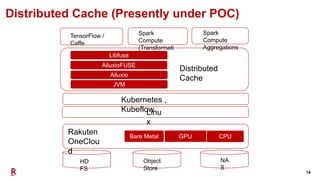
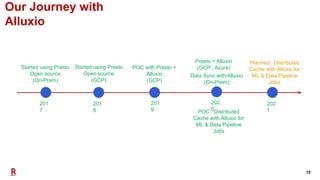
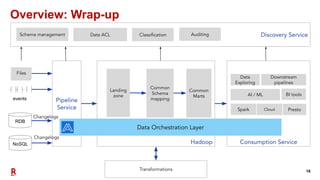


The document outlines Rakuten's evolution of its centralized data analytics platform, SuperDB, highlighting its transition from traditional data storage methods to a multi-cloud architecture using Alluxio and Presto for enhanced data orchestration and analytics. It discusses the challenges faced, such as data availability and system scalability, and how the adoption of cloud-native solutions has improved the efficiency and speed of data processing. Additionally, it details the integrated approach to managing data across diverse sources, ensuring a single version of truth and enabling real-time insights.























































































