This document discusses various machine learning methods that have been applied to computer architecture problems. It begins by introducing k-means clustering and how it is used in SimPoint to reduce architecture simulation time. It then discusses how machine learning can be used for design space exploration in multi-core processors and for coordinated resource management on multiprocessors. Finally, it provides an example of using artificial neural networks to build performance models to inform resource allocation decisions.





![skip the first billion instructions and sample the rest of the program. The white bars are the error
associated with SimPoint.
The overall error rate is important but what is far more important given a significantly
high error rate is that the bias of the error from one architecture to another is the same.
The reason for this is that if the bias of error is the same between architectures then
regardless of the magnitude of the error they can be compared fairly without having to
run a reference trial.
Machine learning has the potential to take simulation running time from months to days
or even hours. This is a significant time savings for development and has potential to
become the choice used in industry. SimPoint is being used in industry by companies
such as Intel [1].
Design Space Exploration
As multi-core processor architectures with tens or even hundreds of cores, not all of
them necessarily identical, become common, the current processor design methodology
that relies on large-scale simulations is not going to scale well because of the number of
possibilities to be considered. In the previous section, we saw how time consuming it
can be to evaluate the performance of a single processor. Performance evaluation can
be even trickier with multicore processors. Consider the design of a k-core chip
multiprocessor where each core can be chosen from a library of n cores. There are nk
designs possible. If n = 100 and k = 4, there are totally 10 million possibilities. We see
that the design space explodes even for very small n and k. It is obvious that we need
to find a smart way to choose the ʻbestʼ from these nk designs. We need intelligent/
efficient techniques to navigate through the processor design space. There are two
approaches to tackle this problem
1. Reduce the simulation time for a single design configuration. Techniques like
SimPoint can be used to approximately predict the performance.
2. Reduce the number of configurations tested. In this case, only a small number of
configurations are tested, i.e. the search space is pruned. At each point, the
algorithm moves to a new configuration in a direction that increases the performance
by the maximum amount. This can be thought of as a Steepest Ascent Hill Climbing
algorithm. The algorithm may get stuck at local maxima. To overcome this, one may
employ Hybrid Start Hill Climbing, wherein the Steepest Ascent Hill Climbing is
initiated at several initial points. Each initial point will converge to a local maxima and
the global maximum is the maximum amongst these local maxima. Other search
techniques such as Genetic Algorithm, Ant Colony Optimization may also be applied.
In reality, all the nk configurations may not be very different from each other. So, we can
group processors based on some relative similarities. One simple method is k-tuple
Tagging. Each processor is characterized by the following parameters ( k=5 here)](https://image.slidesharecdn.com/a-survey-of-machine-learning-methods-applied-to-computer1422/85/A-Survey-of-Machine-Learning-Methods-Applied-to-Computer-6-320.jpg)

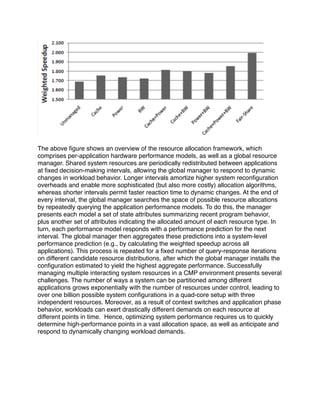








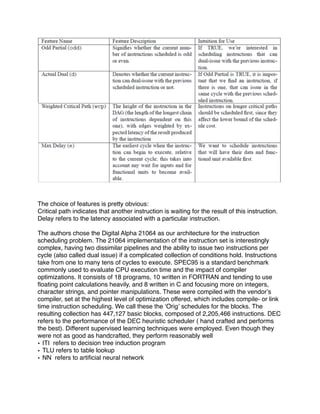
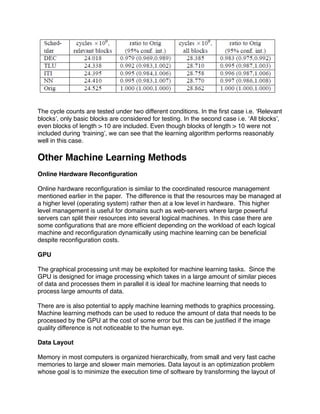
![data structures to improve spatial locality. Automatic data layout performed by the
compiler is currently attracting much attention as significant speed-ups have been
reported. The state-of-the-art is that the problem is known to be NP-complete. Hence,
Machine learning methods may be employed to identify good heuristics and improve
overall speedup.
Emulate Highly Parallel Systems
The efficient mapping of program parallelism to multi-core processors is highly
dependent on the underlying architecture. Applications can either be written from
scratch in a parallel manner, or, given the large legacy code base, converted from an
existing sequential form. In [15], the authors assume that program parallelism is
expressed in a suitable language such as OpenMP. Although the available parallelism
is largely program dependent, finding the best mapping is highly platform or hardware
dependent. There are many decisions to be made when mapping a parallel program to
a platform. These include determining how much of the potential parallelism should be
exploited, the number of processors to use, how parallelism should be scheduled etc.
The right mapping choice depends on the relative costs of communication, computation
and other hardware costs and varies from one multicore to the next. This mapping can
be performed manually by the programmer or automatically by the compiler or run-time
system. Given that the number and type of cores is likely to change from generation to
the next, finding the right mapping for an application may have to be repeated many
times throughout an applicationʼs lifetime, thus making Machine learning based
approaches attractive.
References
1. Greg Hamerly. Erez Perelman, Jeremy Lau, Brad Calder and Timothy Sherwood.
Using Machine Learning to Guide Architecture Simulation. Journal of Machine
Learning Research 7, 2006.
2. Sukhun Kang and Rakesh Kumar - Magellan: A Framework for Fast Multi-core
Design Space Exploration and Optimization Using Search and Machine Learning
Proceedings of the conference on Design, automation and test in Europe, 2008
3. R. Bitirgen, E. İpek, and J.F. Martínez - Coordinated management of multiple
resources in chip multiprocessors: A machine learning approach, In Intl. Symp. on
Microarchitecture, Lake Como, Italy, Nov. 2008.
4. Moss, Utgoff et al - Learning to Schedule Straight-Line Code NIPS 1997.
5. Malik, Russell et al - Learning Heuristics for Basic Block Instruction Scheduling,
Journal of Heuristics archive. Volume 14 , Issue 6 (December 2008).](https://image.slidesharecdn.com/a-survey-of-machine-learning-methods-applied-to-computer1422/85/A-Survey-of-Machine-Learning-Methods-Applied-to-Computer-19-320.jpg)




































































