Downloaded 120 times


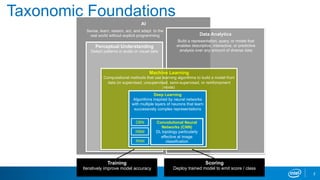
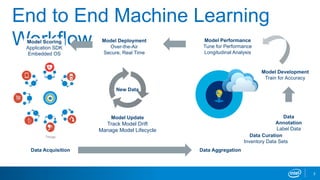

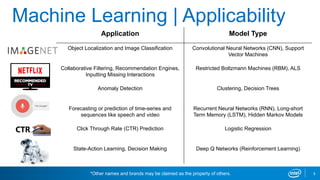
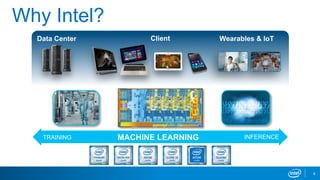
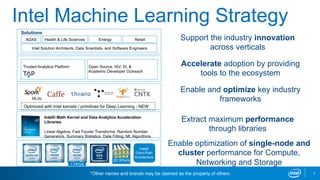




Intel's machine learning strategy focuses on leveraging diverse data for AI and data analytics through various computational methods, including deep learning and neural networks. The strategy emphasizes the importance of an end-to-end machine learning workflow, improved model performance, and advancements in hardware and algorithms to handle larger data efficiently. Intel also provides optimized tools and frameworks to enhance machine learning applications across different industries.






















































































