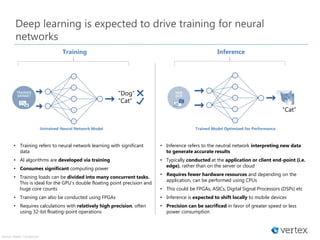
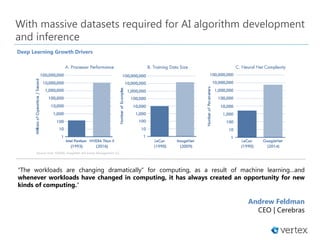
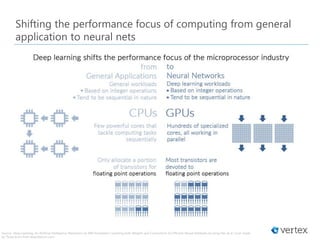
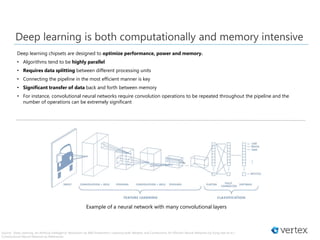
Download as PDF, PPTX




![And graph processing….
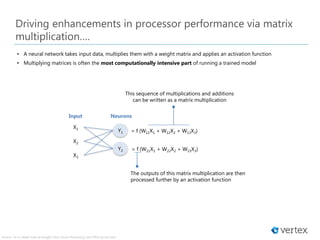
Scalar Processing
• Processes an operation per instruction
• CPUs run at clock speeds in the GHz range
• Might take a long time to execute large matrix operations
via a sequence of scalar operations
A1
A2
An
+ B1
B2
Bn
…
+
+
=
=
=
C1
C2
Cn
a[i] + b[i] = c[i]
for i = 1 to n
A1
A2
An
B1
B2
Bn
…
+ =
C1
C2
Cn
a[1:n] + b[1:n] = c[1:n]
.
.
.
.
.
.
.
.
.
.
.
Source: Spark 2.x - 2nd generation Tungsten Engine
Vector Processing
• Same operation performed concurrently across a large
number of data elements at the same time
• GPUs are effectively vector processors
Graph Processing
• Runs many computational processes (vertices)
• Calculates the effects these vertices on other points with
which they interact via lines (i.e. edges)
• Overall processing works on many vertices and points
simultaneously
• Low precision needed](https://image.slidesharecdn.com/vertexperspectives-aioptimizedchipsetspartii-180514061034/85/Vertex-Perspectives-AI-Optimized-Chipsets-Part-II-9-320.jpg)







The document discusses the evolution of AI-optimized chipsets driven by the demands of deep learning and neural networks, highlighting the shift from general computing to performance optimization for specialized tasks. It covers various technologies like GPUs, FPGAs, and ASICs while emphasizing the need for innovations to support high-performance, memory-efficient processing for AI applications, particularly in edge computing. The future is expected to involve a significant increase in custom chip designs tailored for specific applications, alongside a possible shift in training and inference capabilities closer to end devices.






















































































