Downloaded 47 times


![#UnifiedAnalytics #SparkAISummit 4
VS
https://www.pinterest.com/pin/16015933047709449
Platform Engineers:
What do you spend
your time doing?
Platform Users:
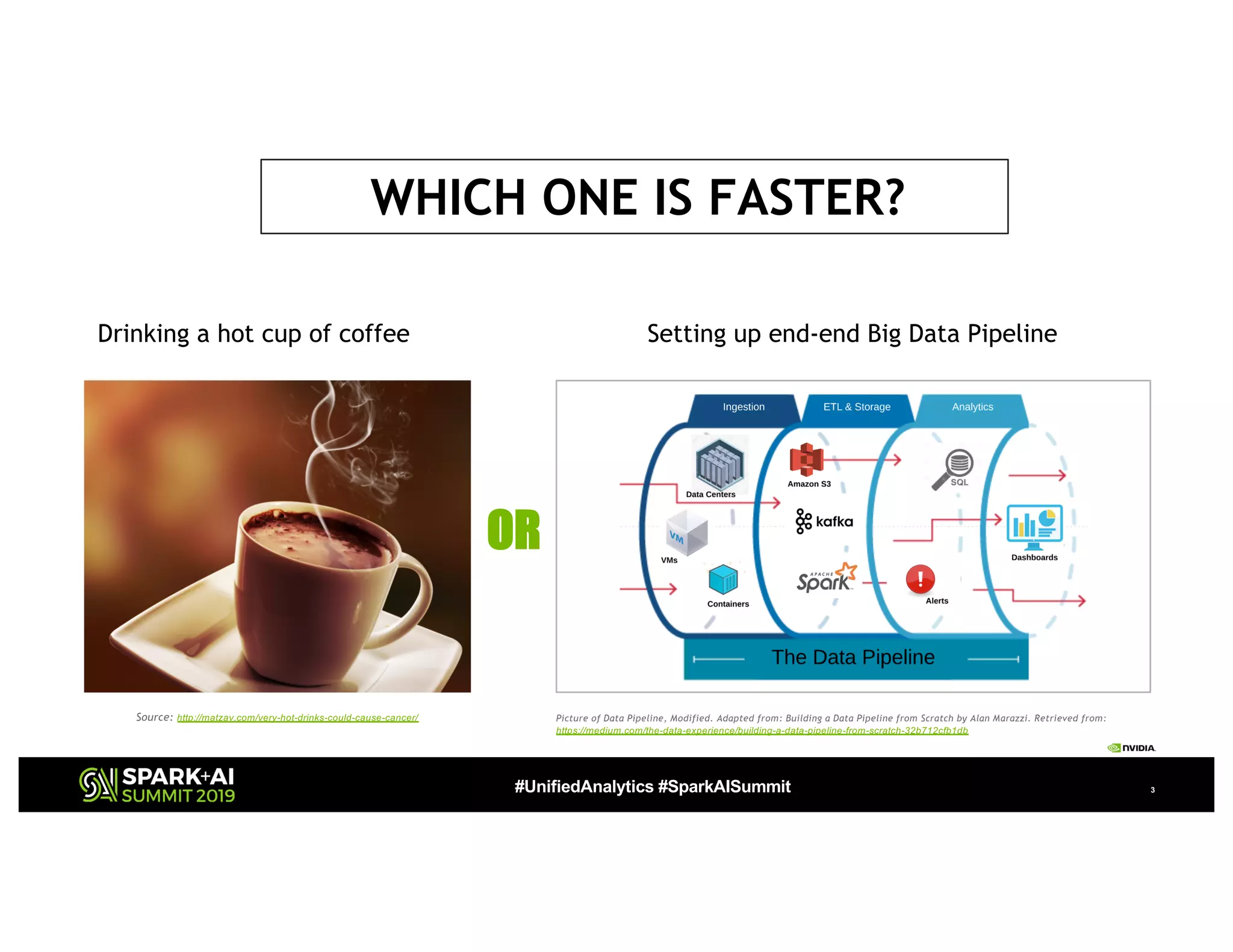
Is it faster to -
1. Drink a cup of hot
coffee
or
1. Build an end-to-end
Pipeline?
VS
[100%] -
Developing
Platform
Tools
[50%] -
Developing
Platform
Tools
[20%] -
Writing
ETL Jobs
[30%] -
Managing
Prod
Pipelines
[100%] -
Drinking a
cup of
coffee
Coffee Challenge
We Surveyed: v1.0 v2.0
[30%] -
Drinking
Coffee! [70%] -
Building
end-to-
end
Pipeline](https://image.slidesharecdn.com/022007satishdandurohitkulkarni-190507232814/75/A-Journey-to-Building-an-Autonomous-Streaming-Data-Platform-Scaling-to-Trillion-Events-Monthly-at-Nvidia-4-2048.jpg)



![10
10K Foot Overview - UpStream & Downstream[v1] 10K Foot Overview - UpStream & DownStream
Data Sources Gateway Data Processing](https://image.slidesharecdn.com/022007satishdandurohitkulkarni-190507232814/75/A-Journey-to-Building-an-Autonomous-Streaming-Data-Platform-Scaling-to-Trillion-Events-Monthly-at-Nvidia-10-2048.jpg)
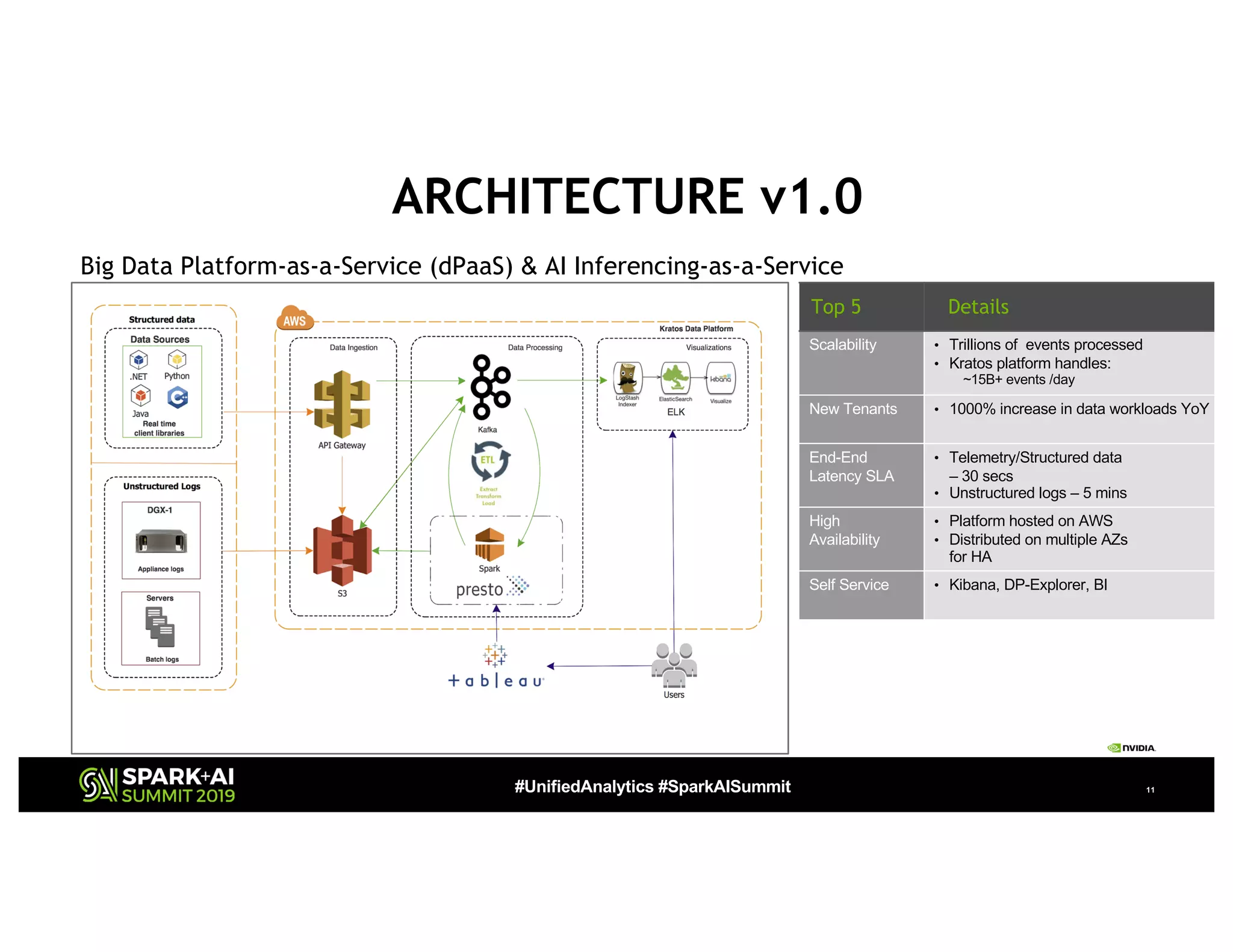
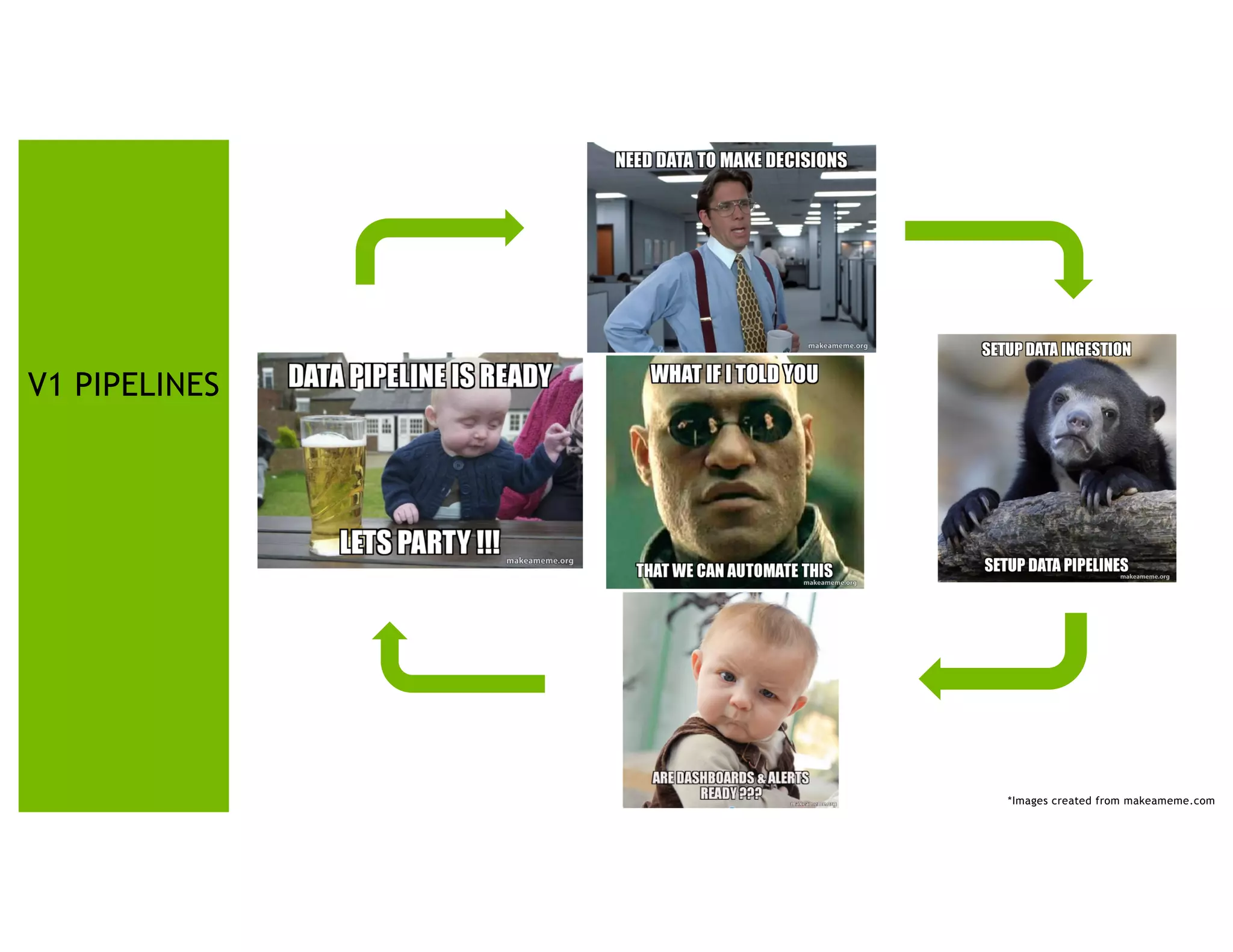
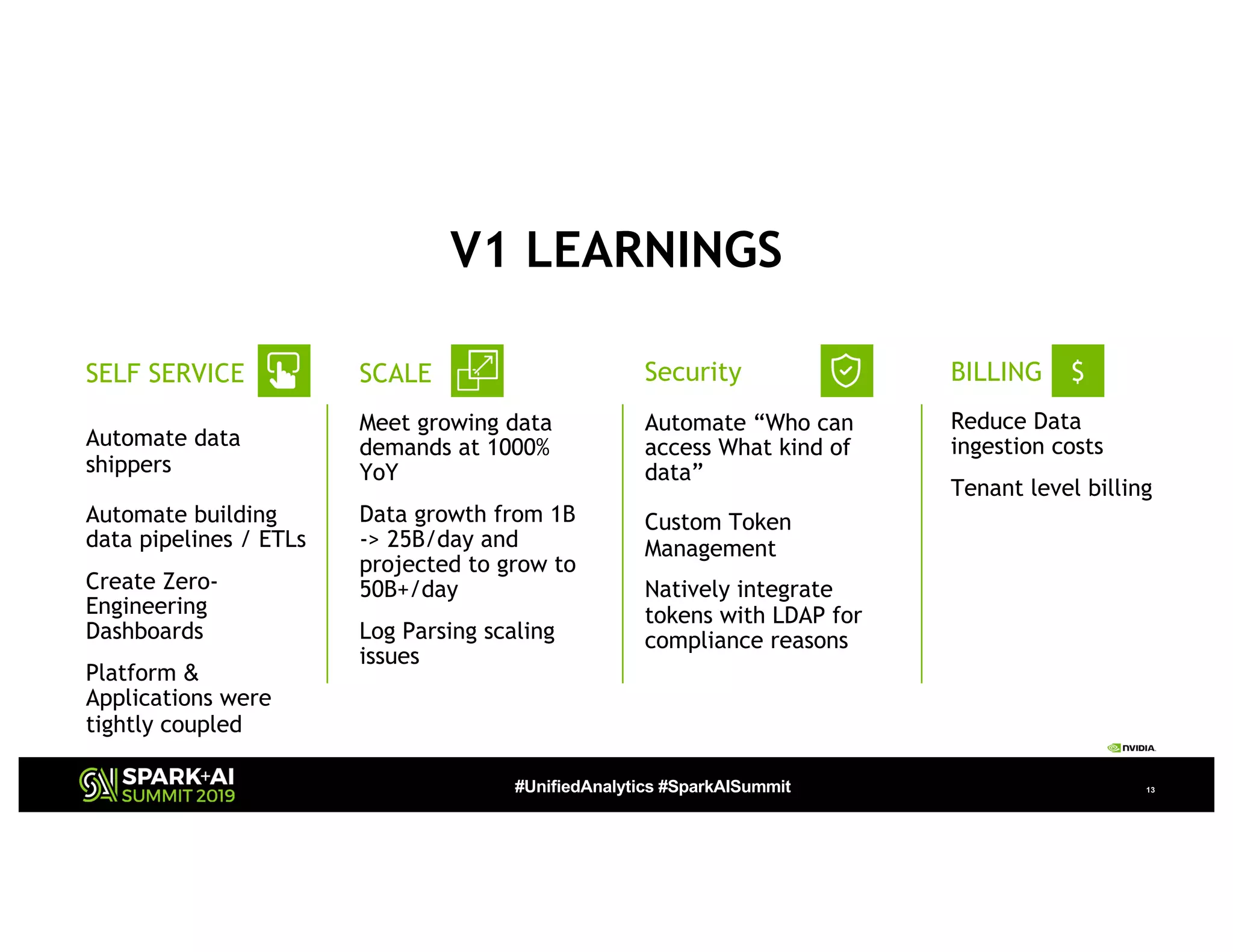
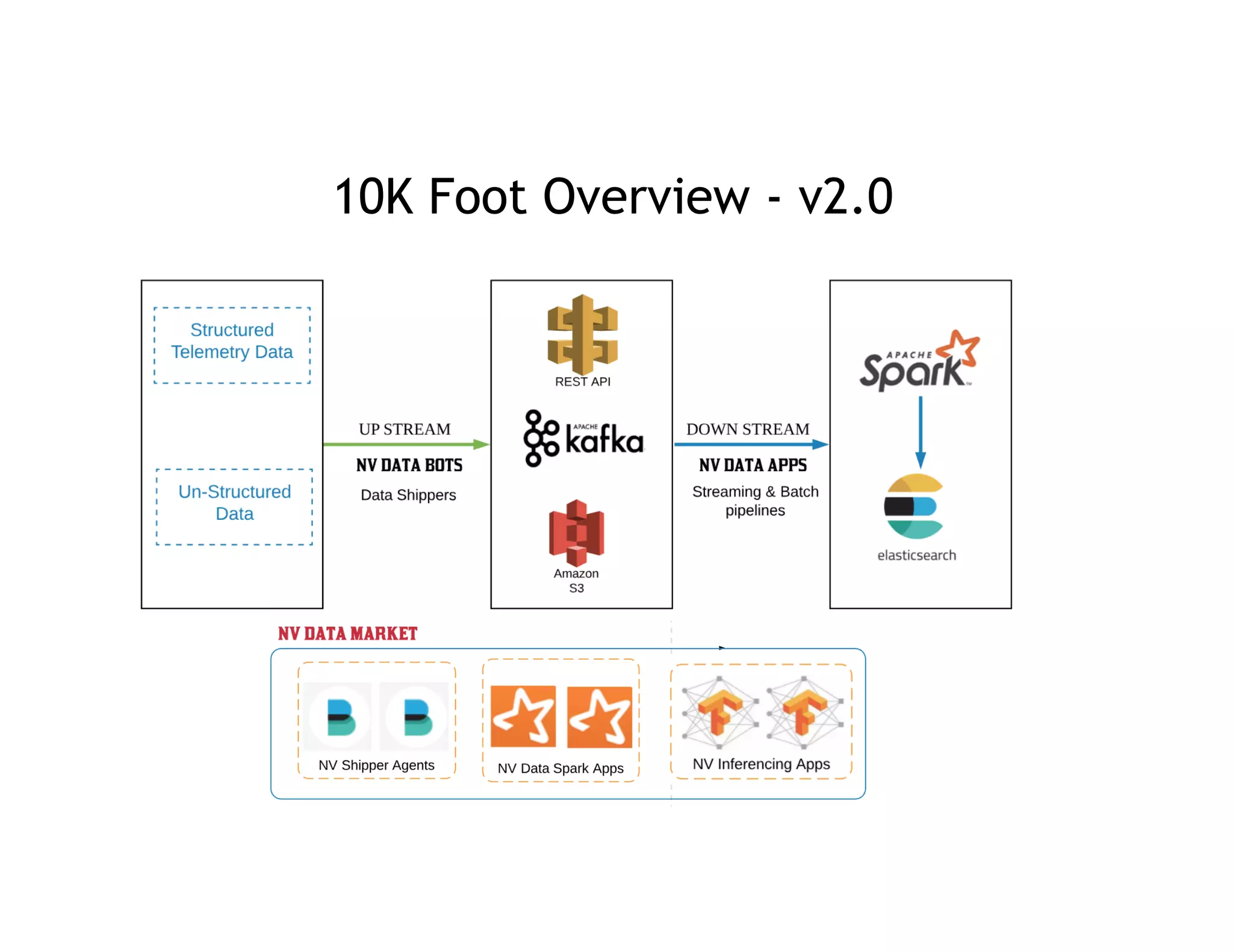
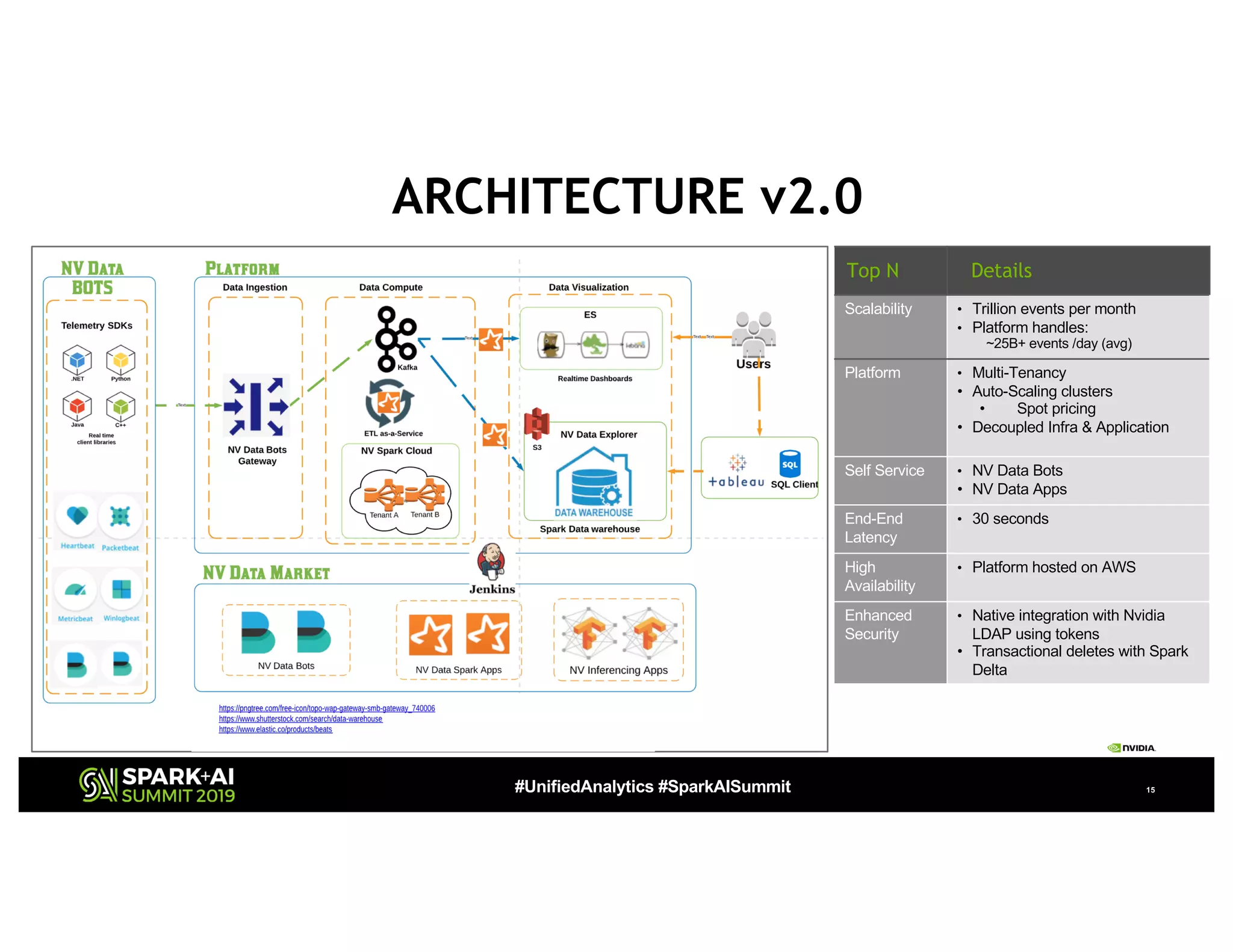
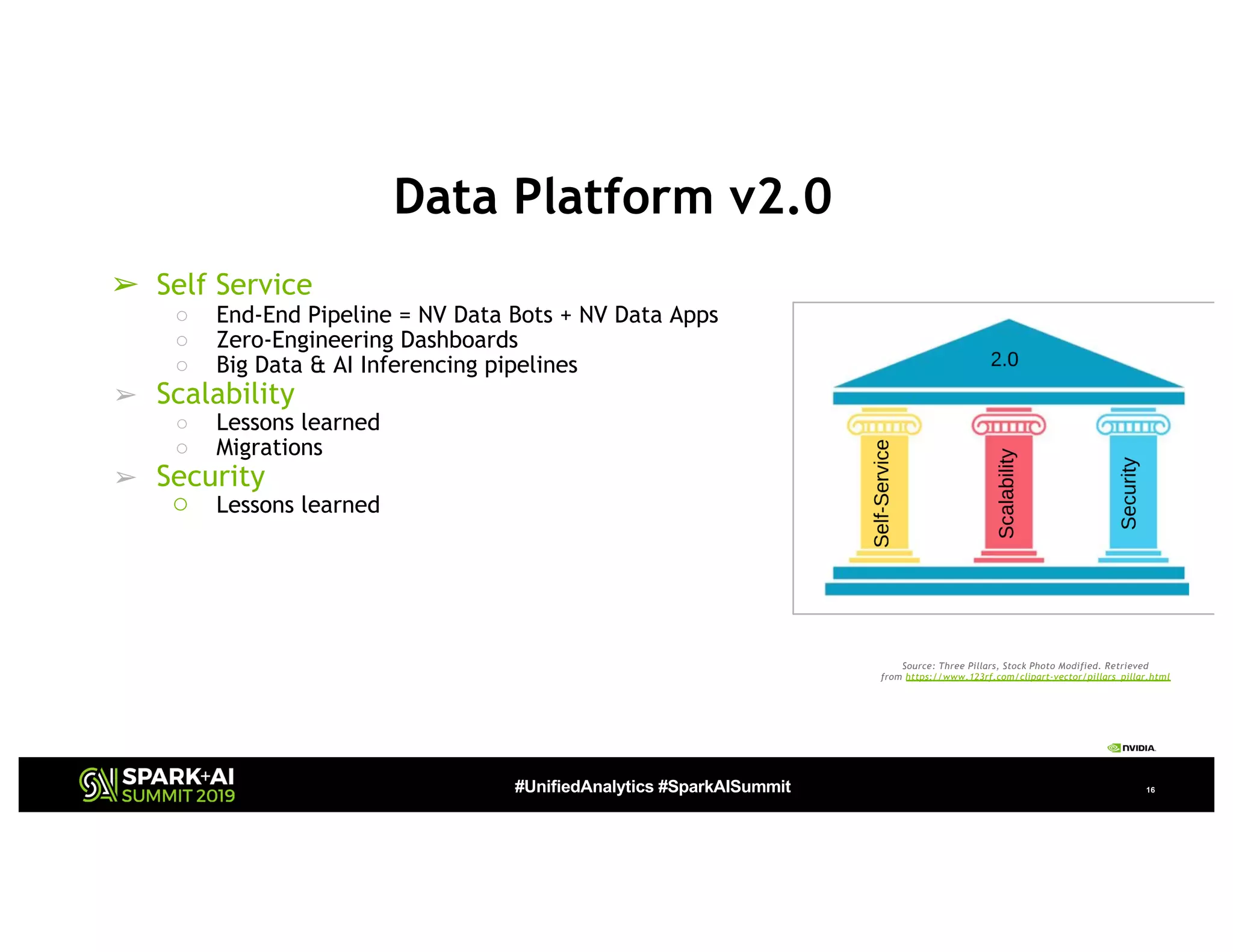


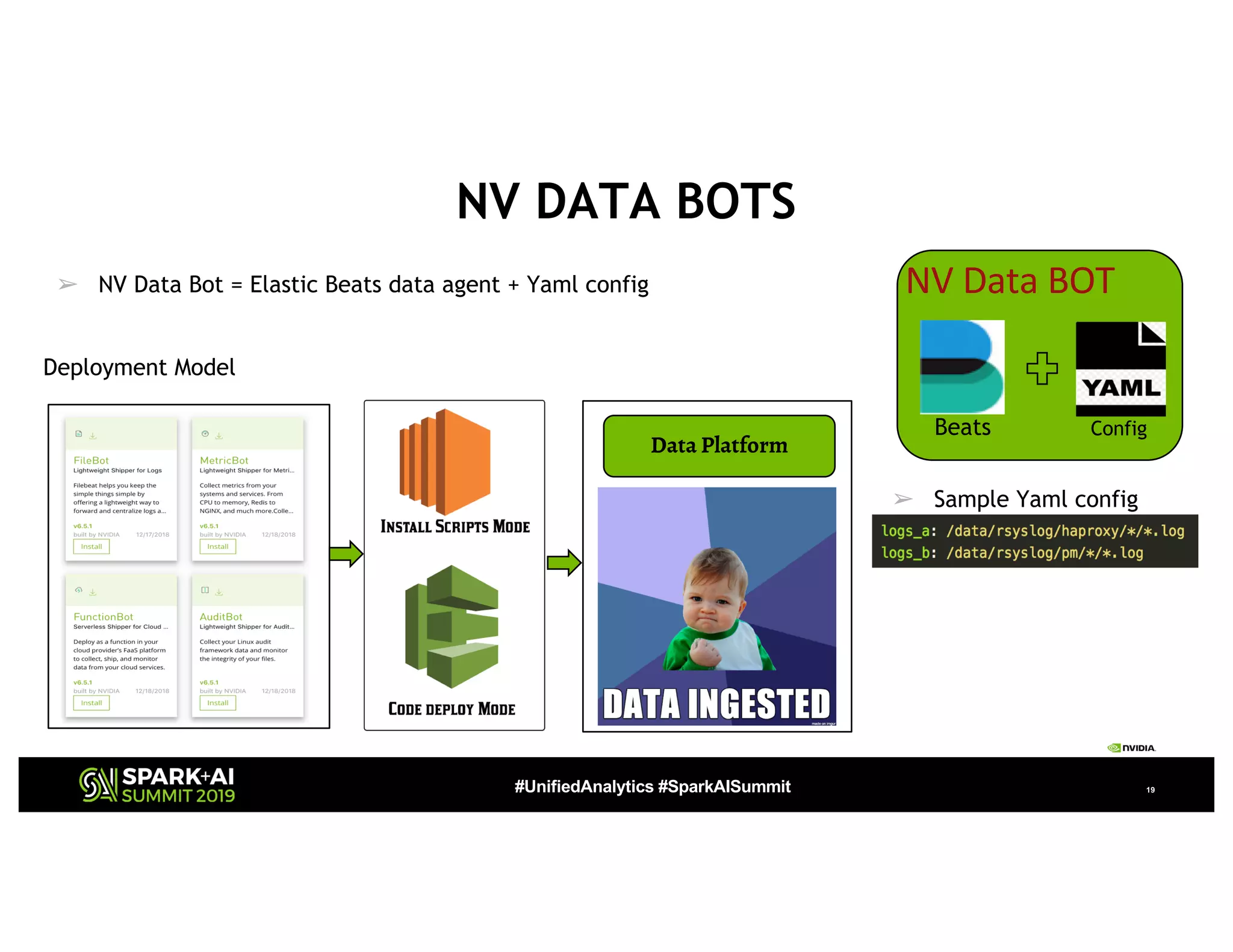
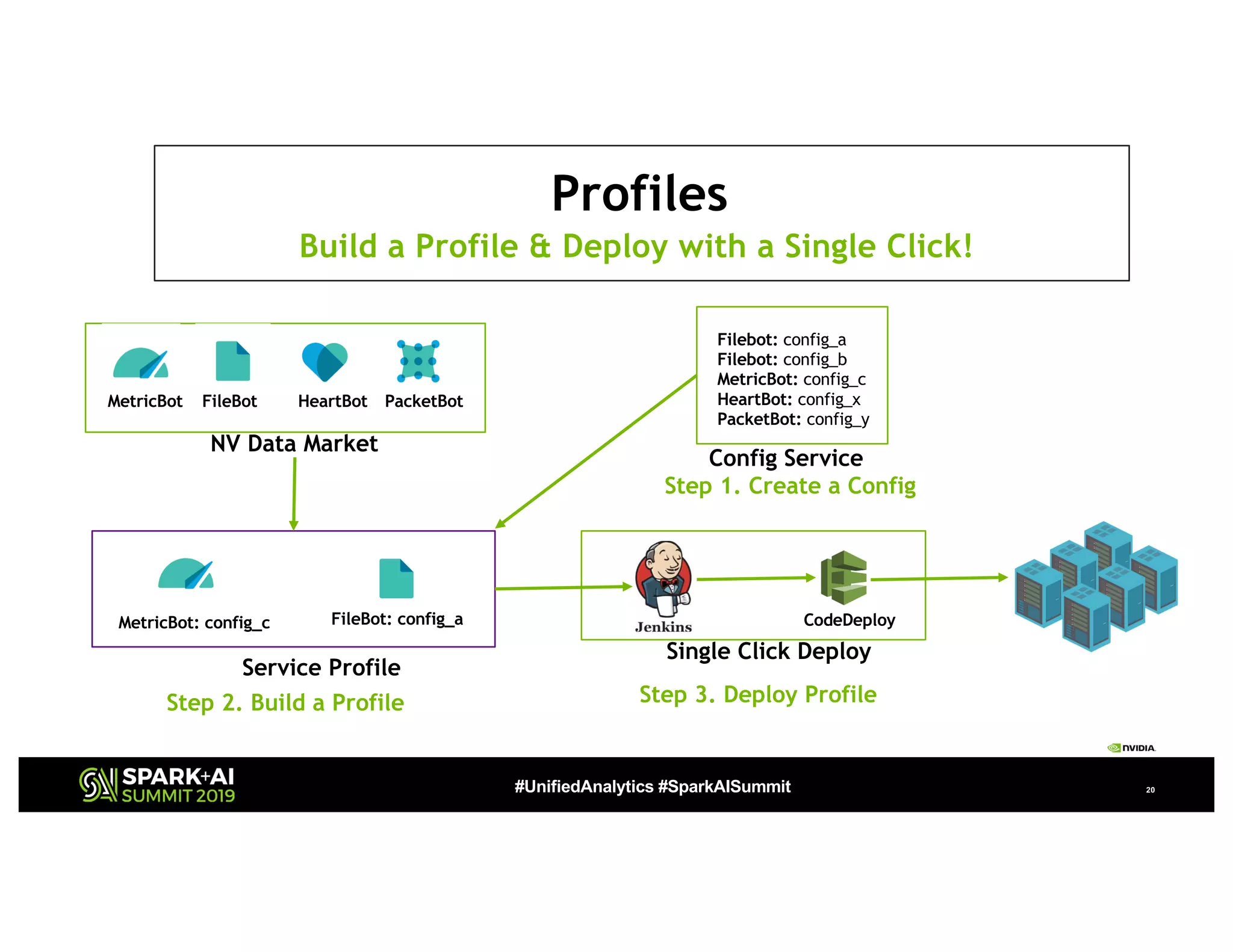

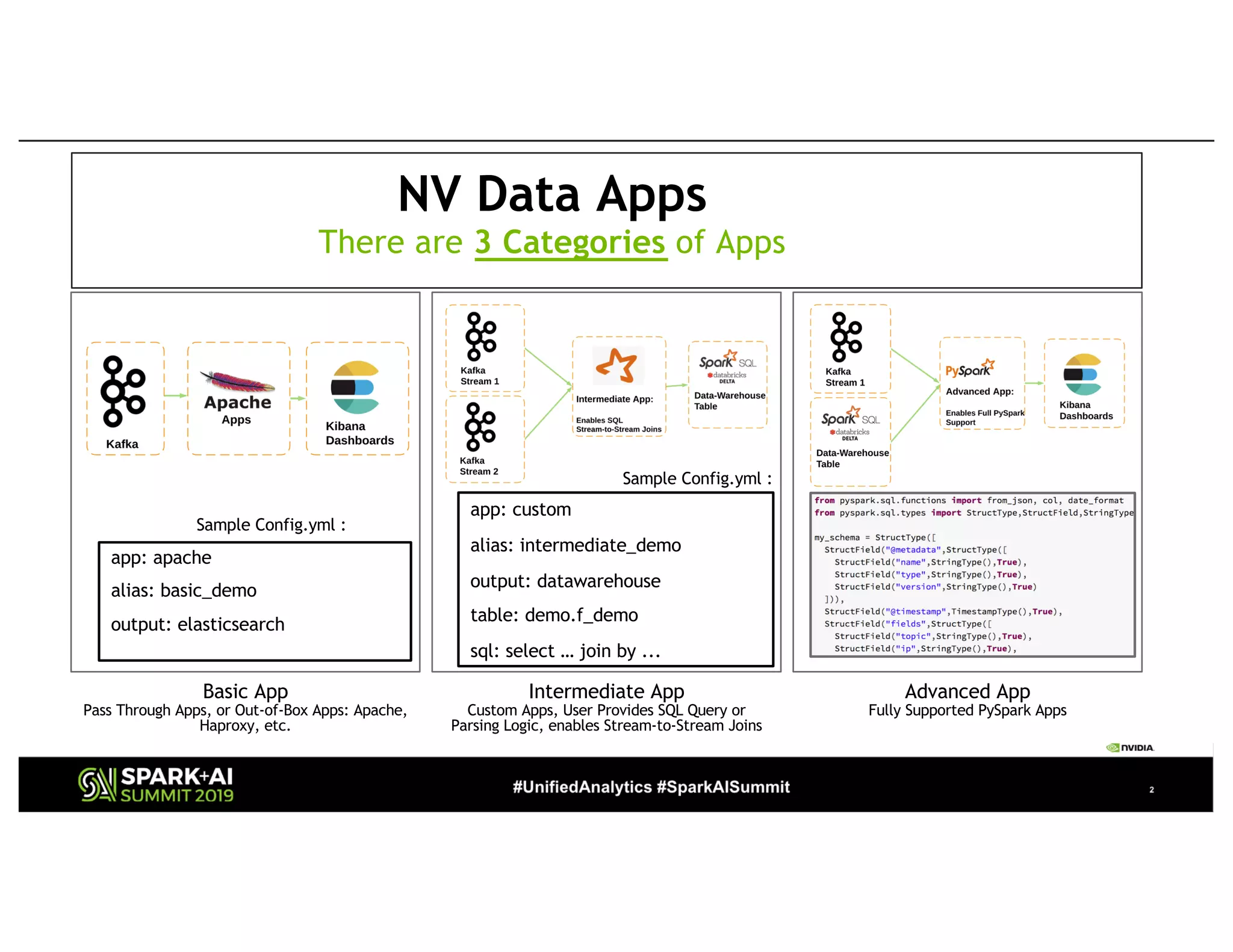
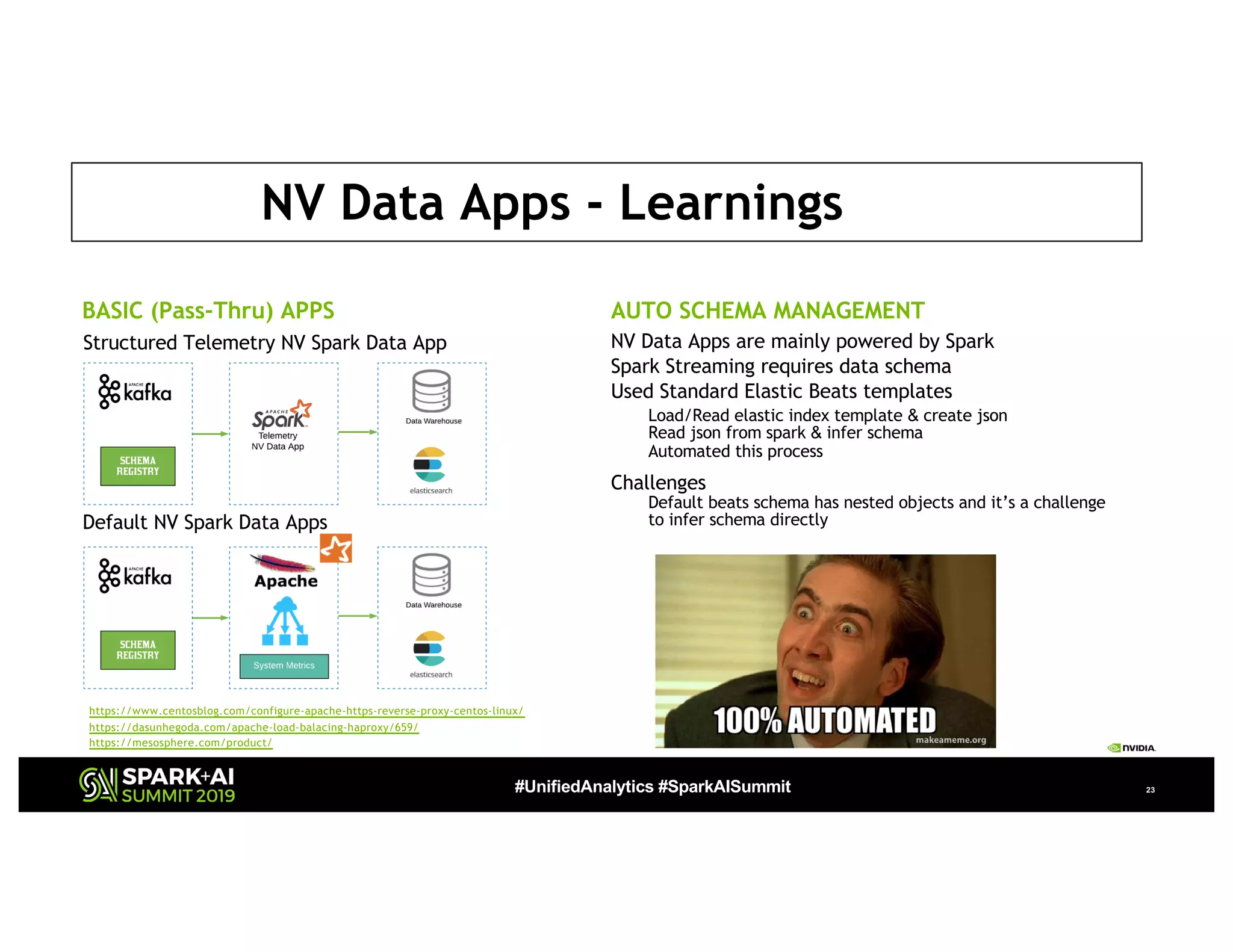
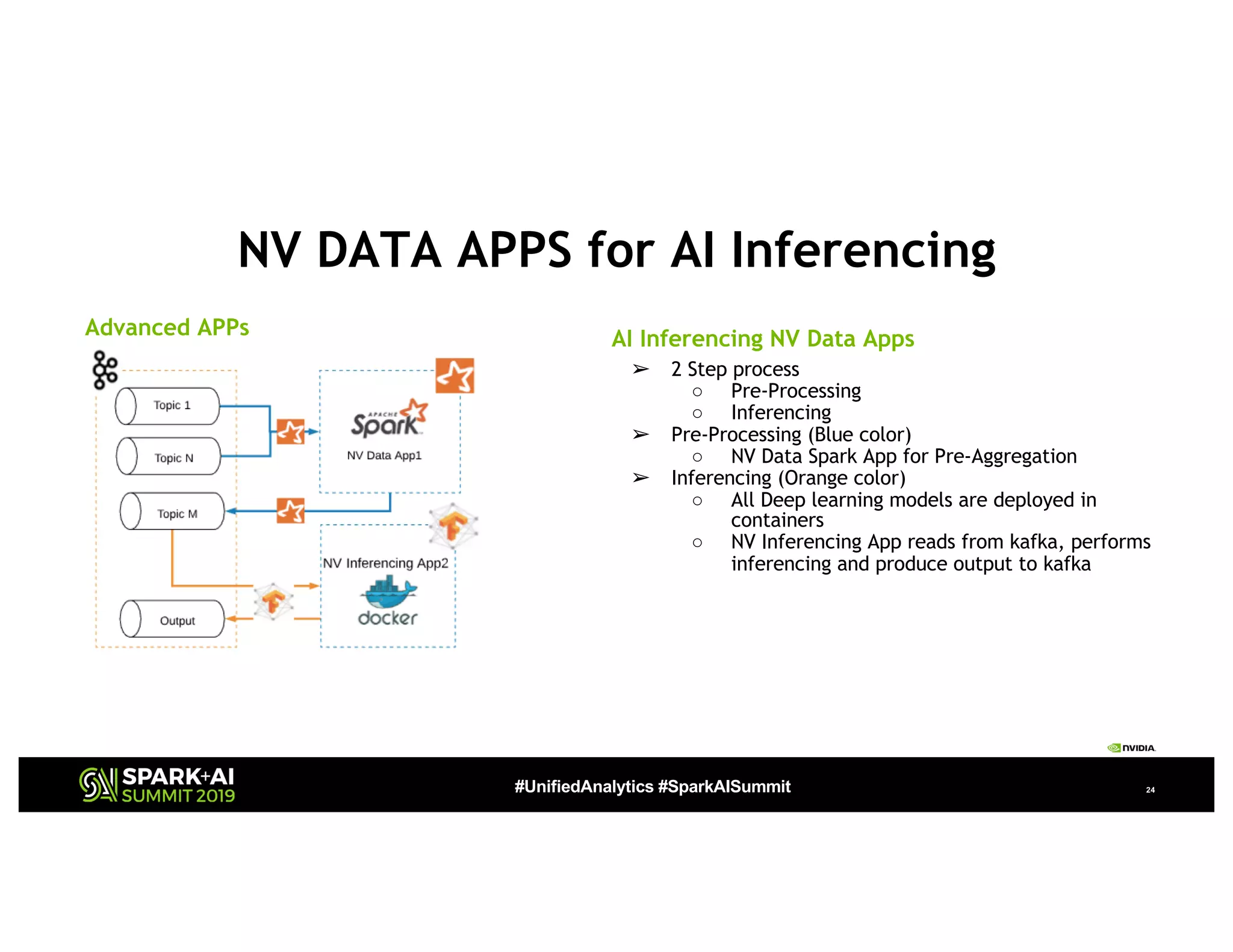
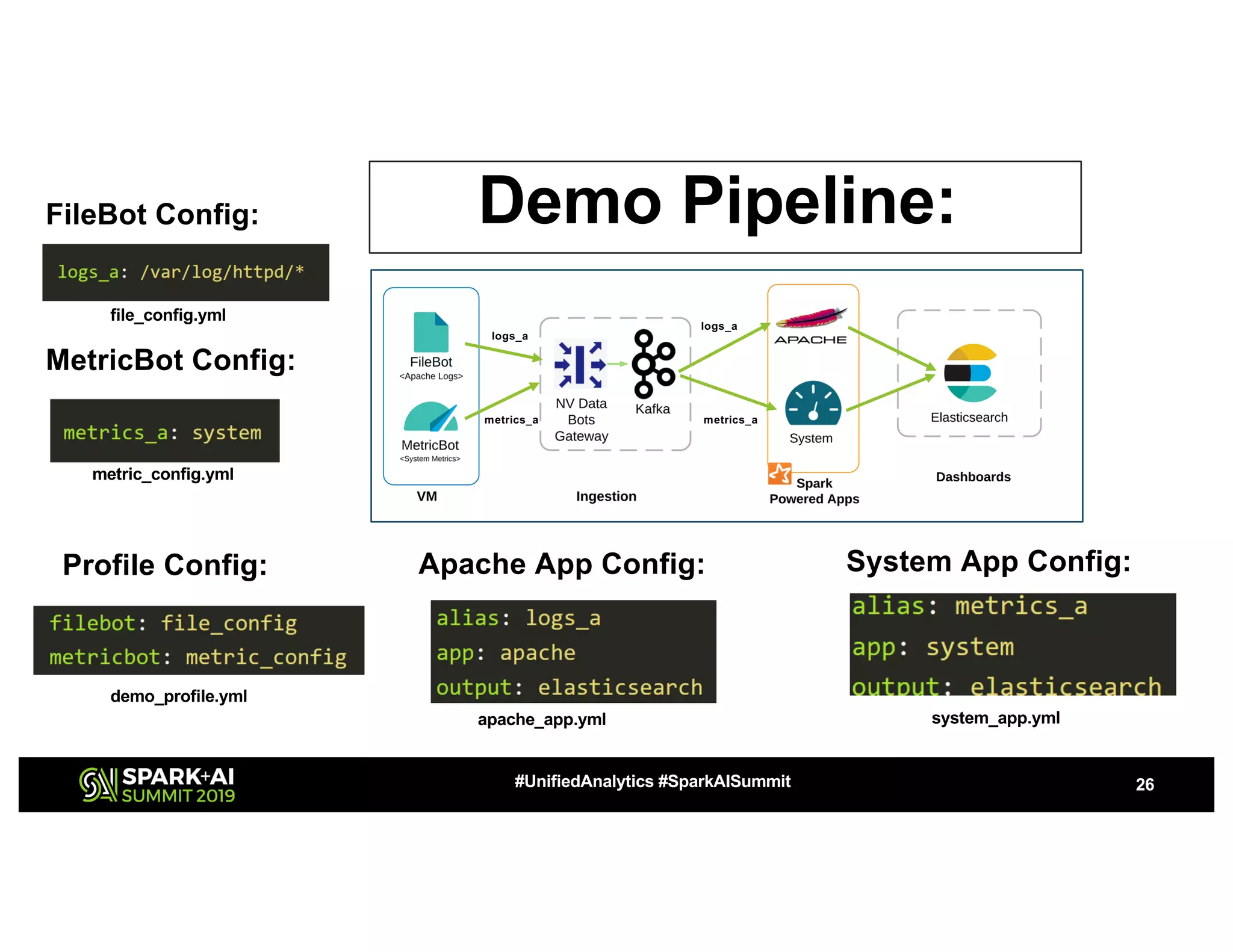
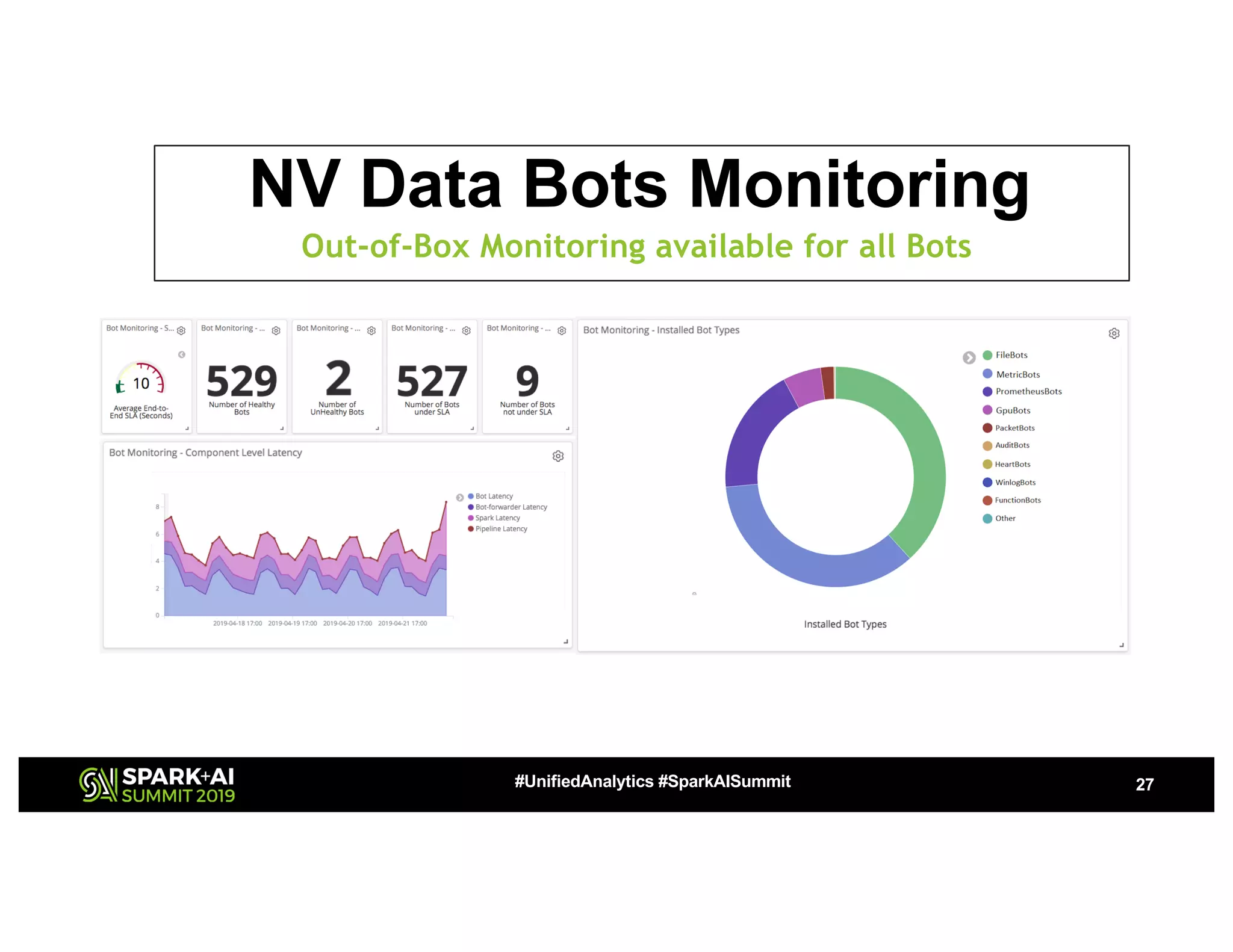
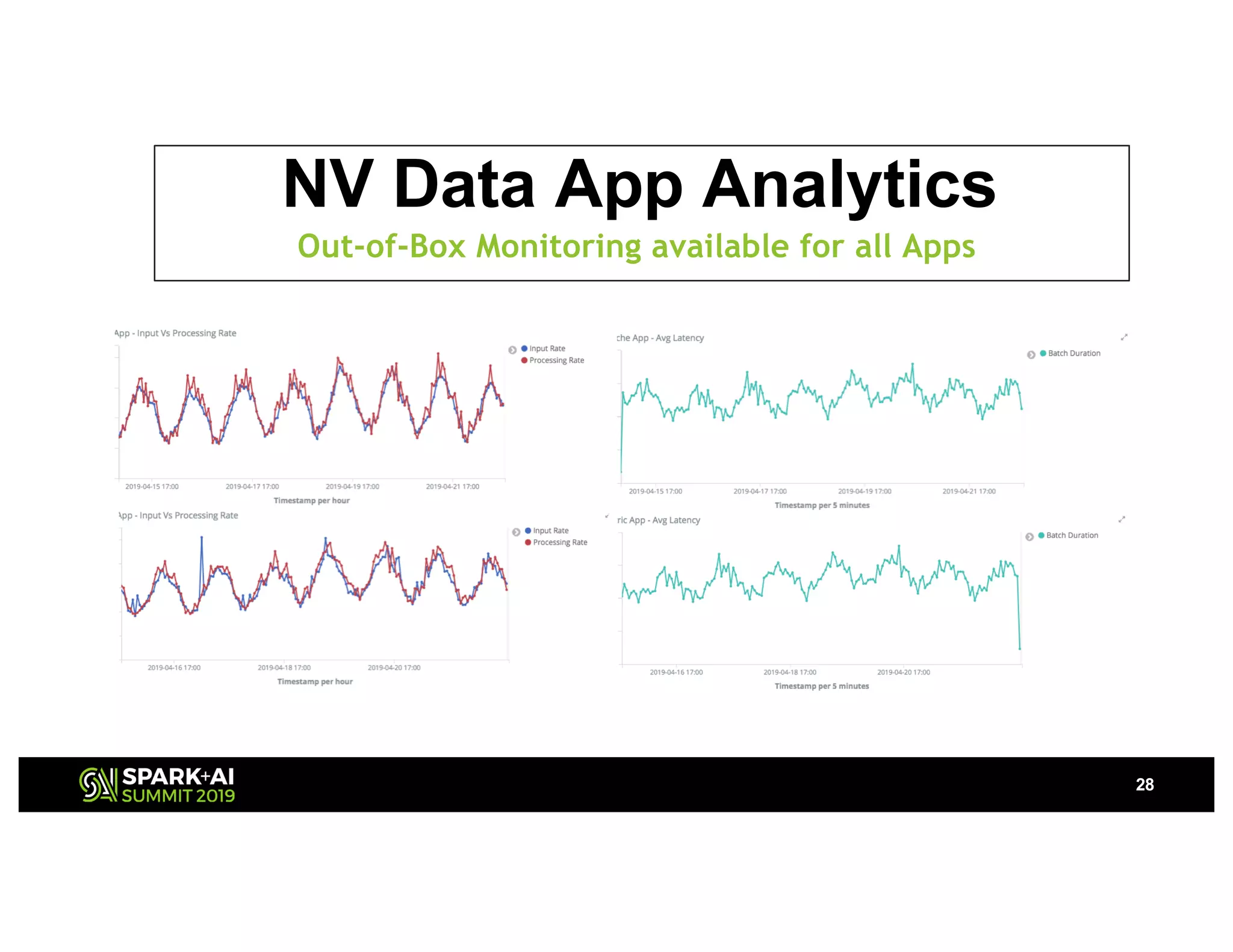
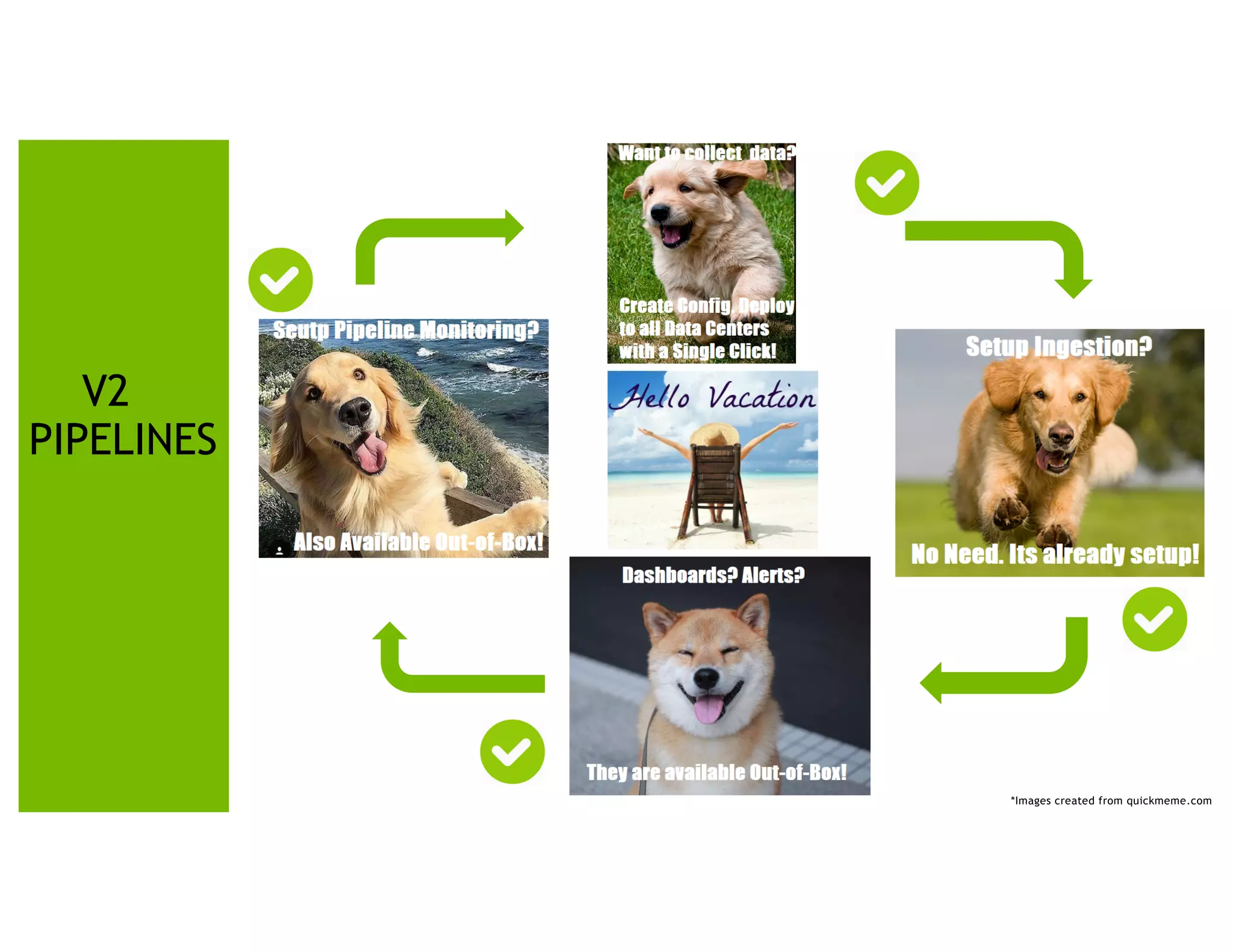

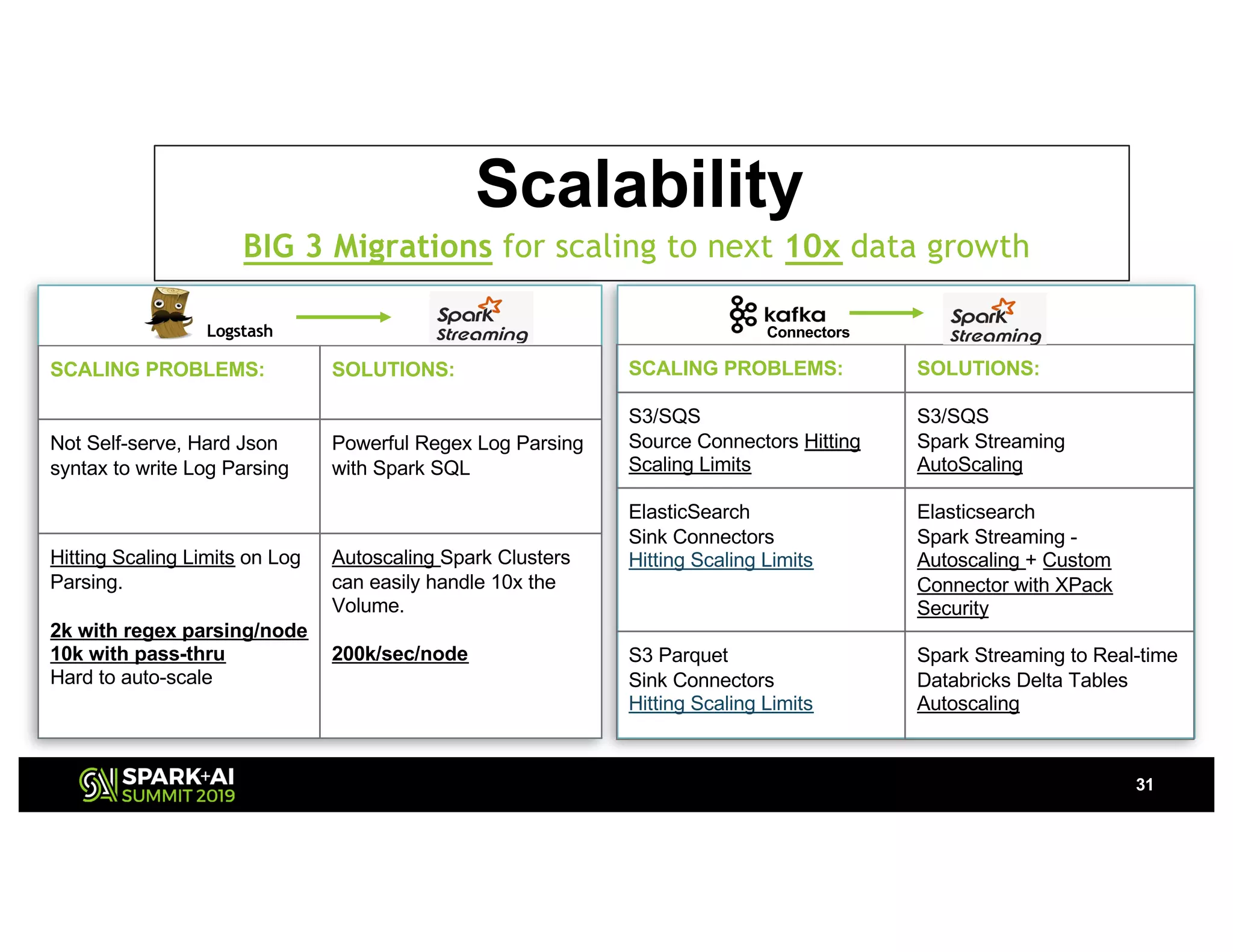
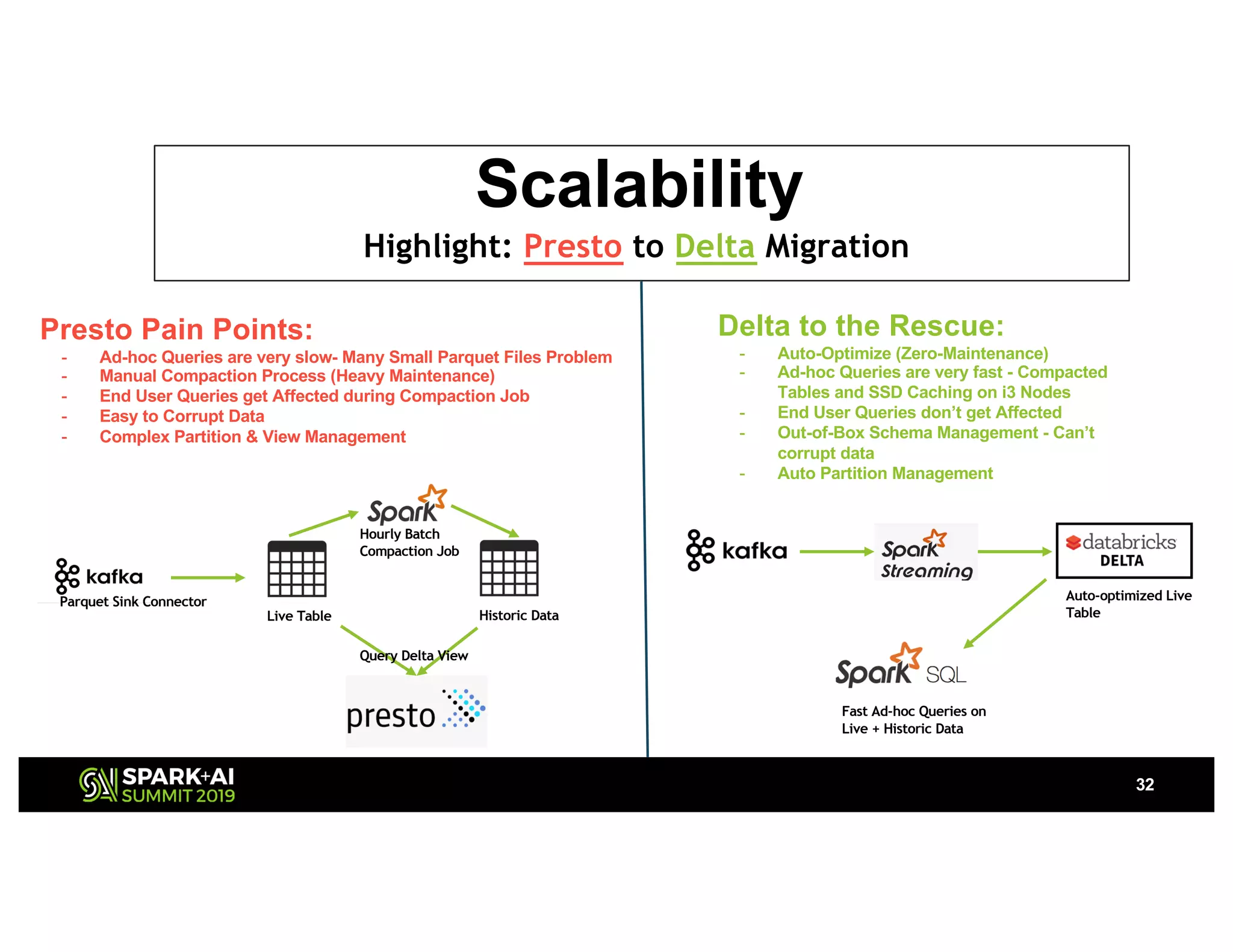


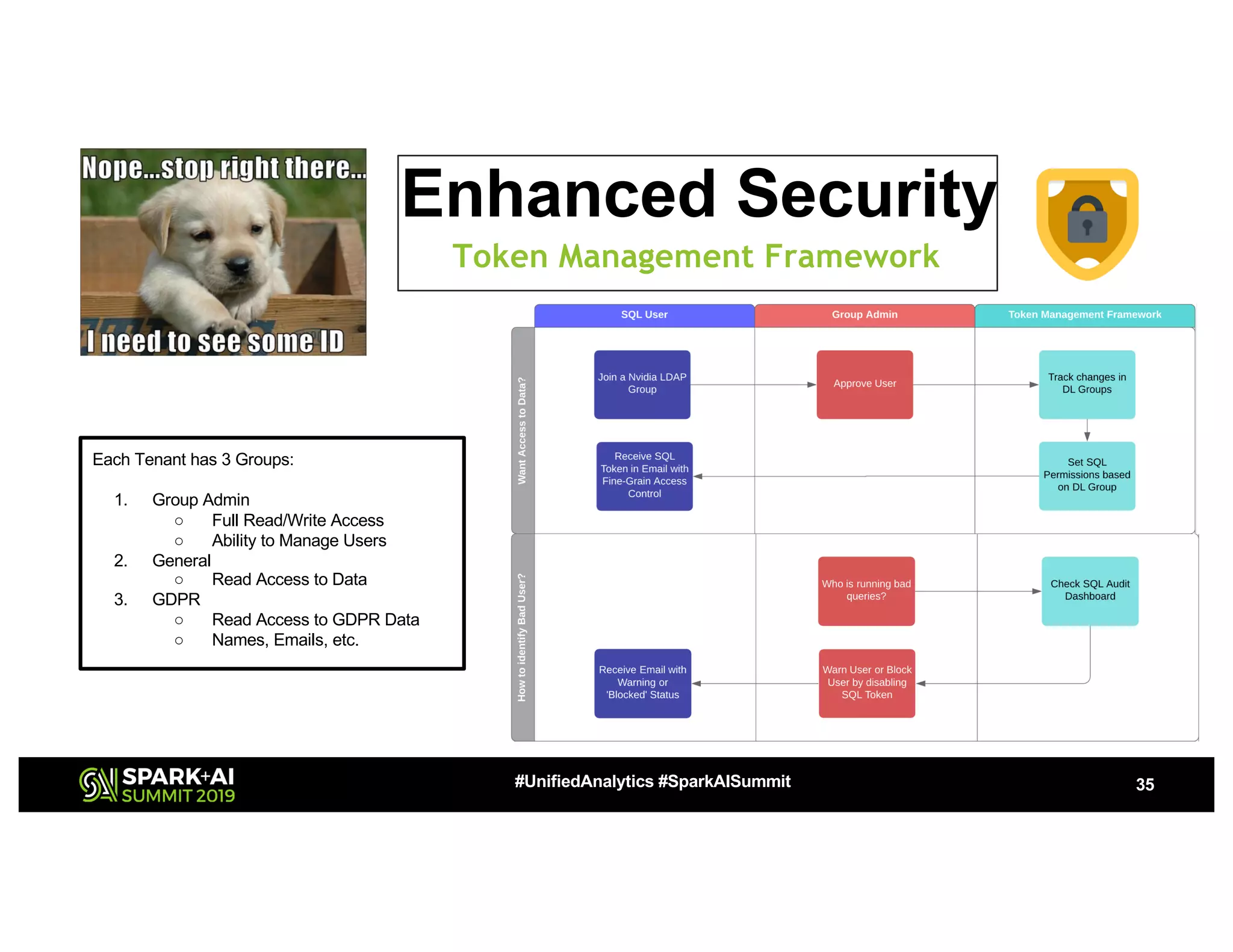
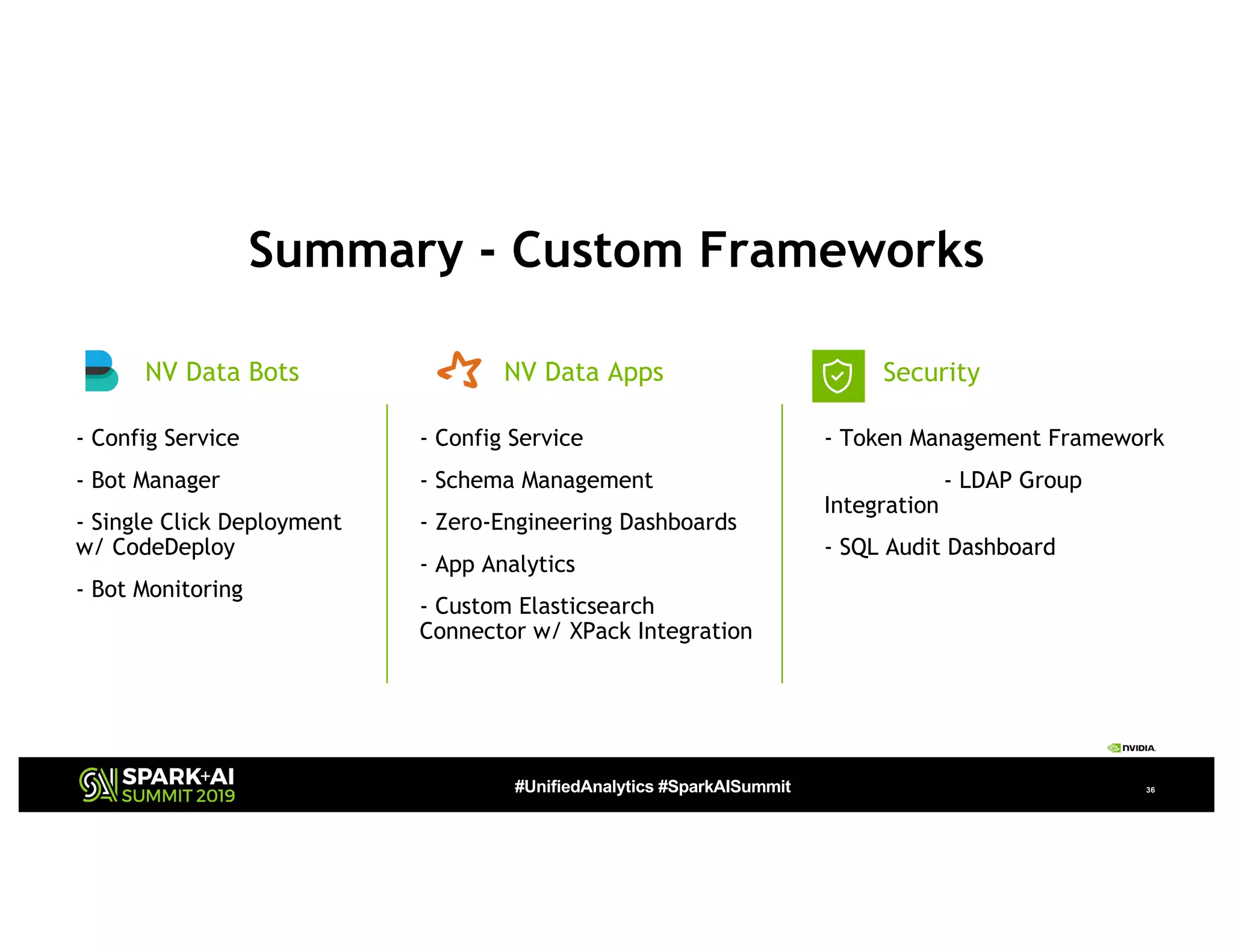





The document presents a detailed overview of Nvidia's autonomous streaming data platform, highlighting its evolution from version 1.0 to 2.0, which includes enhancements in scalability, architecture, self-service capabilities, and security features that accommodate significant data growth. The discussion centers around a data platform-as-a-service model that processes trillions of events monthly while emphasizing lessons learned and innovations in data management and security. The presentation also outlines key features such as automated data tools, bots for data shipping, and self-service applications for efficient data processing.














![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)





















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Sara Polak - The Archaeology of Innovation: AI as the Next Cr...](https://cdn.slidesharecdn.com/ss_thumbnails/7ecbscdnt8mlcuqbd2ln-2-sara-polak-ai-creative-industries-251208152533-aa1fcf54-thumbnail.jpg?width=640&height=640&fit=bounds)