


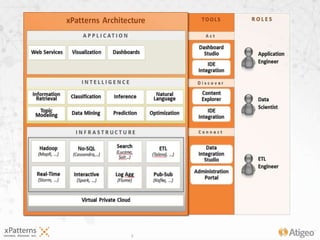
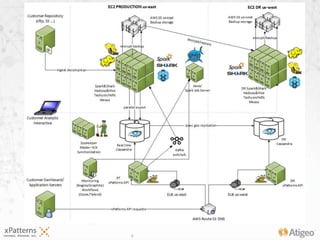



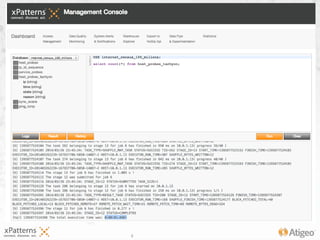

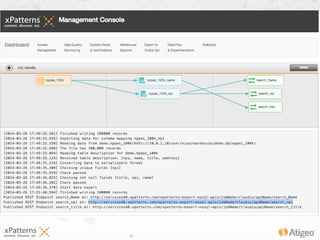

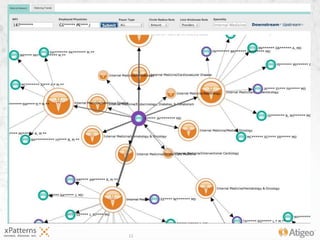
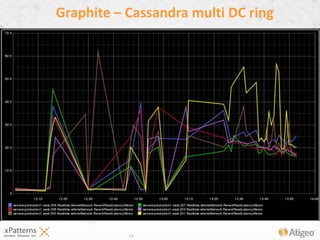
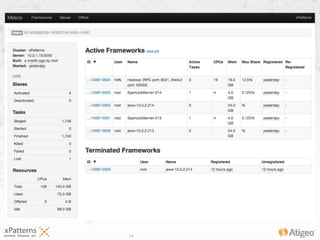
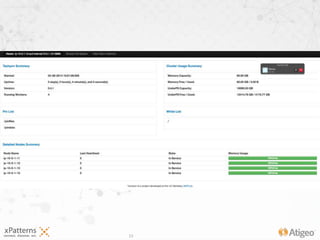



The document discusses the evolution of the xpatterns infrastructure, highlighting a transition from Hadoop and Hive to Spark, Shark, and Mesos for enhanced scalability and performance. Key improvements include faster data processing, significant reductions in daily processing times, and better resource management. Additionally, the document describes various components like dashboards, API tools, and applications designed for healthcare data analytics and visualization.















































































