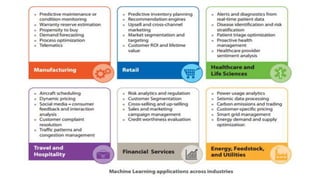
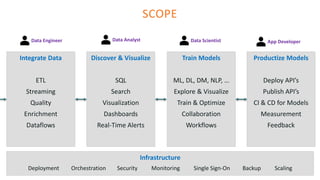
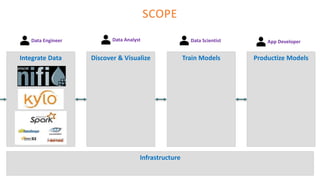
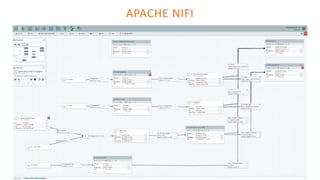
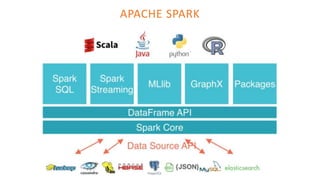
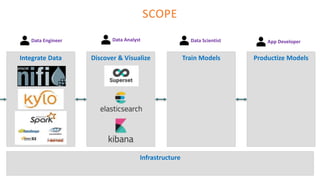
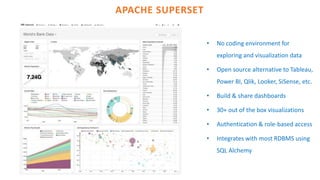
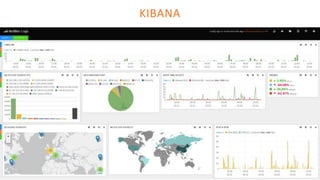
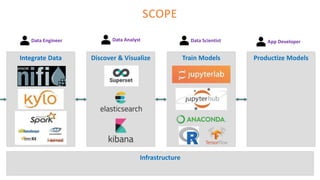
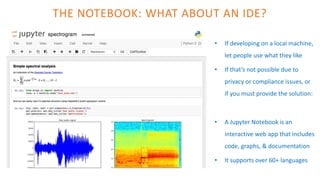
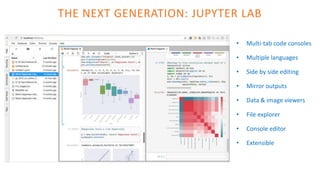
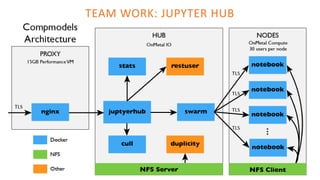
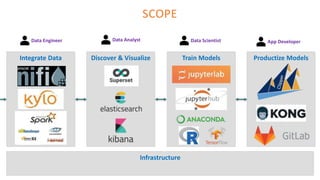
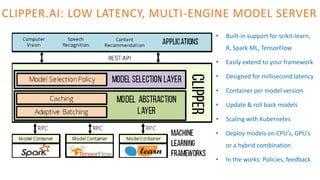
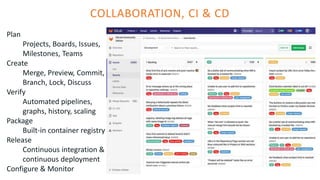
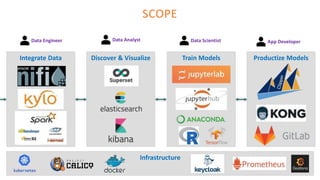
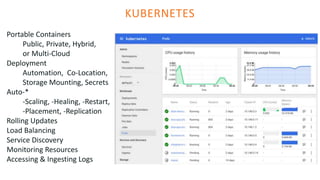
The document outlines the architecture of an open-source data science platform, detailing its components such as data integration, model training, and visualization tools. It emphasizes the use of technologies like Apache NiFi, Spark, and Jupyter for data processing and analysis, while discussing deployment considerations with Kubernetes and API management. The platform aims for enterprise scalability and modularity without relying on commercial software, advocating for incremental evolution over time.






















































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)









![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)