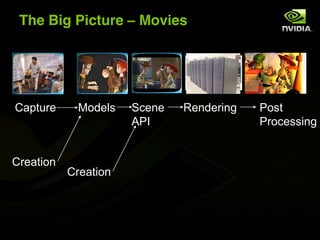
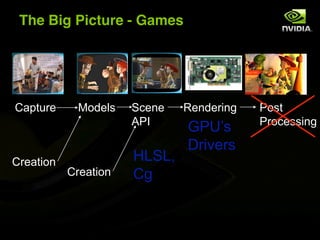
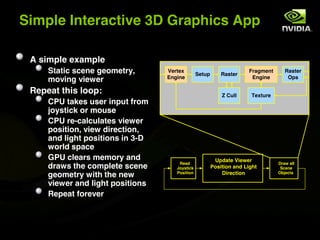
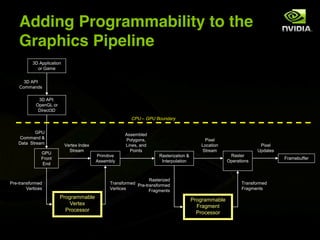
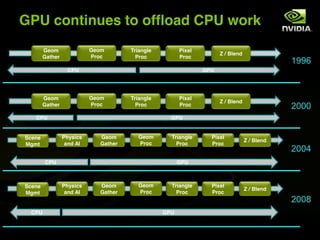
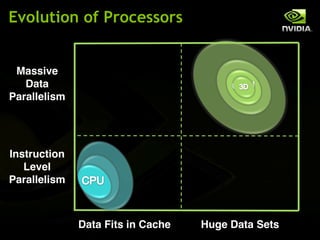
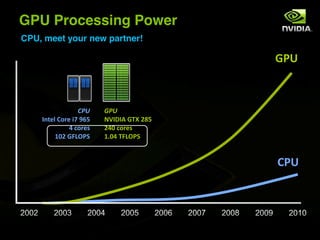
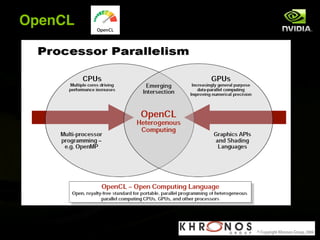
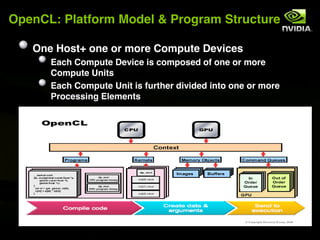
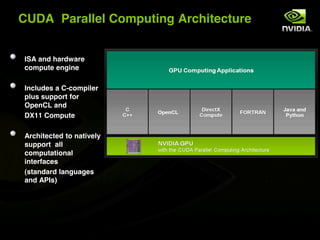
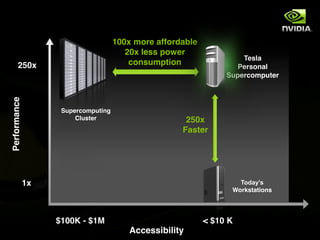
The document discusses the history and evolution of 3D graphics technologies including OpenGL and DirectX, provides an overview of GPU programming models and architectures, and explores how GPUs are increasingly being used for general purpose computing beyond just graphics through technologies like CUDA and OpenCL. It also highlights how GPUs can provide significant performance gains for parallel applications compared to CPUs.












































![[GDC 2012] Enhancing Graphics in Unreal Engine 3 Titles Using AMD Code Submis...](https://cdn.slidesharecdn.com/ss_thumbnails/enhancinggraphicsinunrealengine3titlesusingnewcodesubmissions-150222111053-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Unite Seoul 2019] Mali GPU Architecture and Mobile Studio](https://cdn.slidesharecdn.com/ss_thumbnails/maligpuarchitectureandmobilestudiofinal3-190717042828-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Unite Seoul 2020] Mobile Graphics Best Practices for Artists](https://cdn.slidesharecdn.com/ss_thumbnails/arm-uniteseoul2020final-210524084305-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[03 1][gpu용 개발자 도구 - parallel nsight 및 axe] miller axe](https://cdn.slidesharecdn.com/ss_thumbnails/03-1gpu-parallelnsightaxemilleraxe-110106231332-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















