Downloaded 46 times












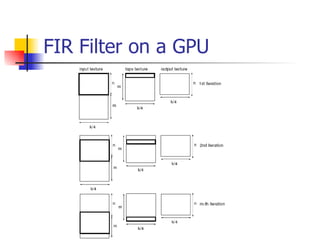




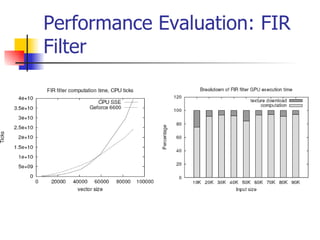
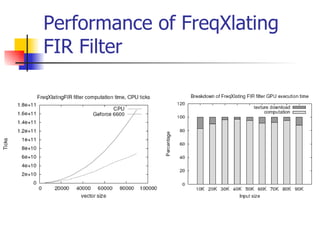
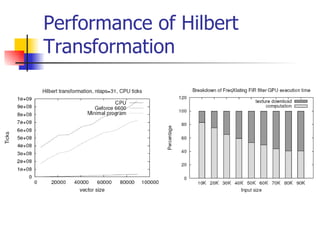



This document discusses the implementation of a finite impulse response (FIR) filter on a graphics processing unit (GPU). It outlines how FIR filters can be represented using textures on the GPU and implemented using fragment programs. The performance of FIR filters and related transformations implemented on the GPU is evaluated. Texture upload and download between GPU and main memory accounts for up to 60% of the total processing time. While GPU computation is faster than CPU for these algorithms, optimization techniques from CPU programming do not always apply to the GPU.



































































