Downloaded 71 times










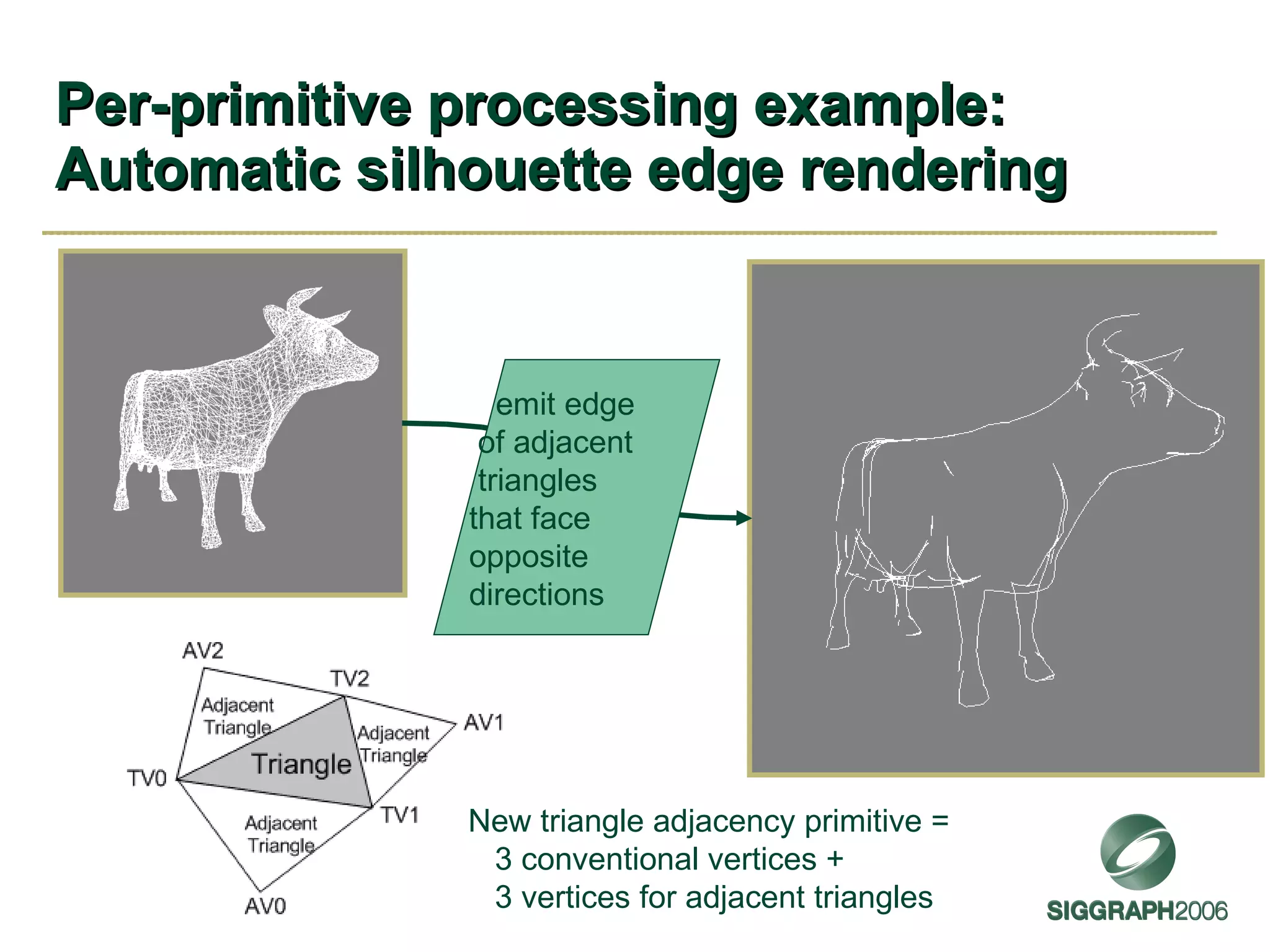









![Pass Through Geometry Program Example BufferInit<float4,6> flatColor; TRIANGLE void passthru( AttribArray < float4 > position : POSITION , AttribArray < float4 > texCoord : TEXCOORD0 ) { flatAttrib (flatColor: COLOR ); for ( int i=0; i<position.length; i++) { emitVertex (position[i], texCoord[i]); } } Primitive’s attributes arrive as “templated” attribute arrays Length of attribute arrays depends on the input primitive mode, 3 for TRIANGLE Bundles a vertex based on parameter values and semantics Makes sure flat attributes are associated with the proper provoking vertex convention flatColor initialized from constant buffer 6](https://image.slidesharecdn.com/sg2006kilgard-091013111546-phpapp02/75/NVIDIA-Graphics-Cg-and-Transparency-40-2048.jpg)
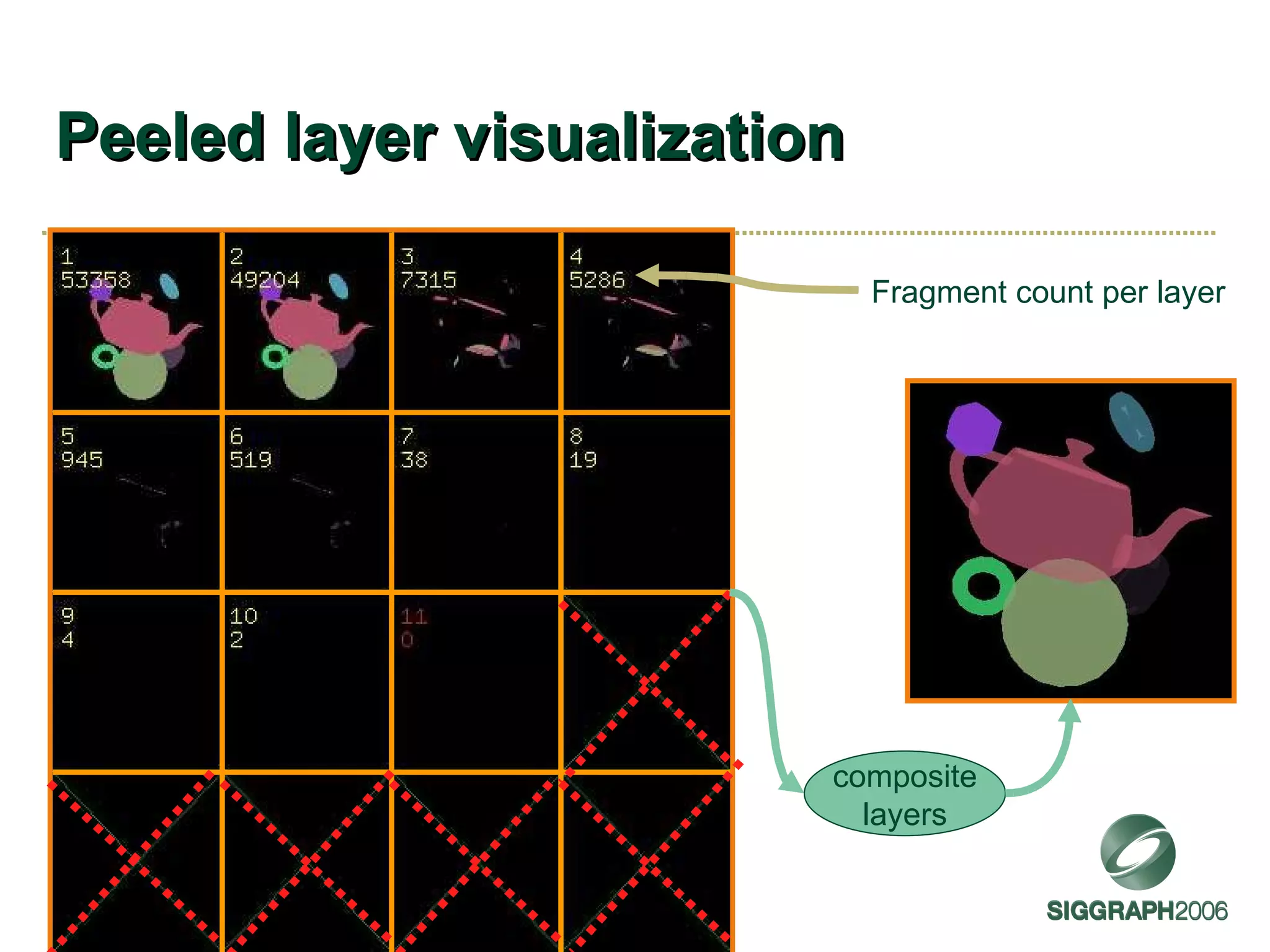
![Depth peeling Brute force order-independent transparency algorithm [Everitt 2001] Approach Render transparent objects repeatedly Each pass peels successive color layer using dual-depth buffers Composite peeled layers in order Caveats Typically makes “thin film” assumption No refraction or scattering](https://image.slidesharecdn.com/sg2006kilgard-091013111546-phpapp02/75/NVIDIA-Graphics-Cg-and-Transparency-41-2048.jpg)

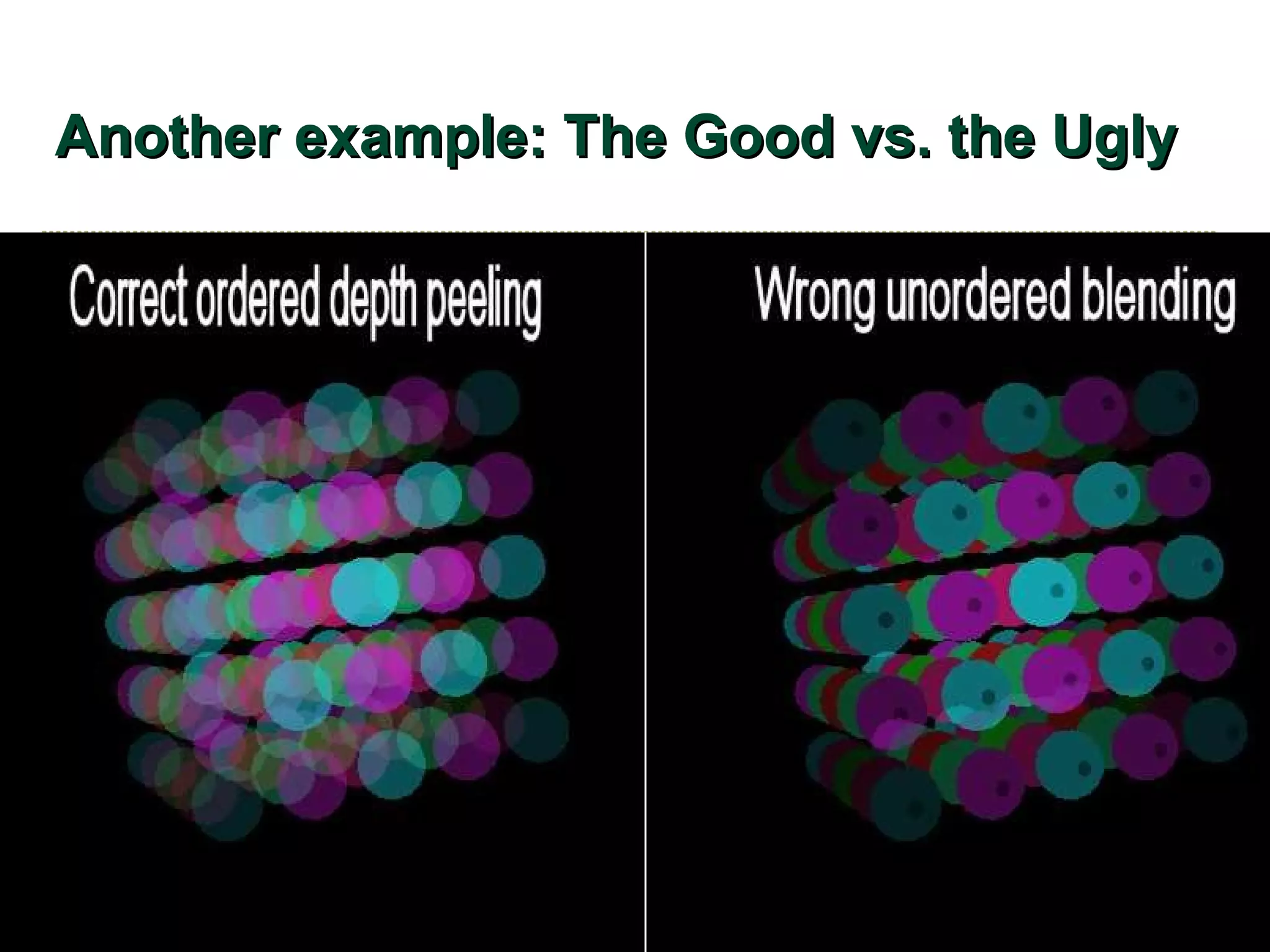
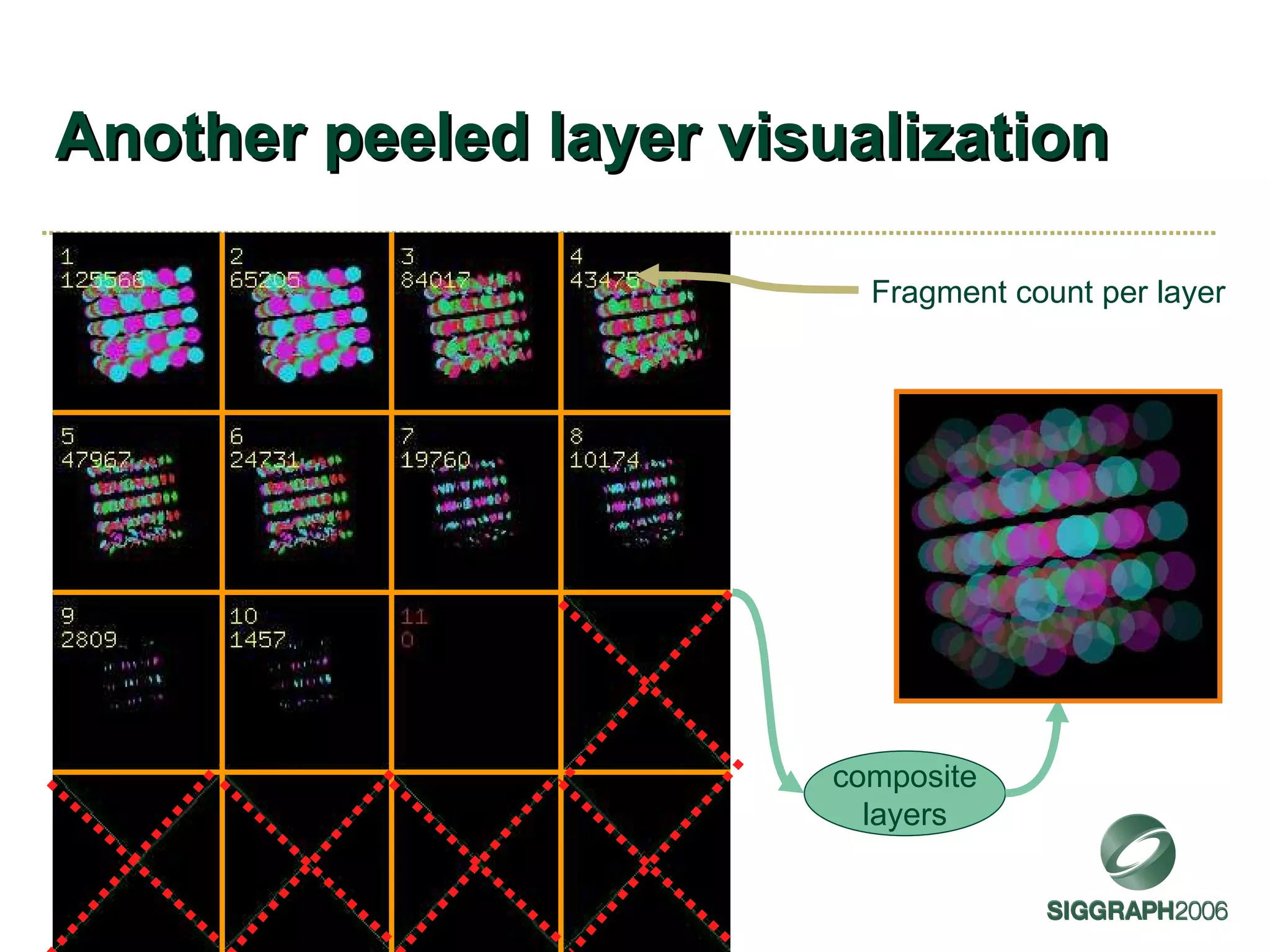






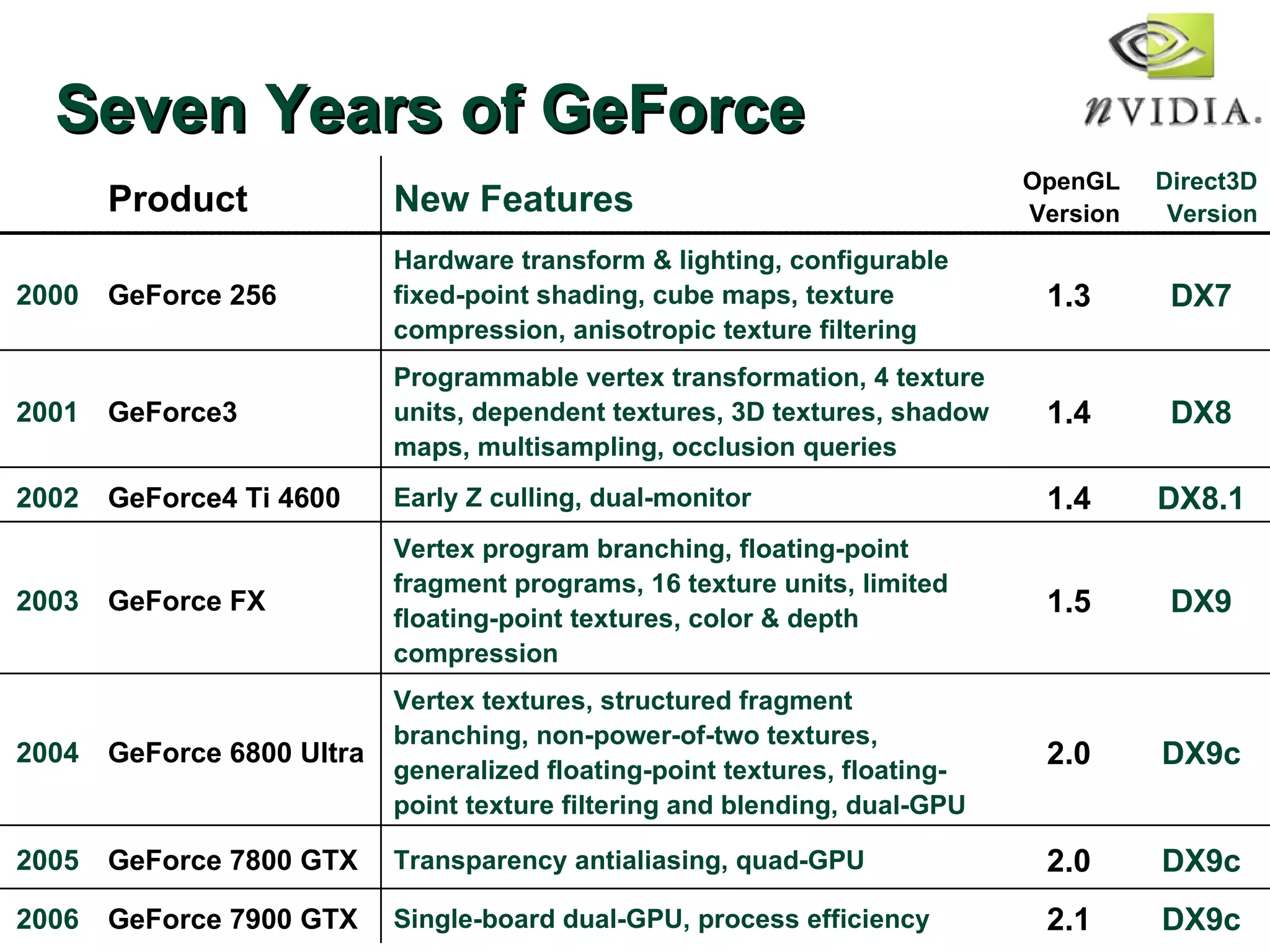
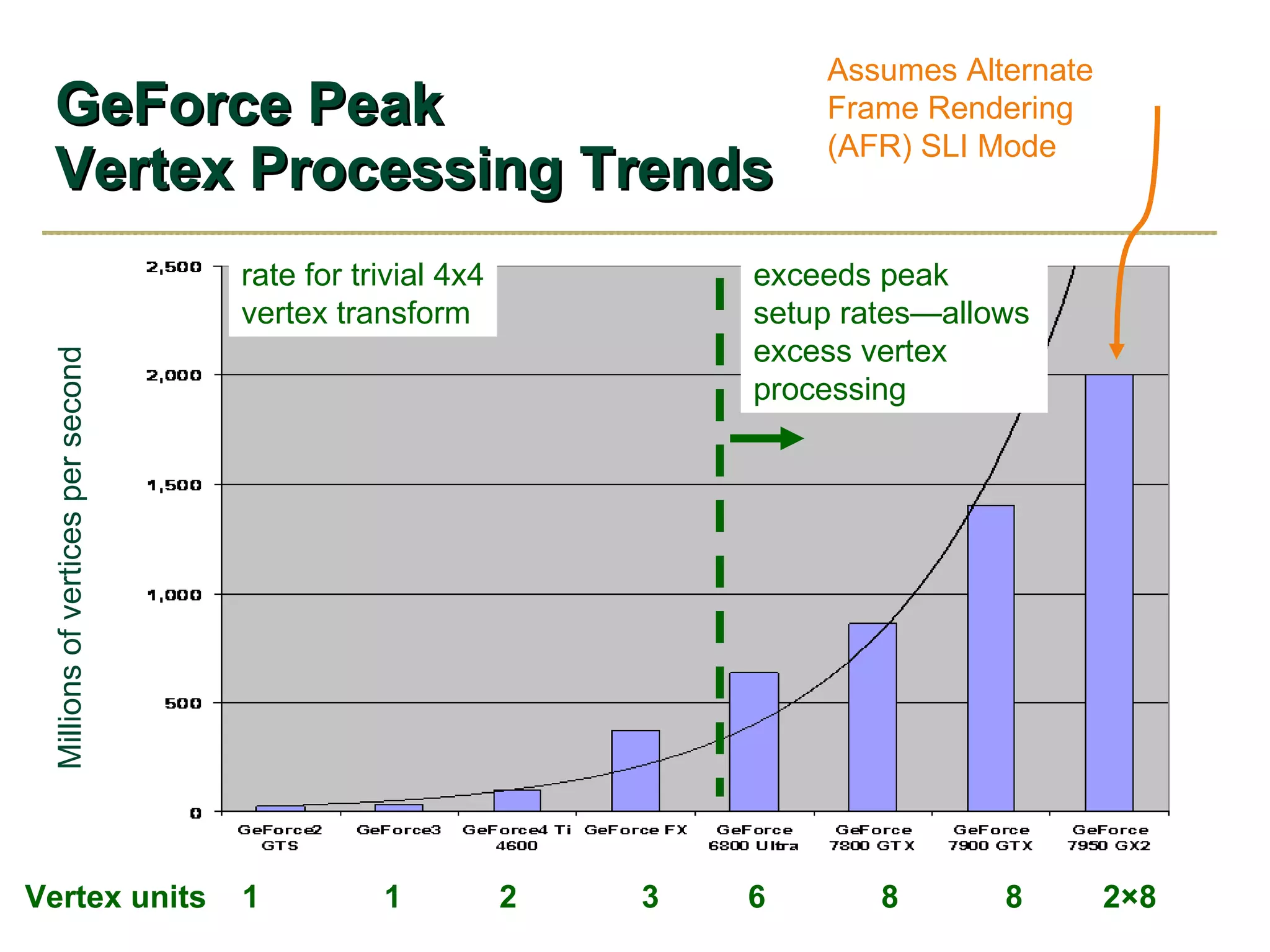
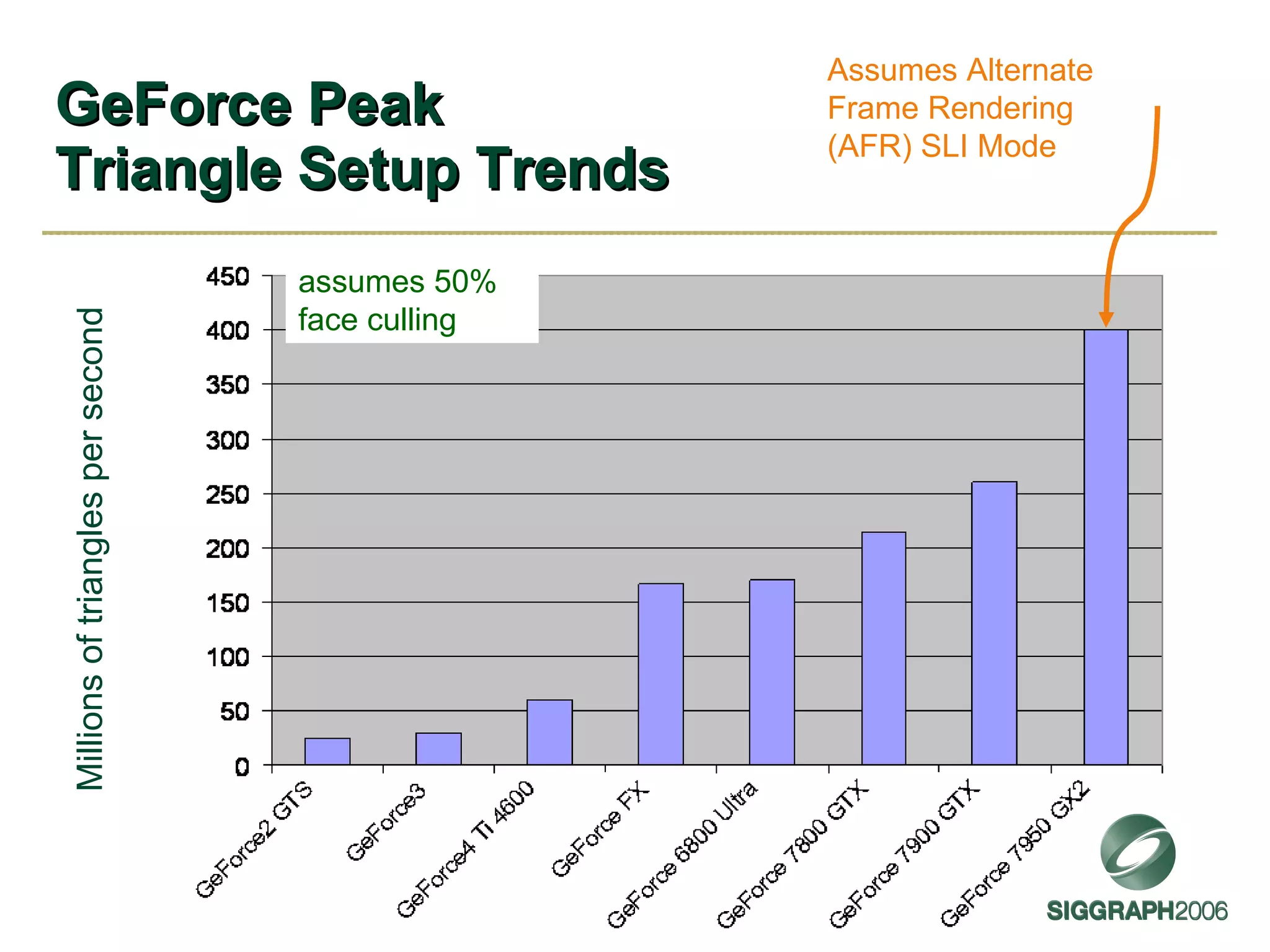
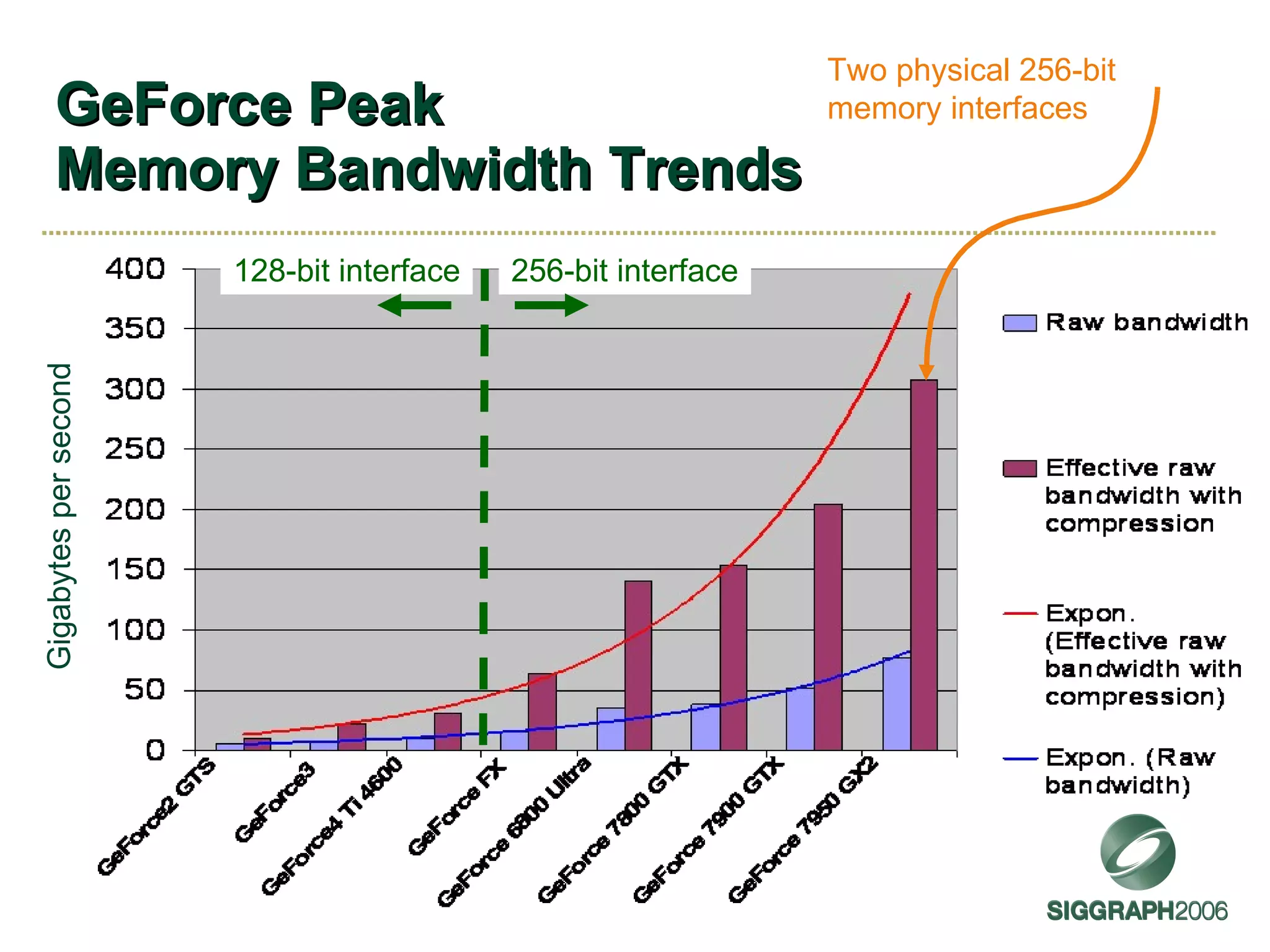
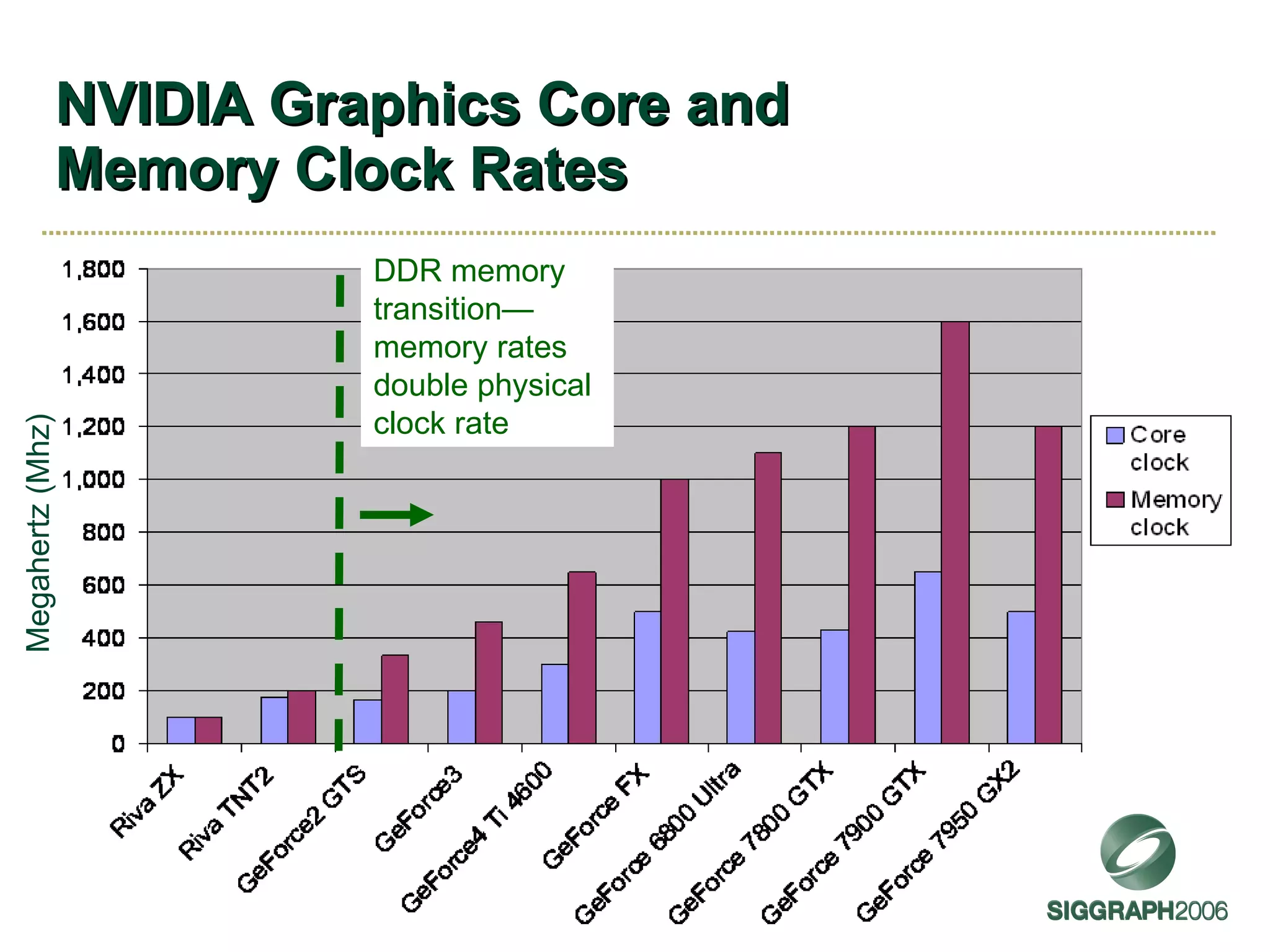
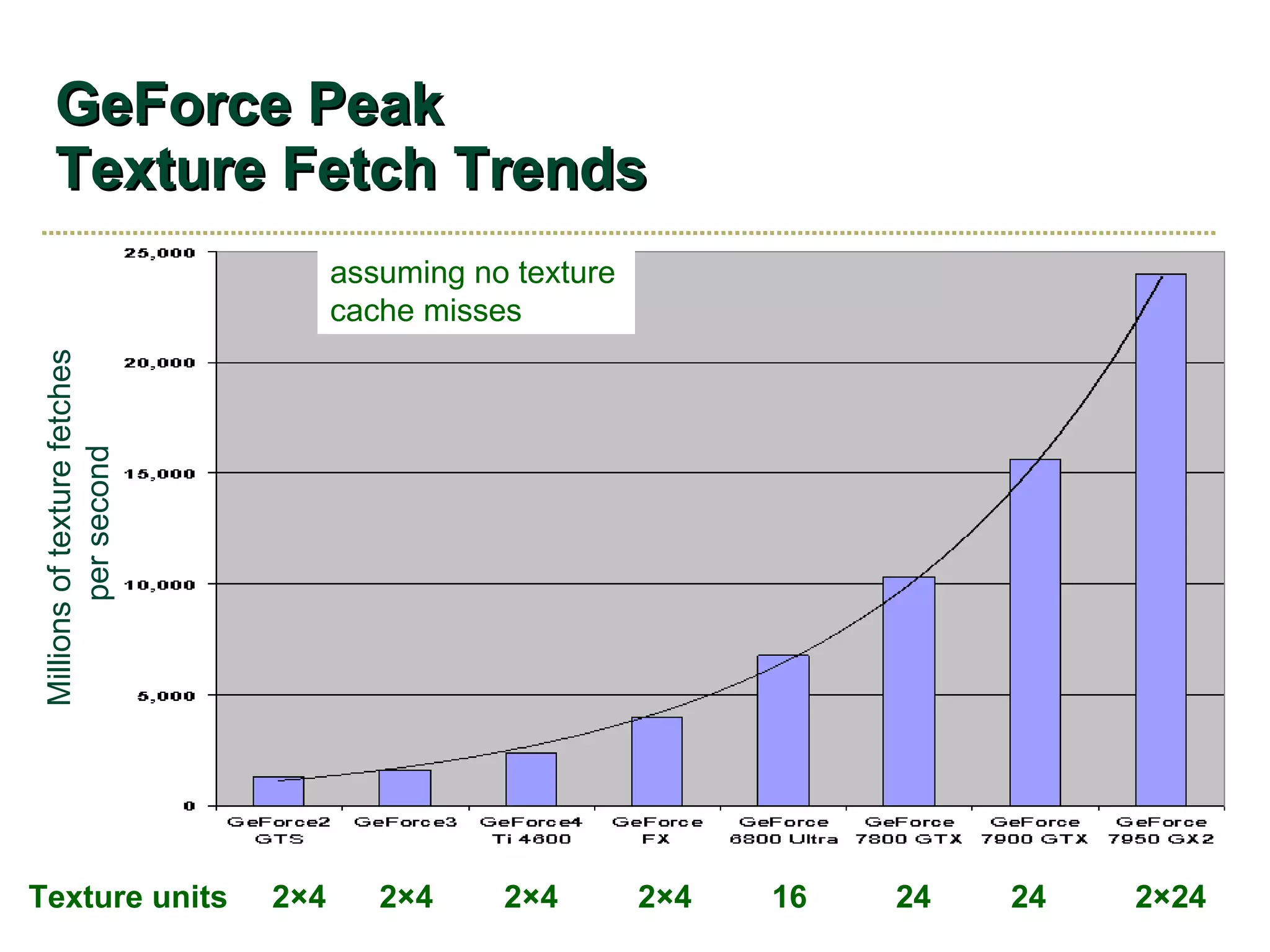
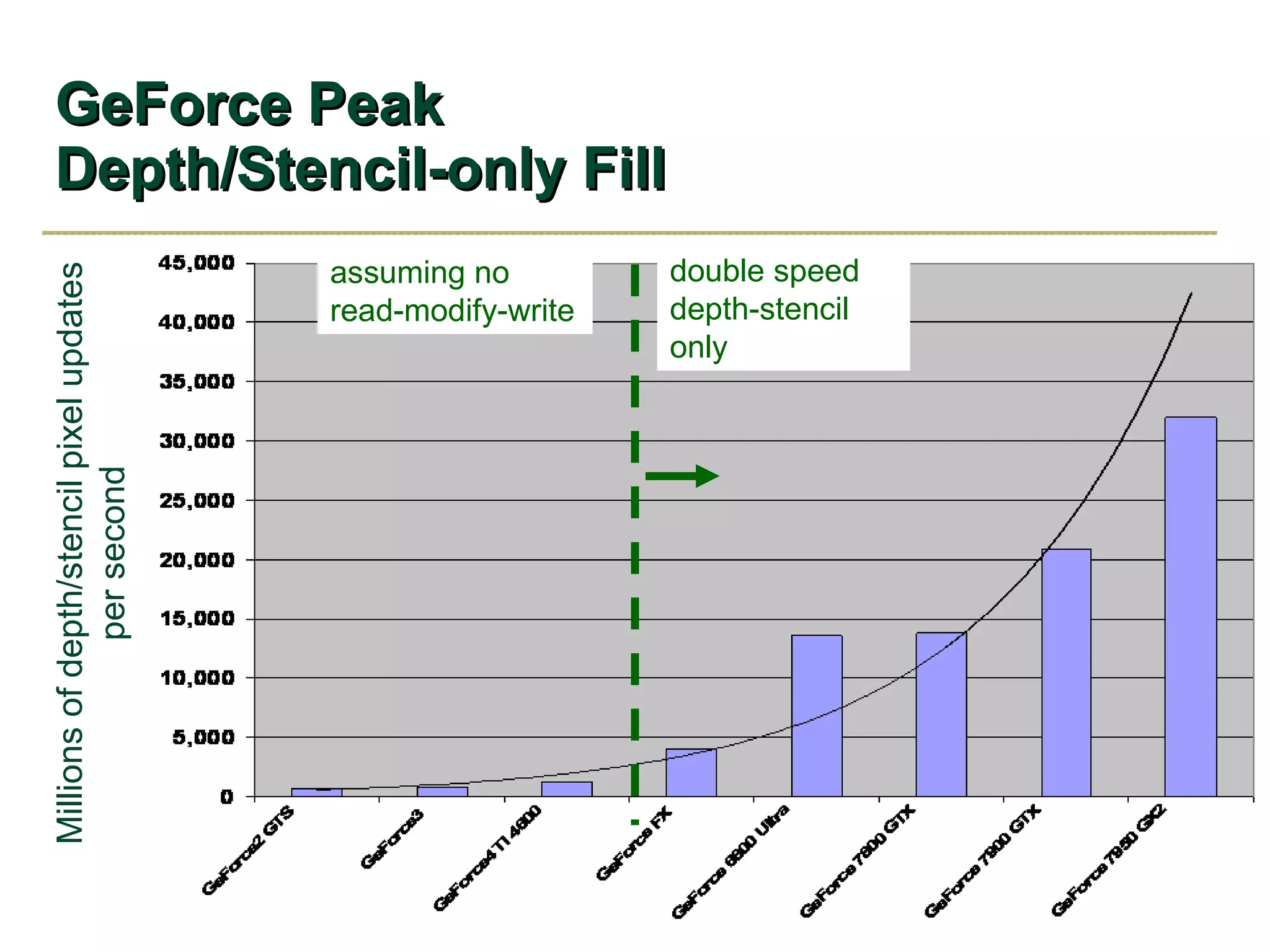
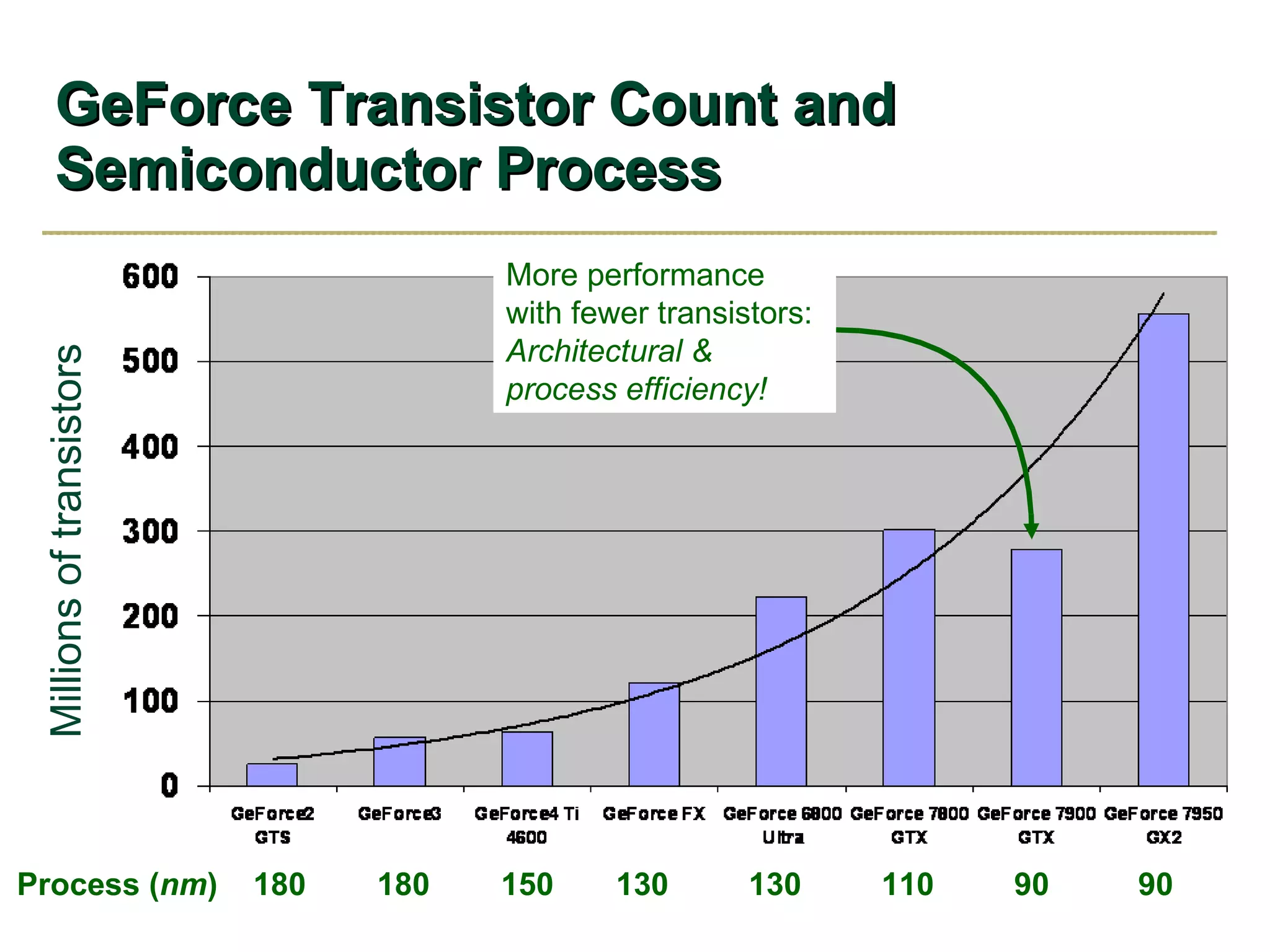
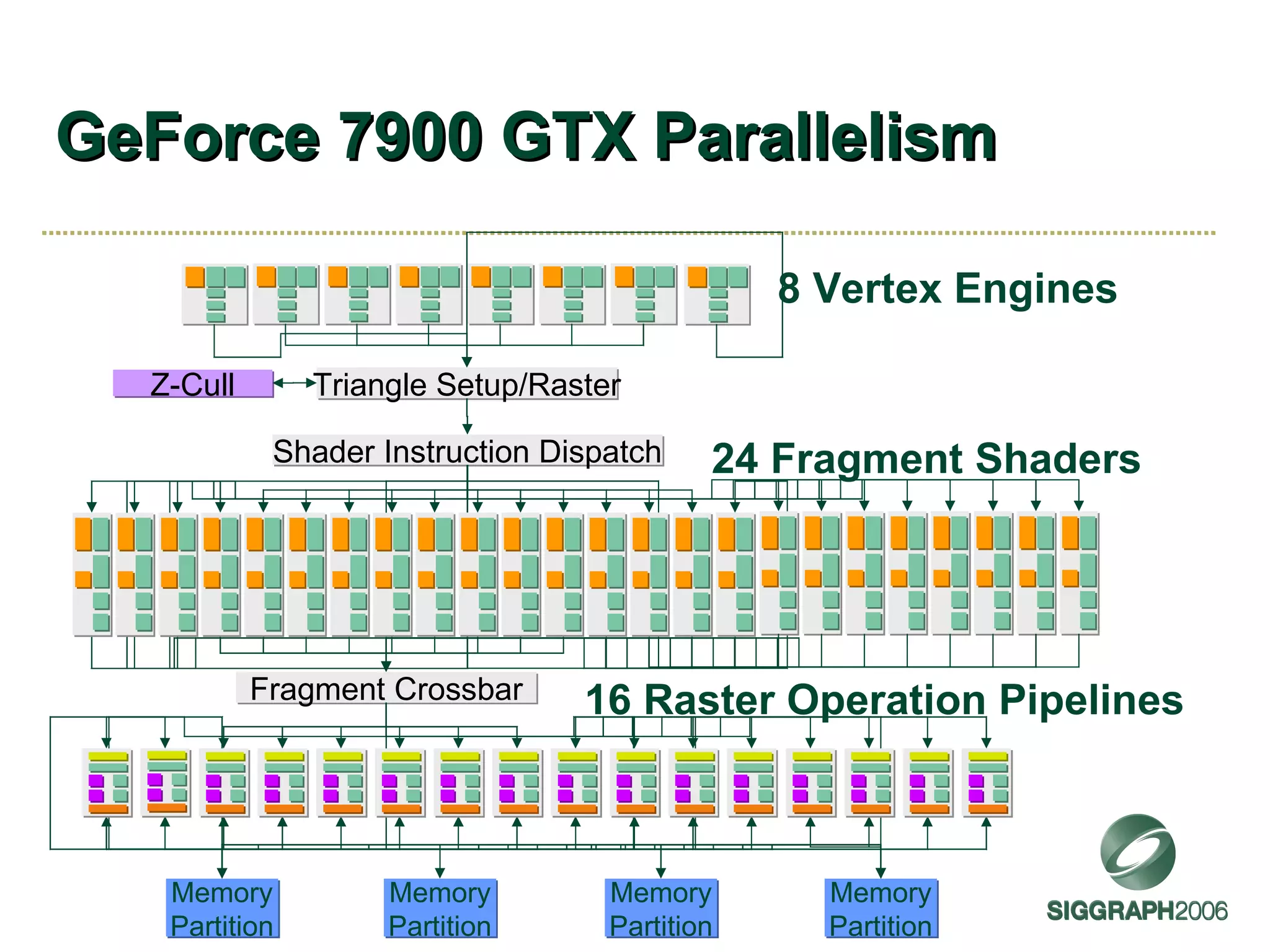
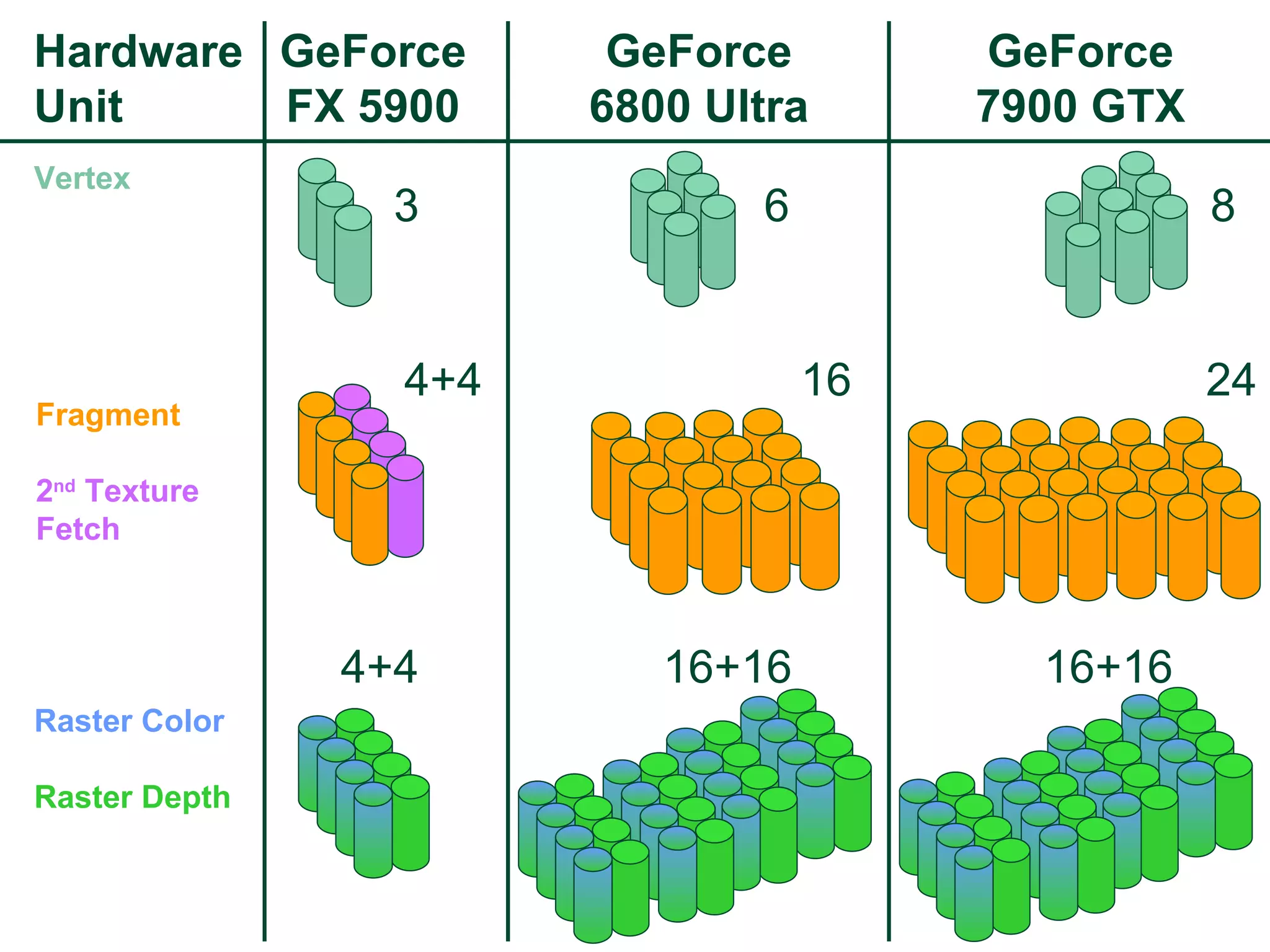
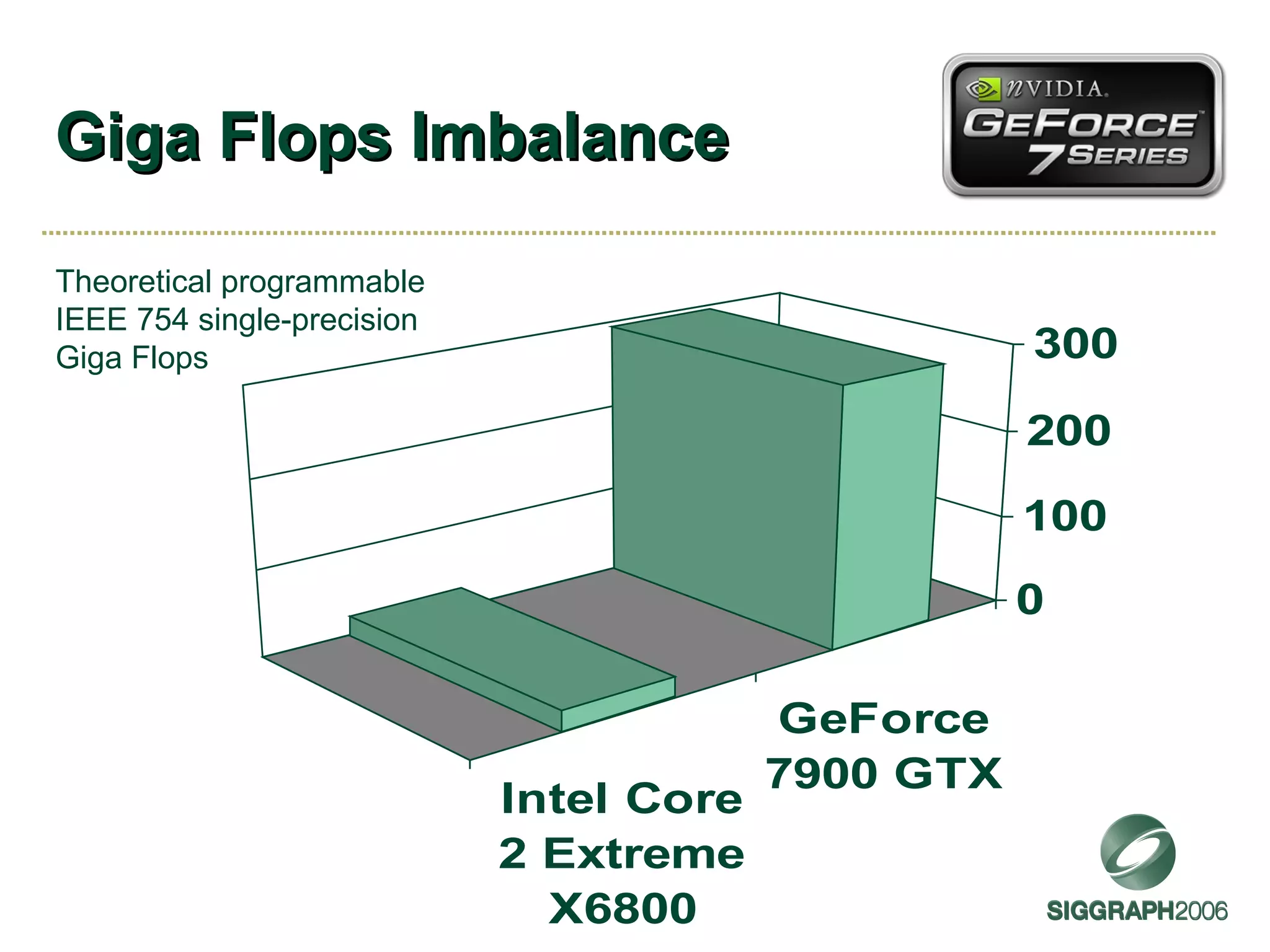
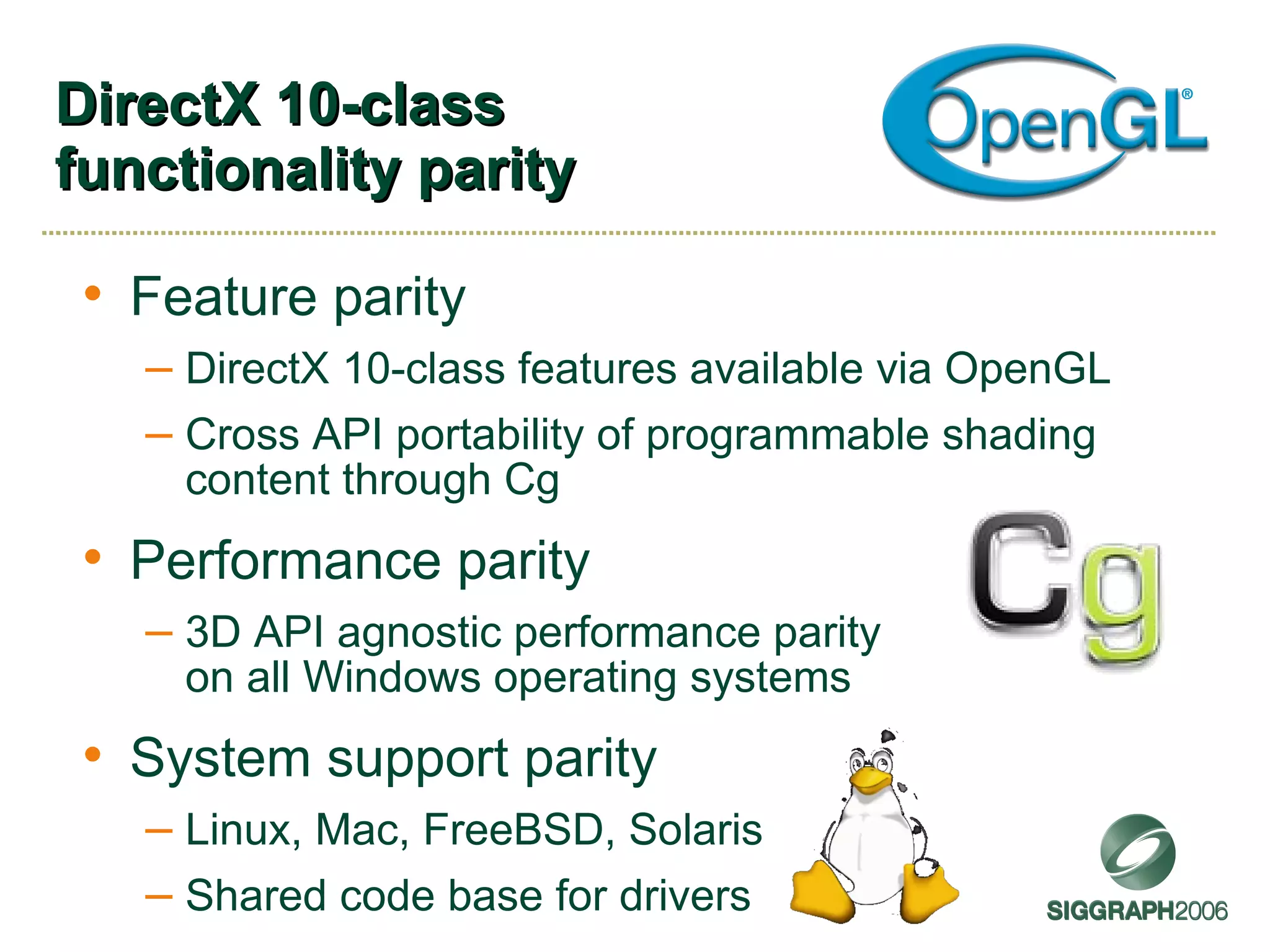
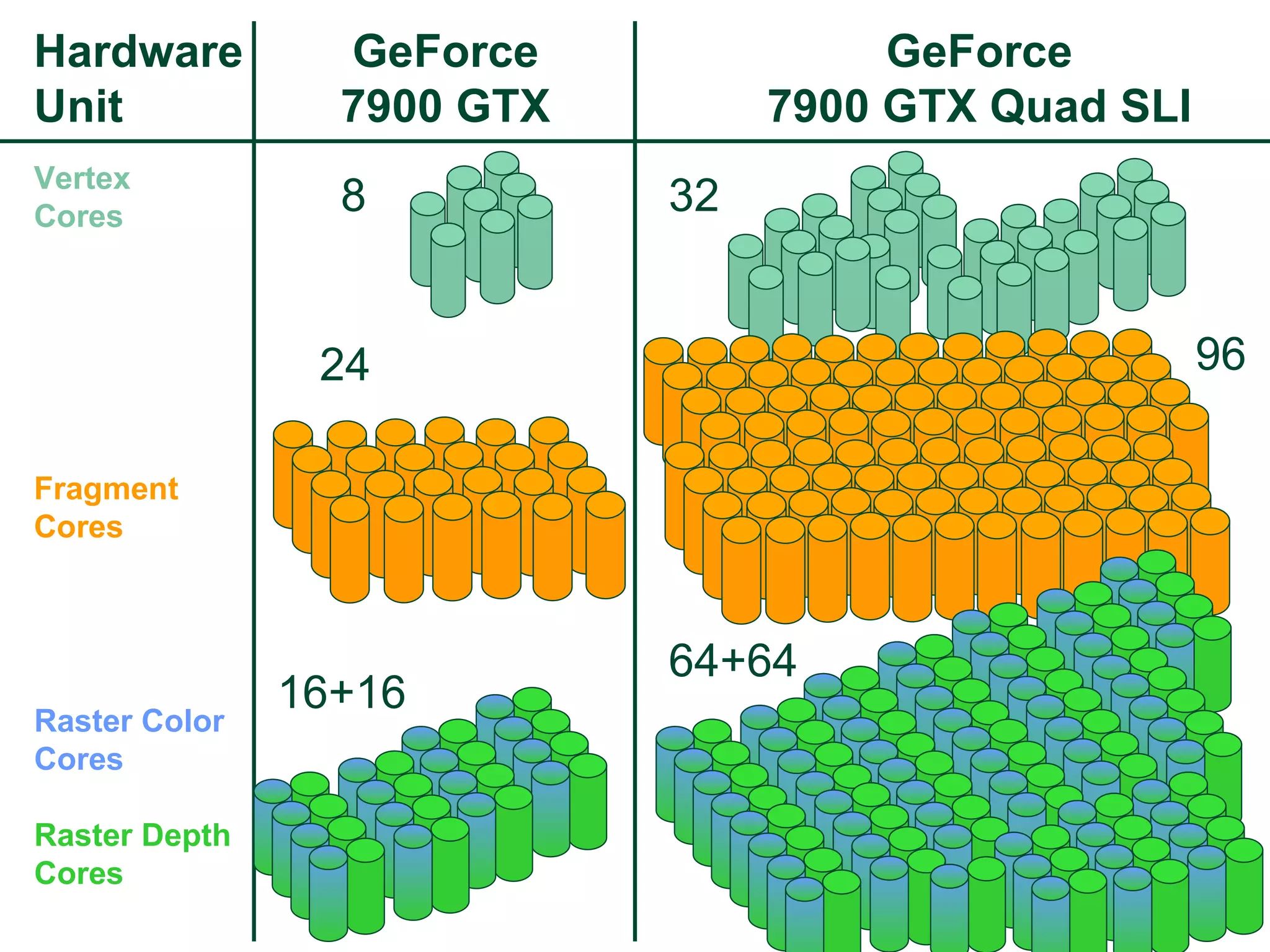
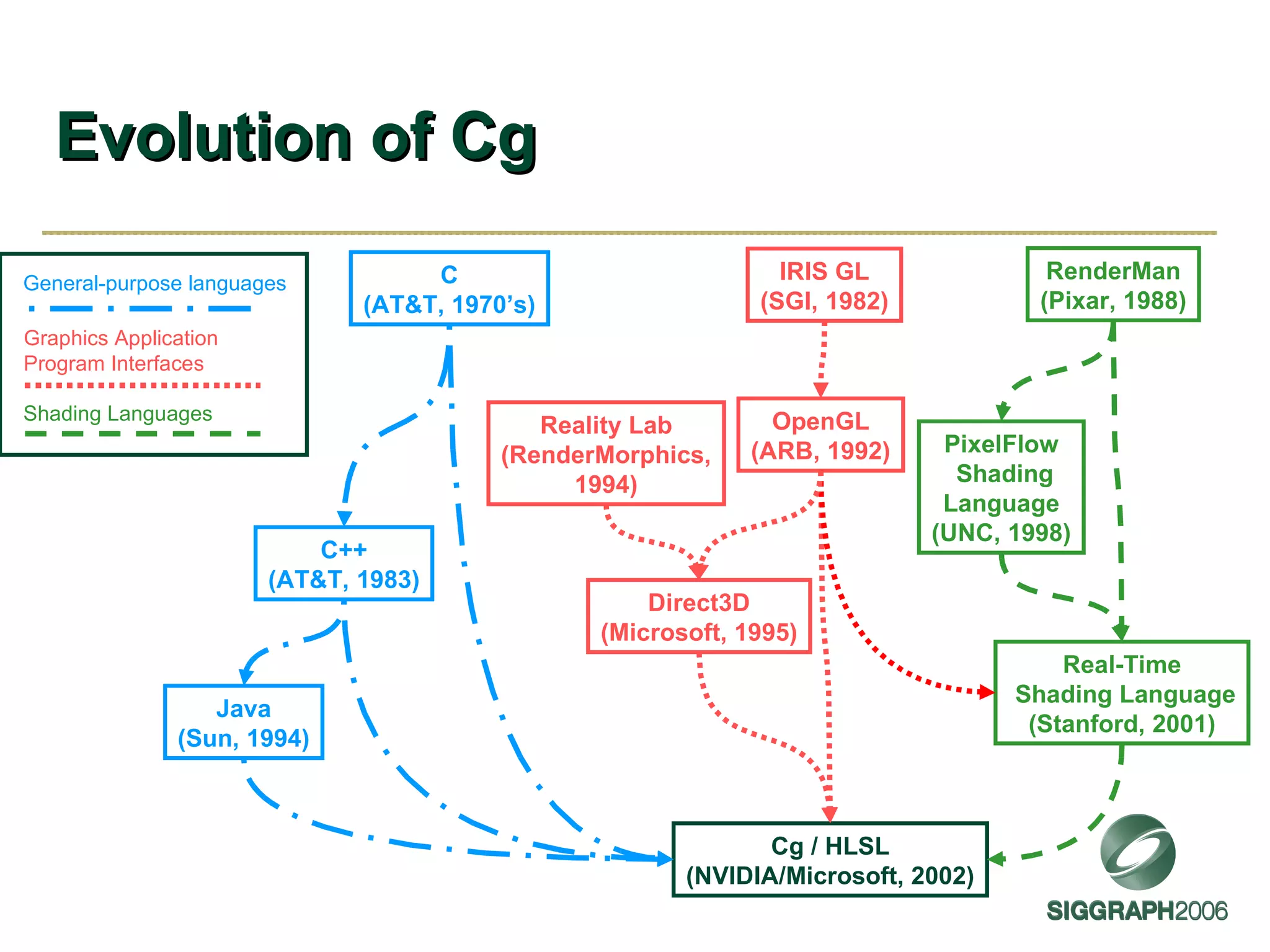
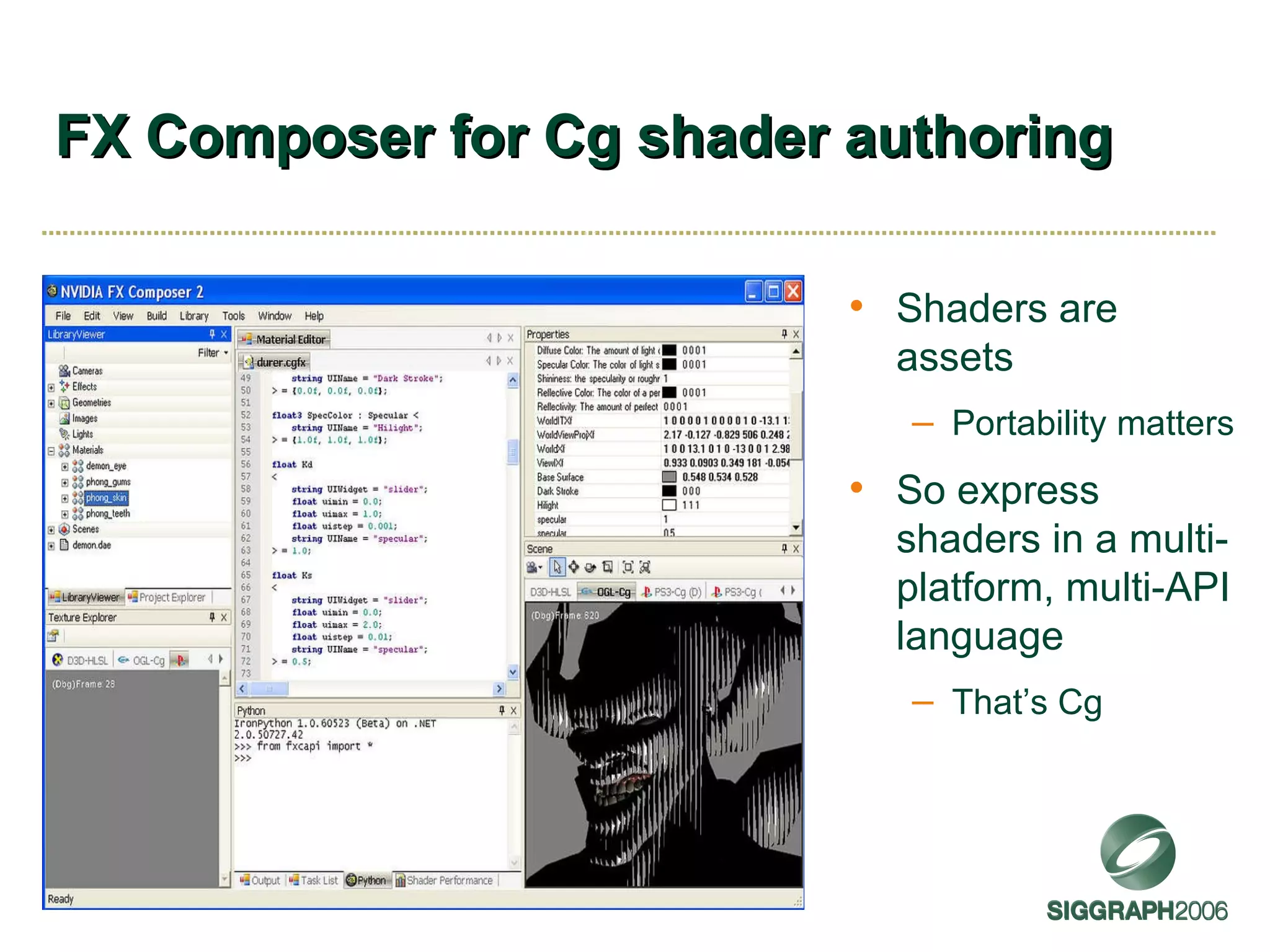
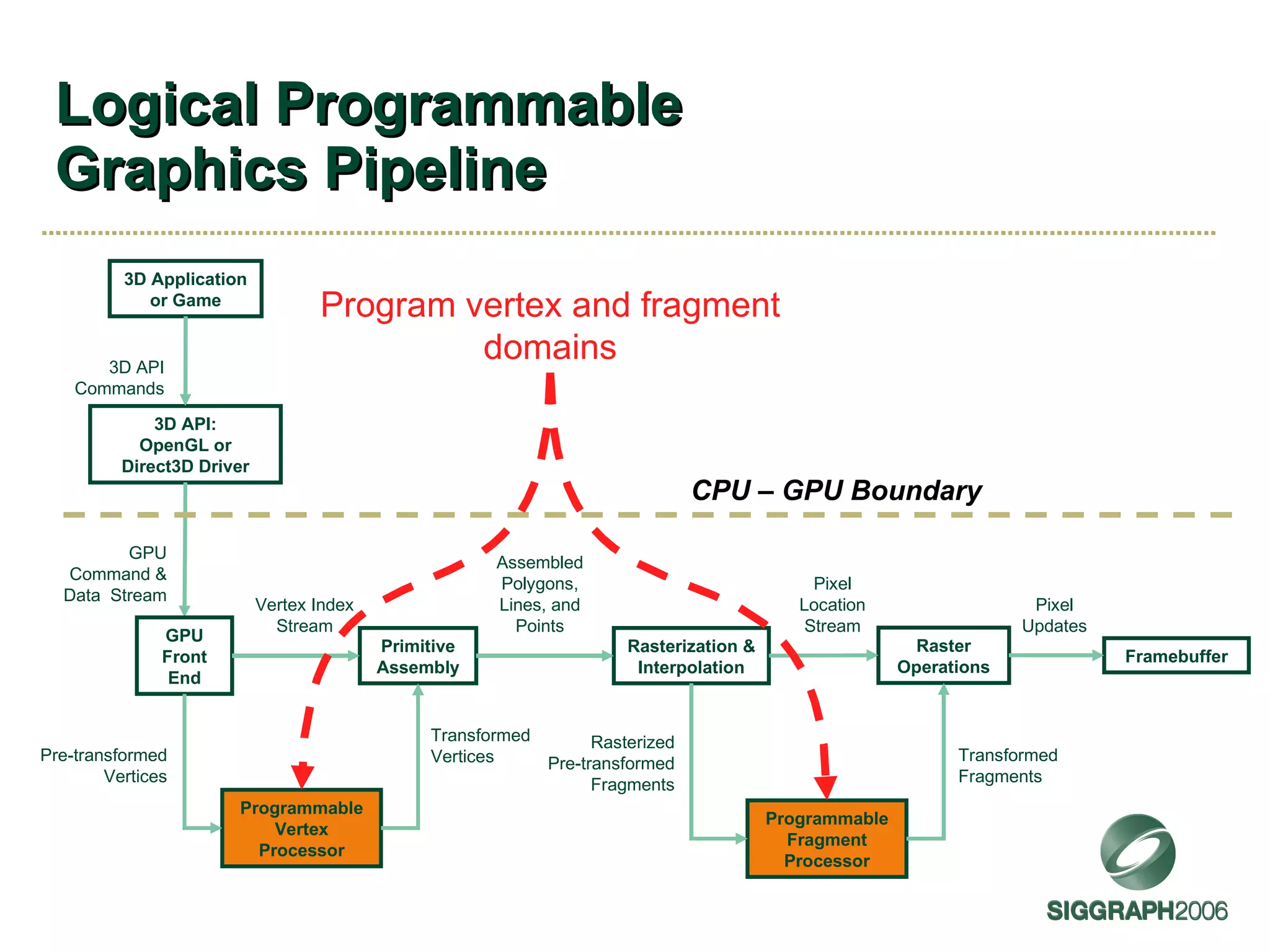
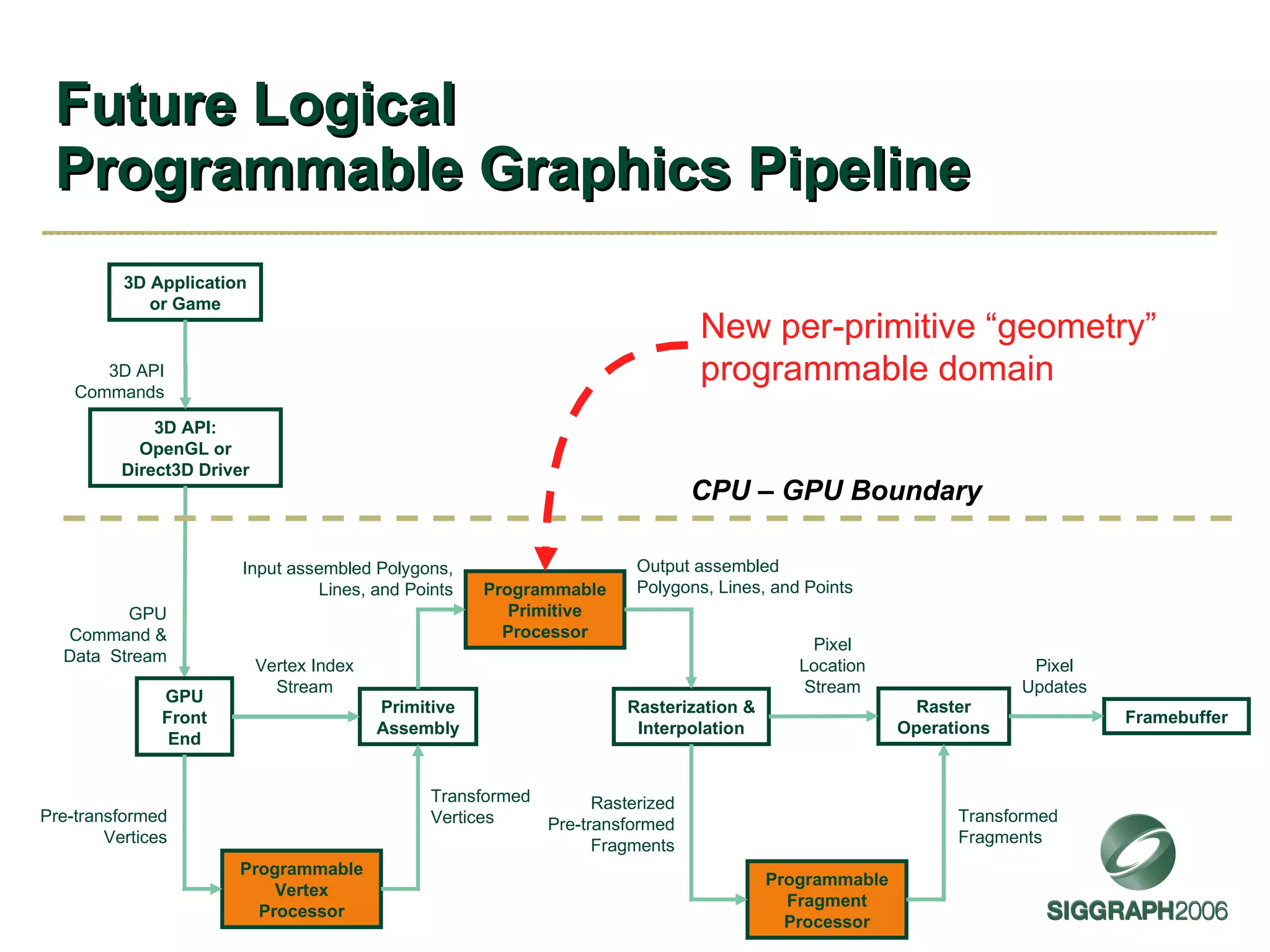
The document discusses NVIDIA graphics hardware over seven years, the Cg programming language, and transparency techniques. It describes the evolution of NVIDIA GPUs and features like GeForce cards, increased processing power, and support for DirectX. It promotes Cg as a cross-platform language for GPU programming. It also explains the depth peeling algorithm for rendering transparency in real-time using multiple rendering passes.















































![[03 1][gpu용 개발자 도구 - parallel nsight 및 axe] miller axe](https://cdn.slidesharecdn.com/ss_thumbnails/03-1gpu-parallelnsightaxemilleraxe-110106231332-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)
![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)











