Downloaded 243 times





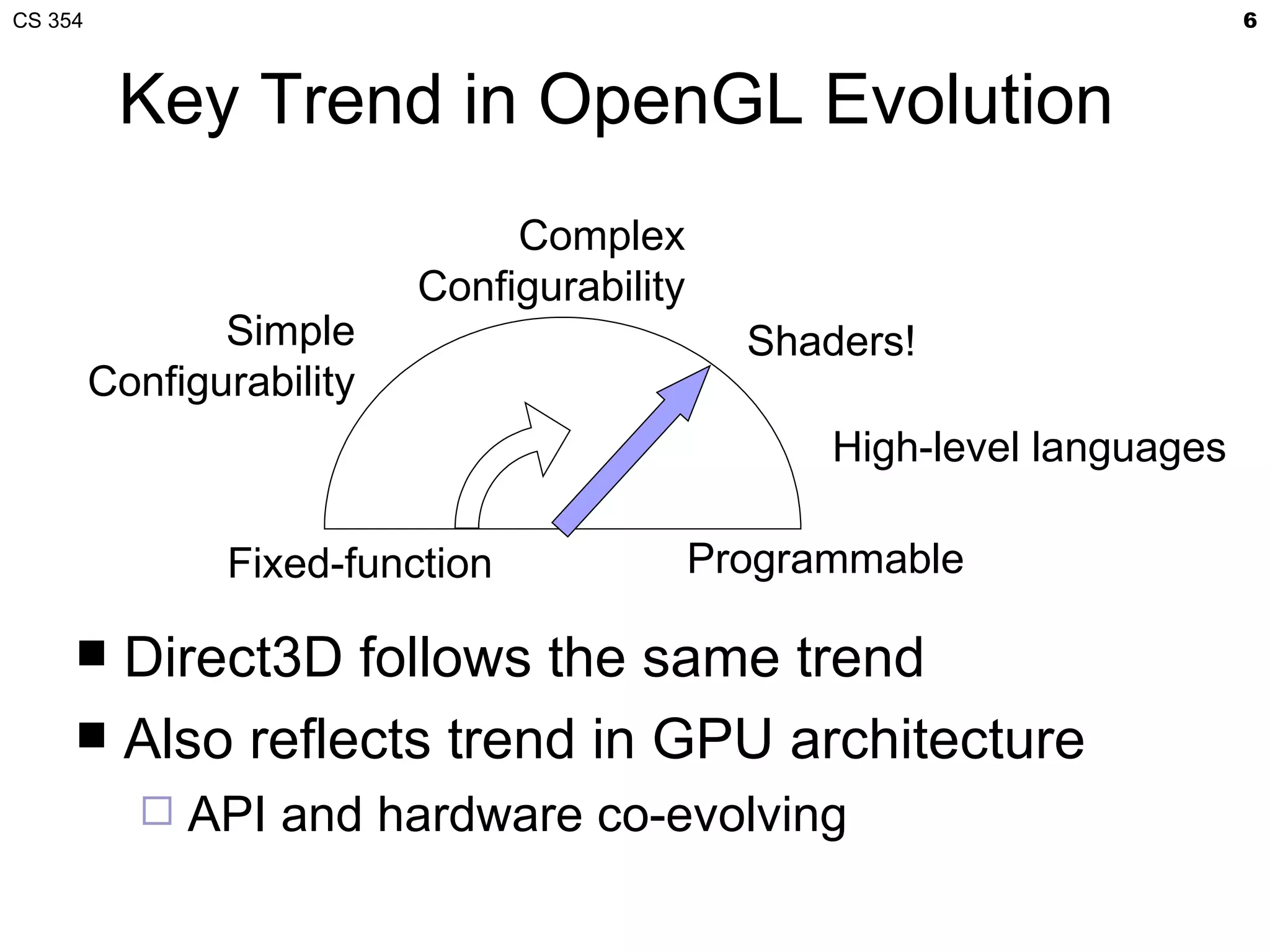
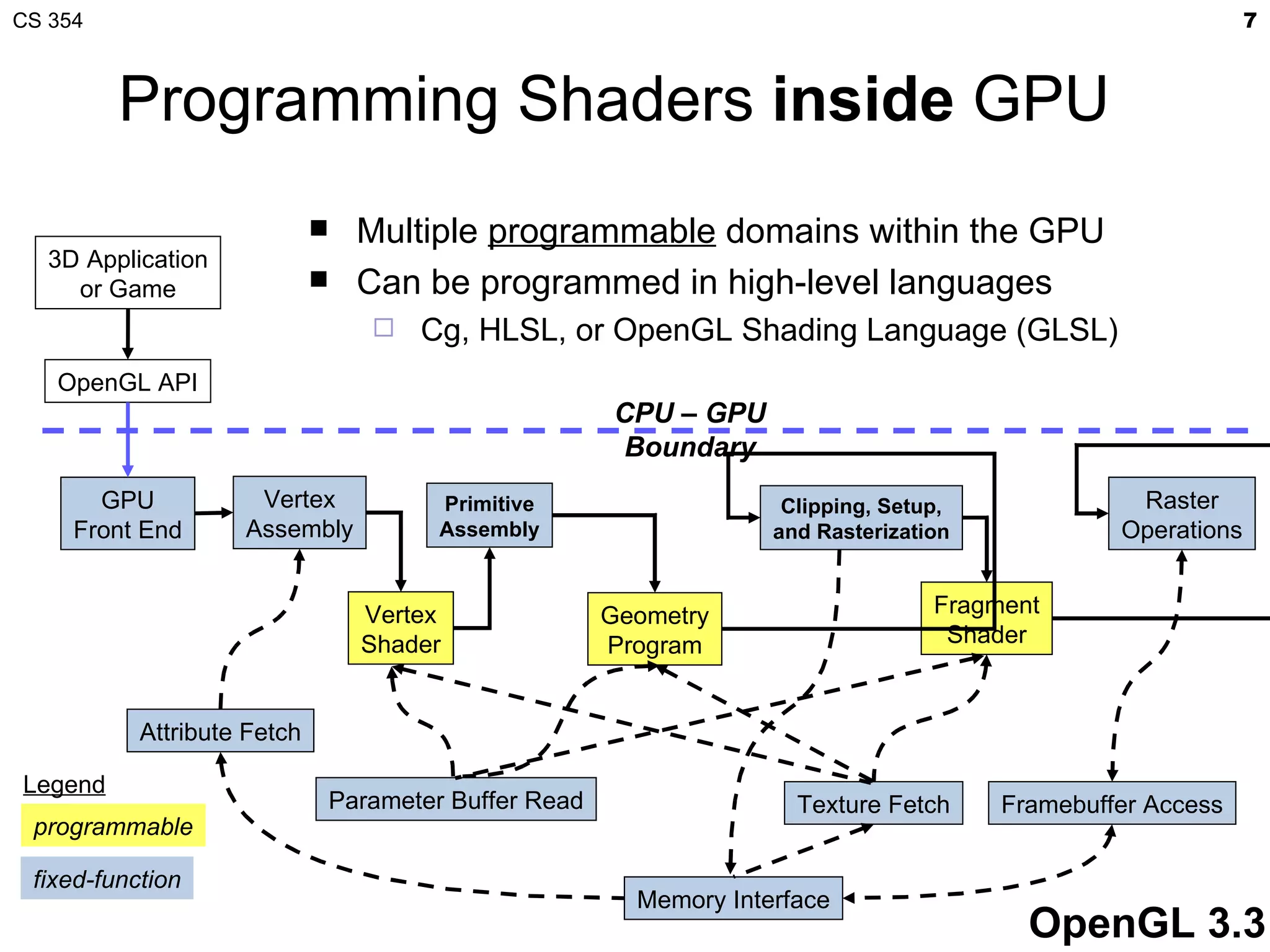
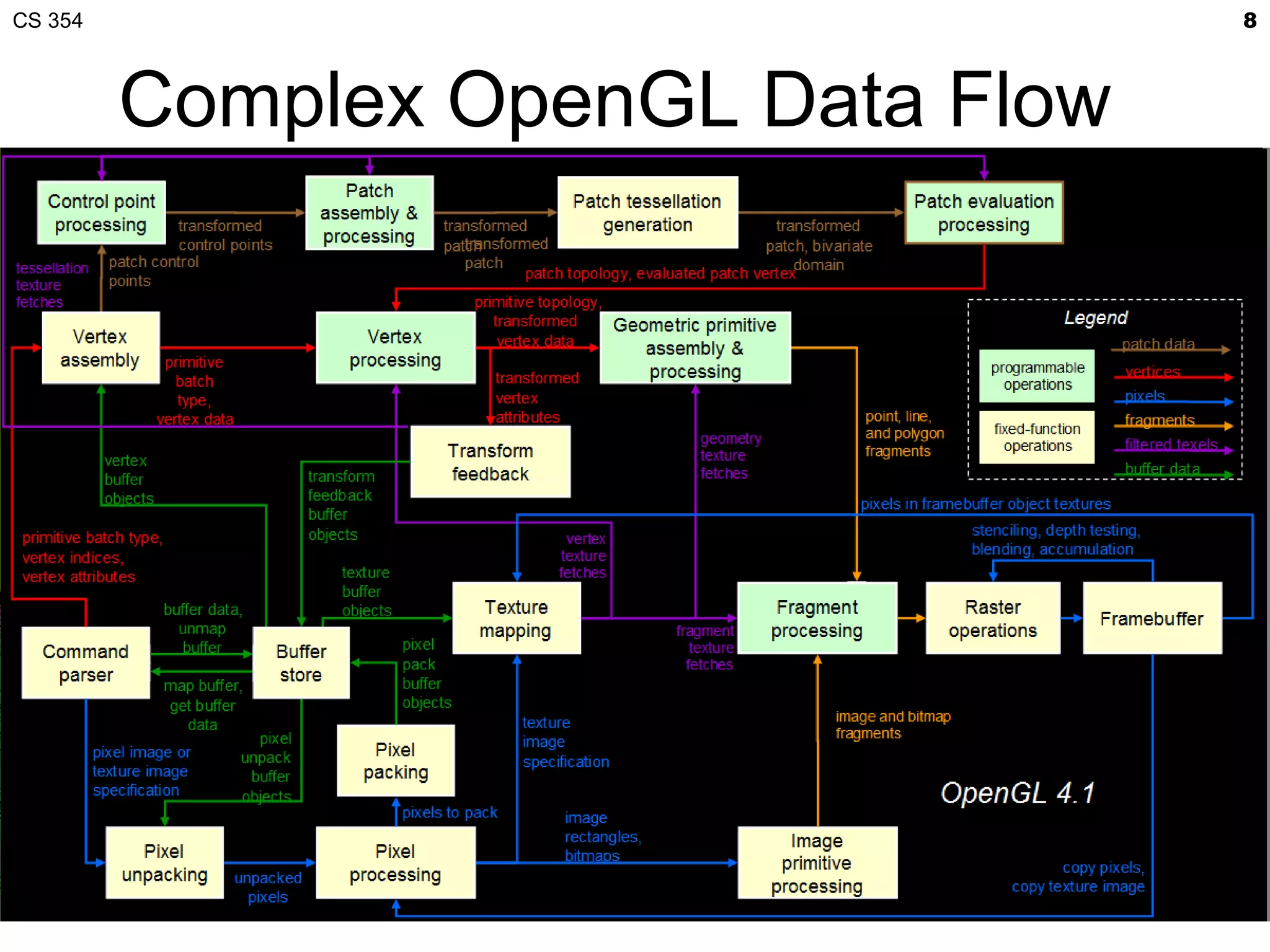

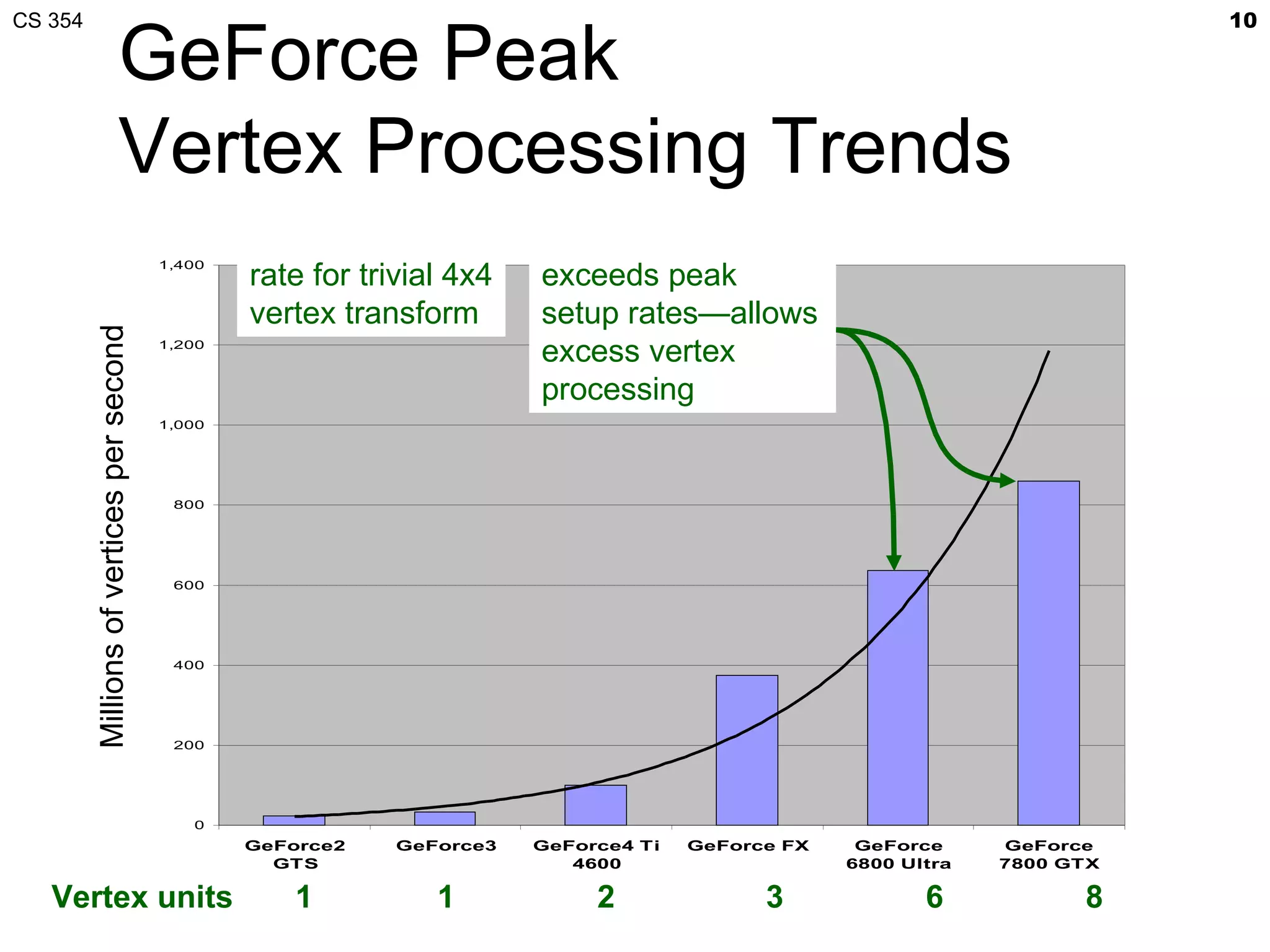
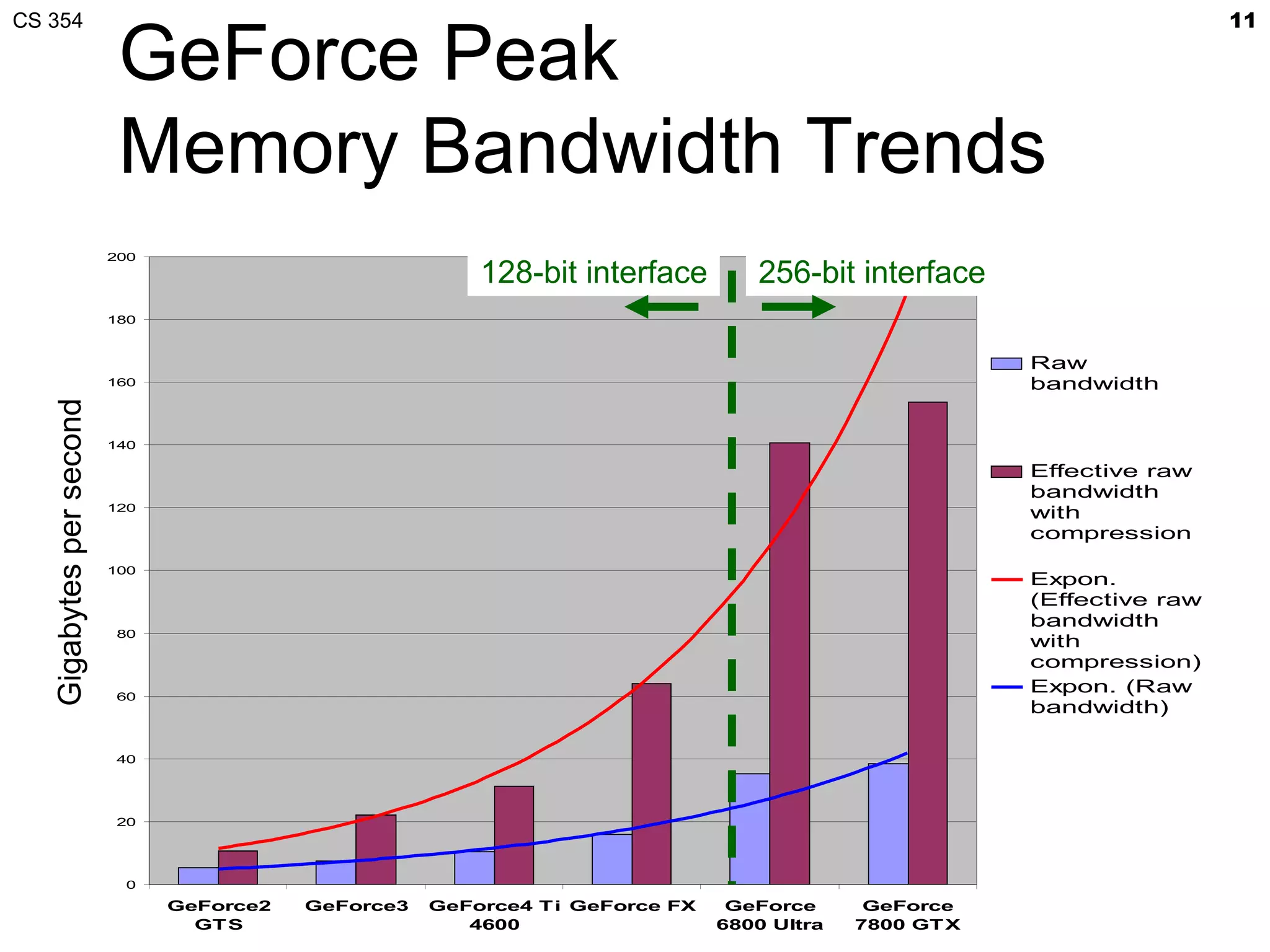

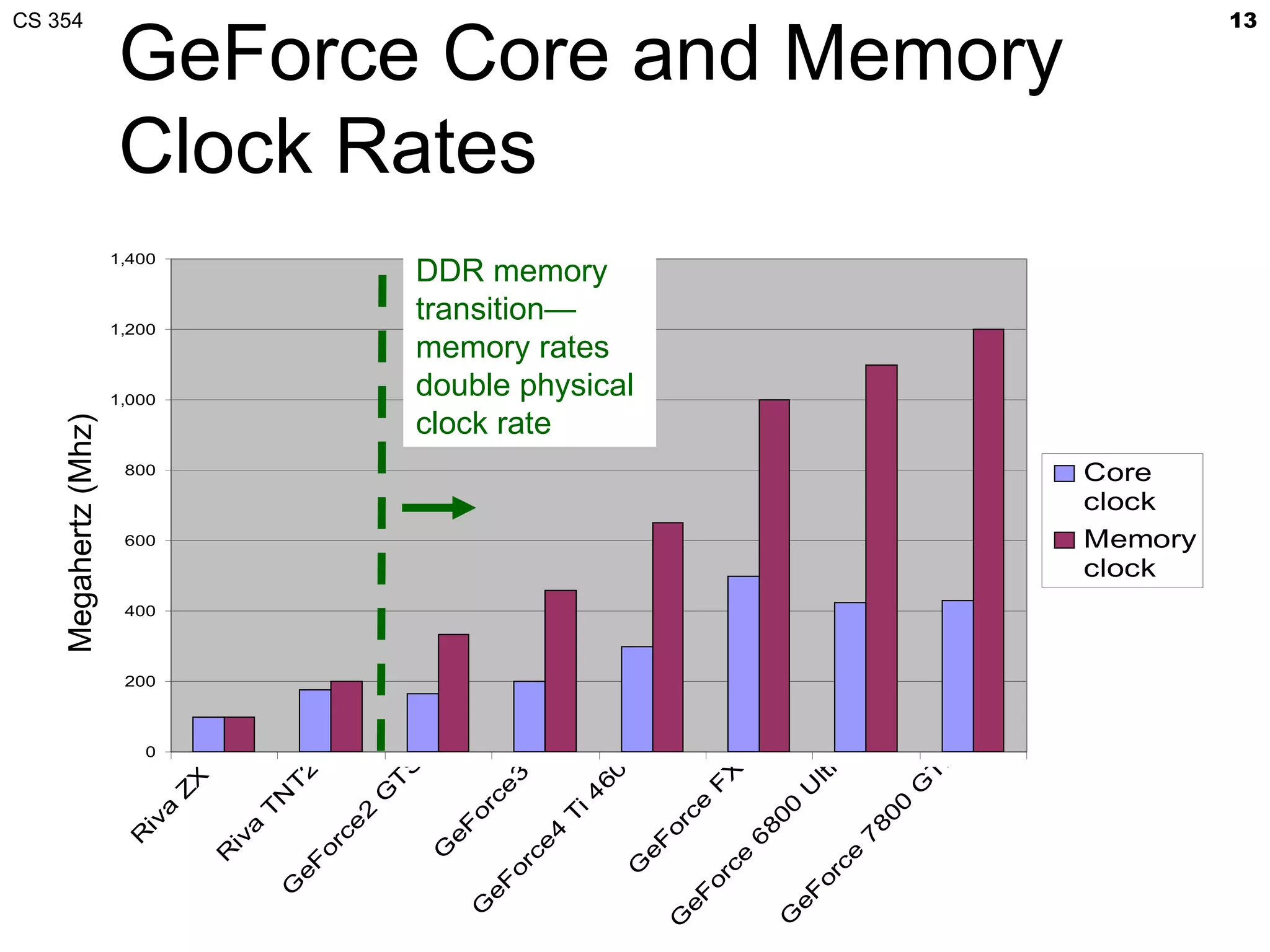
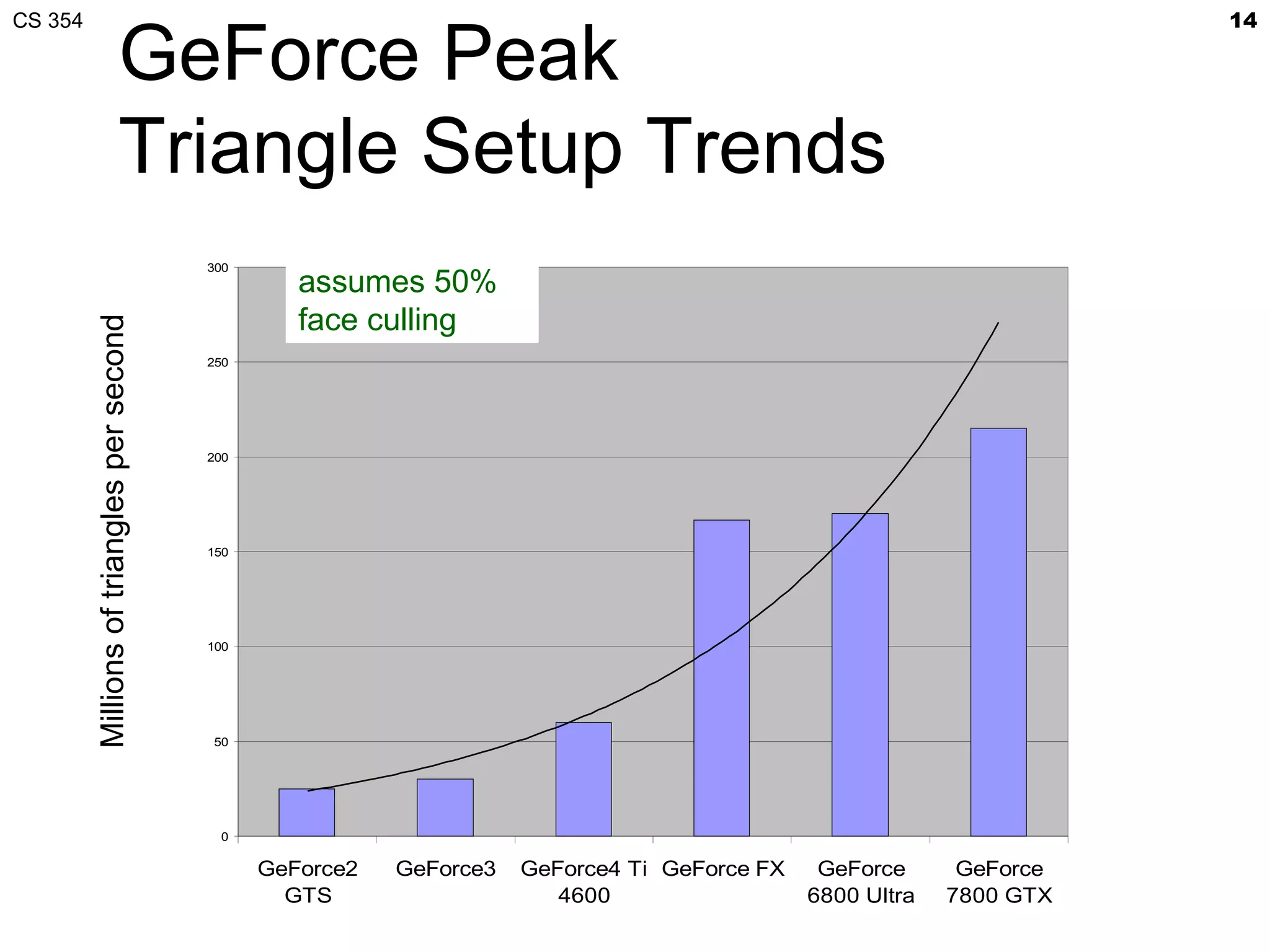
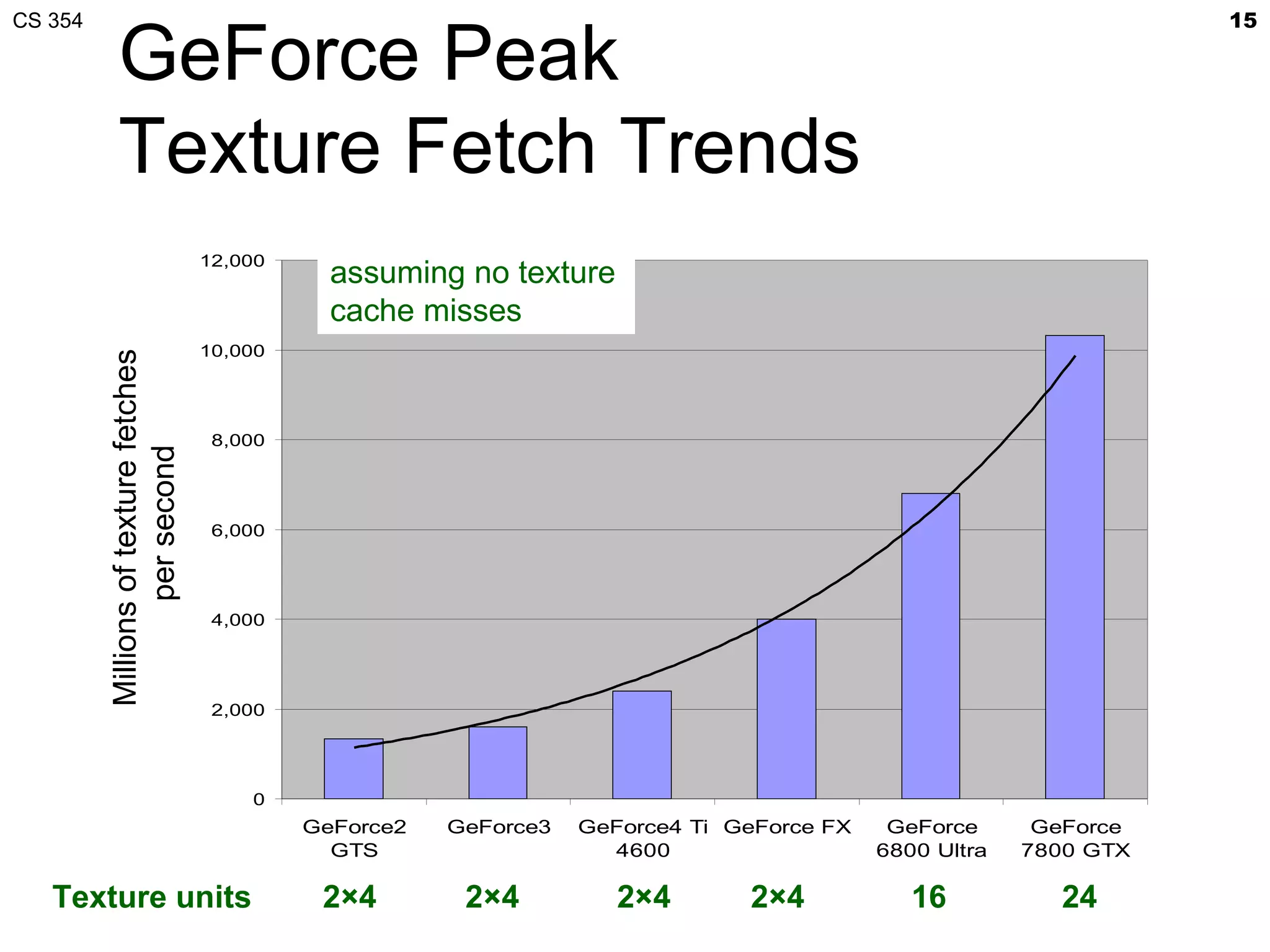
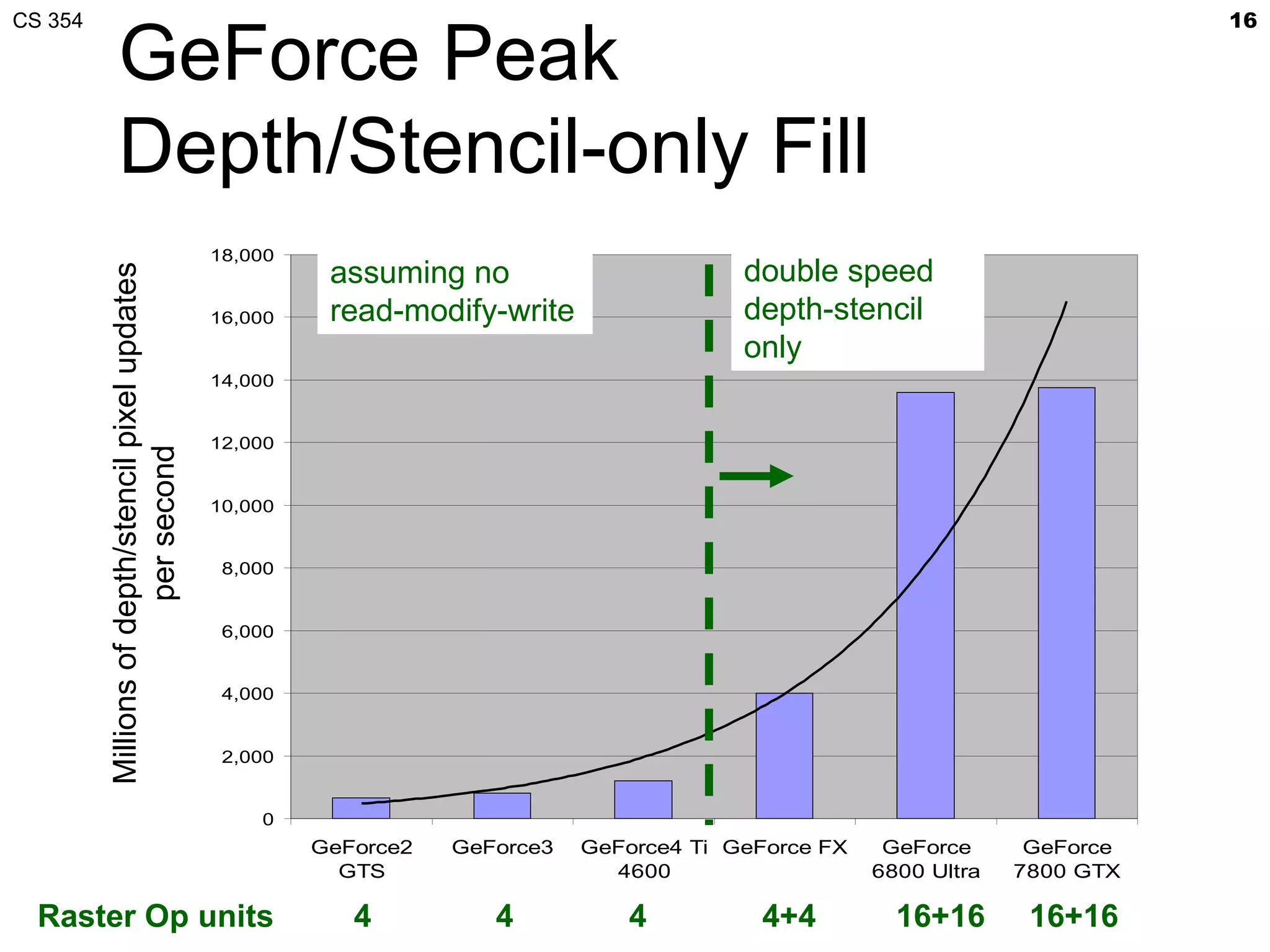
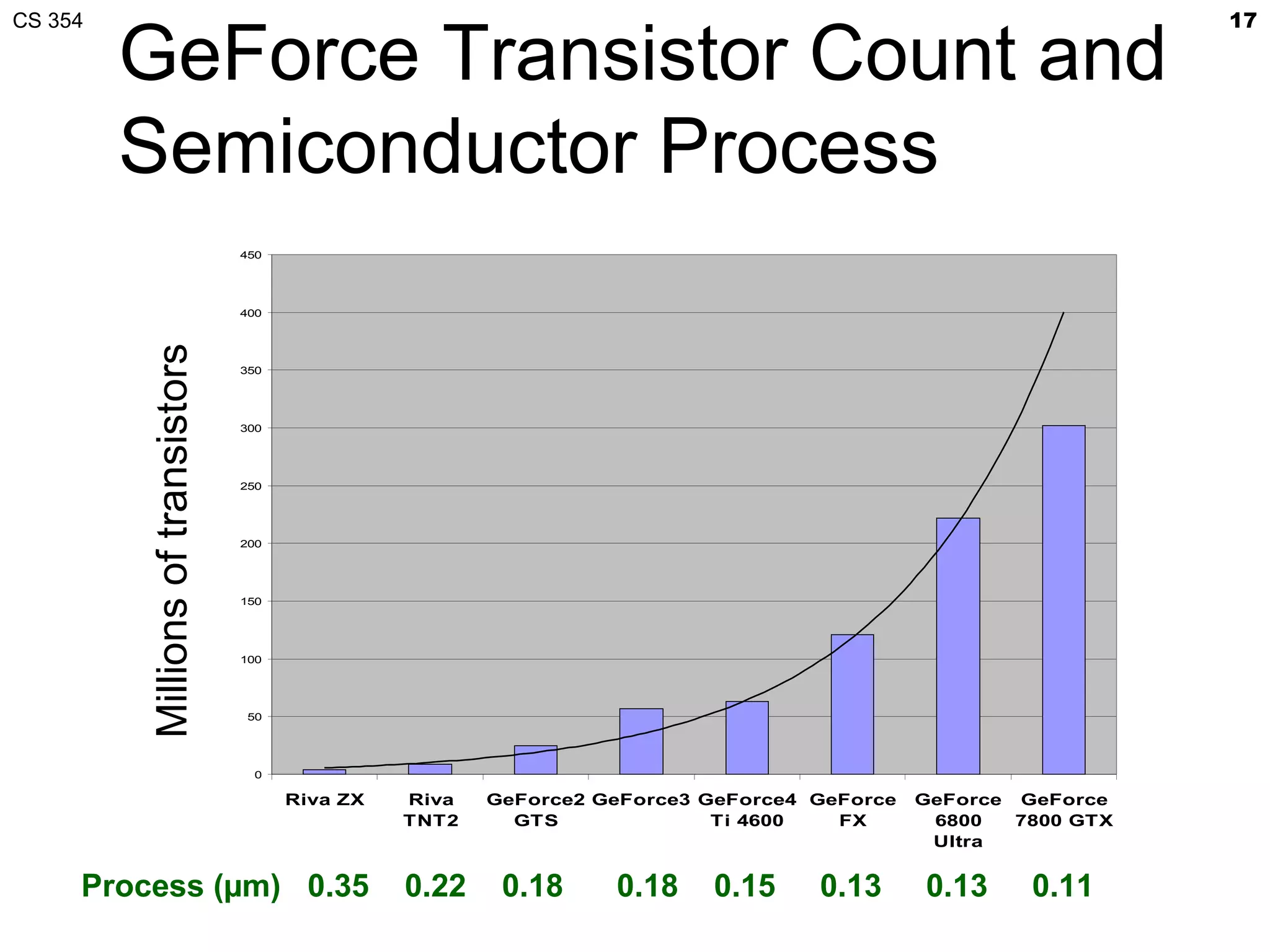
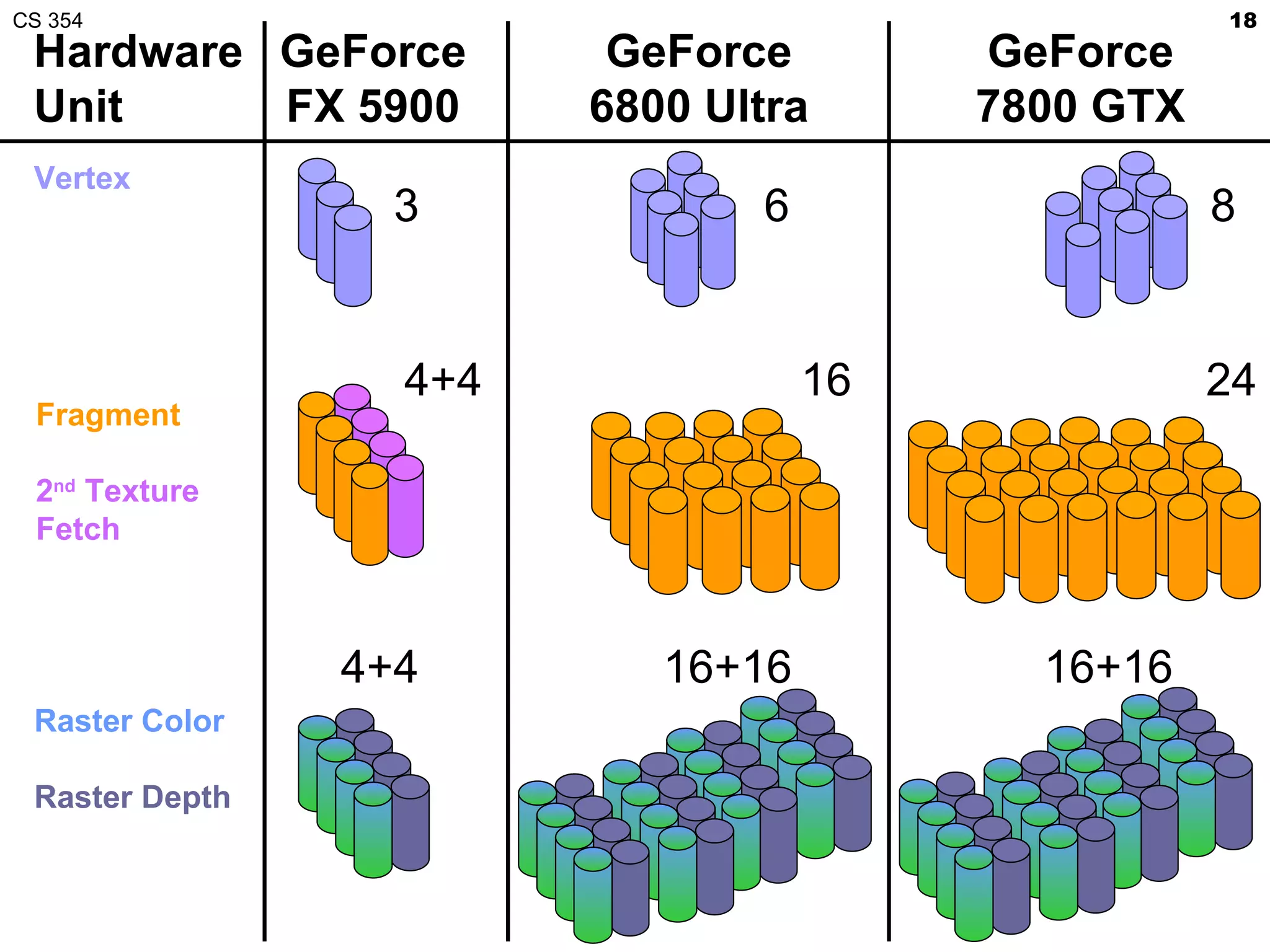



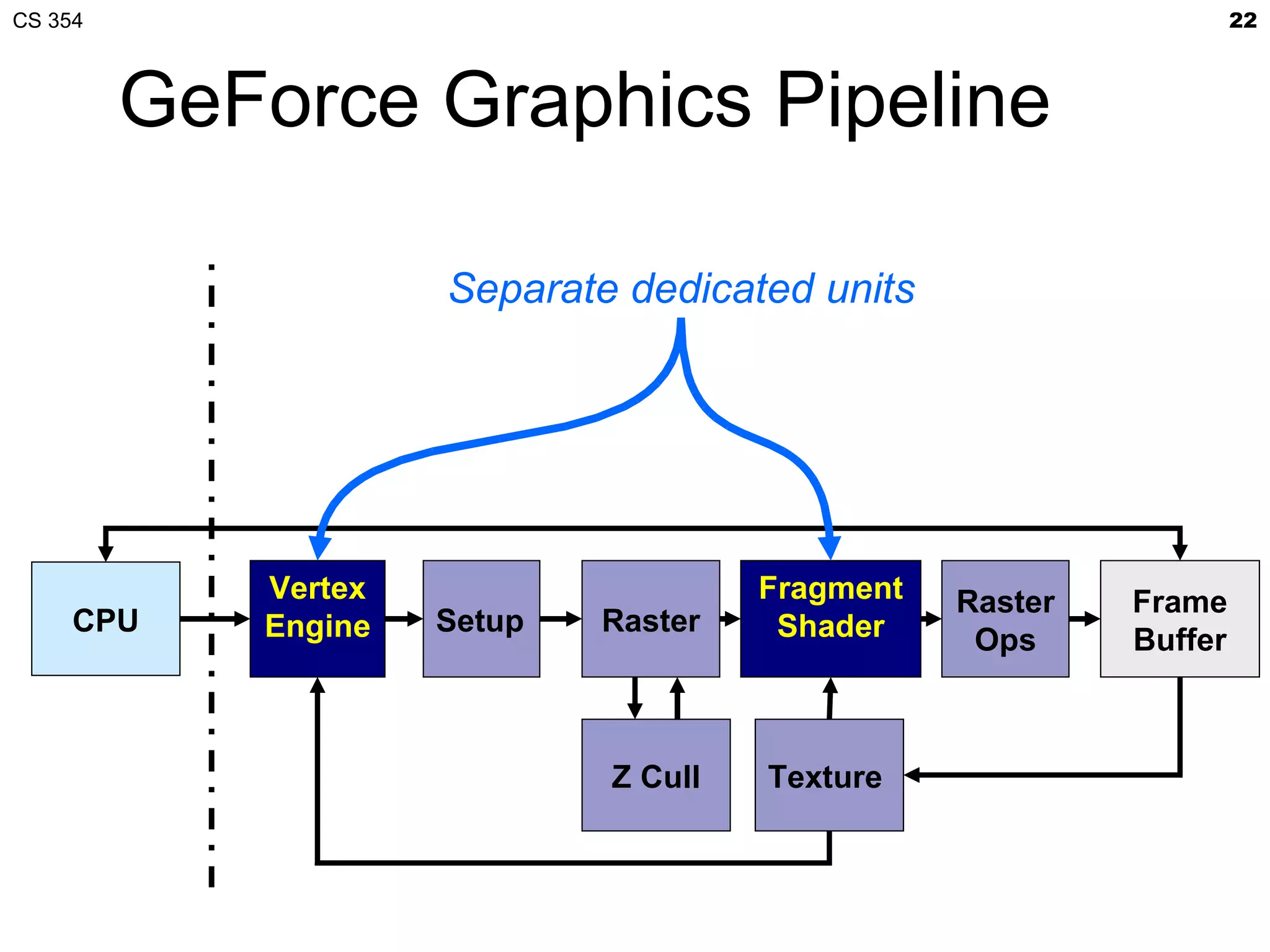
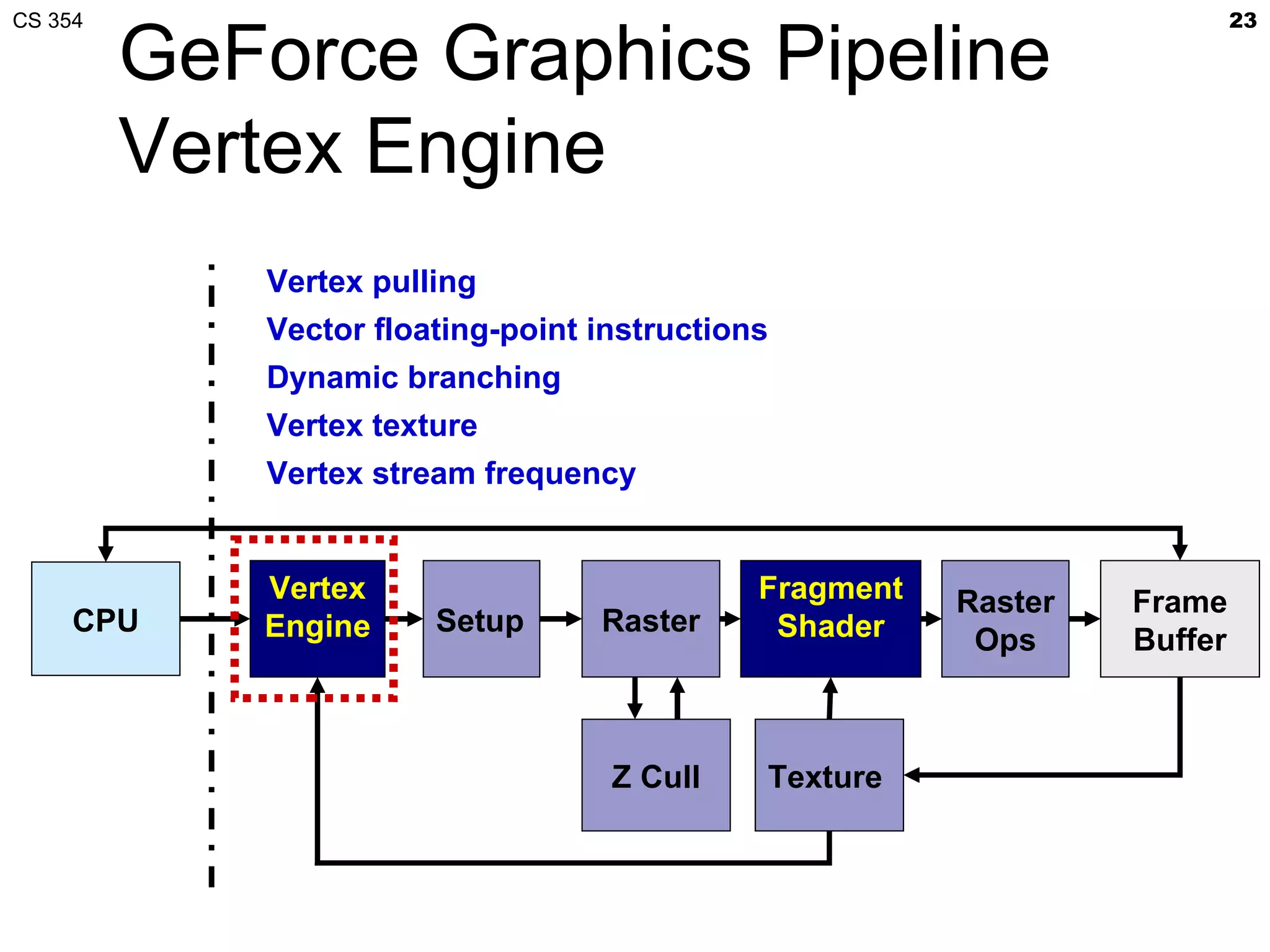
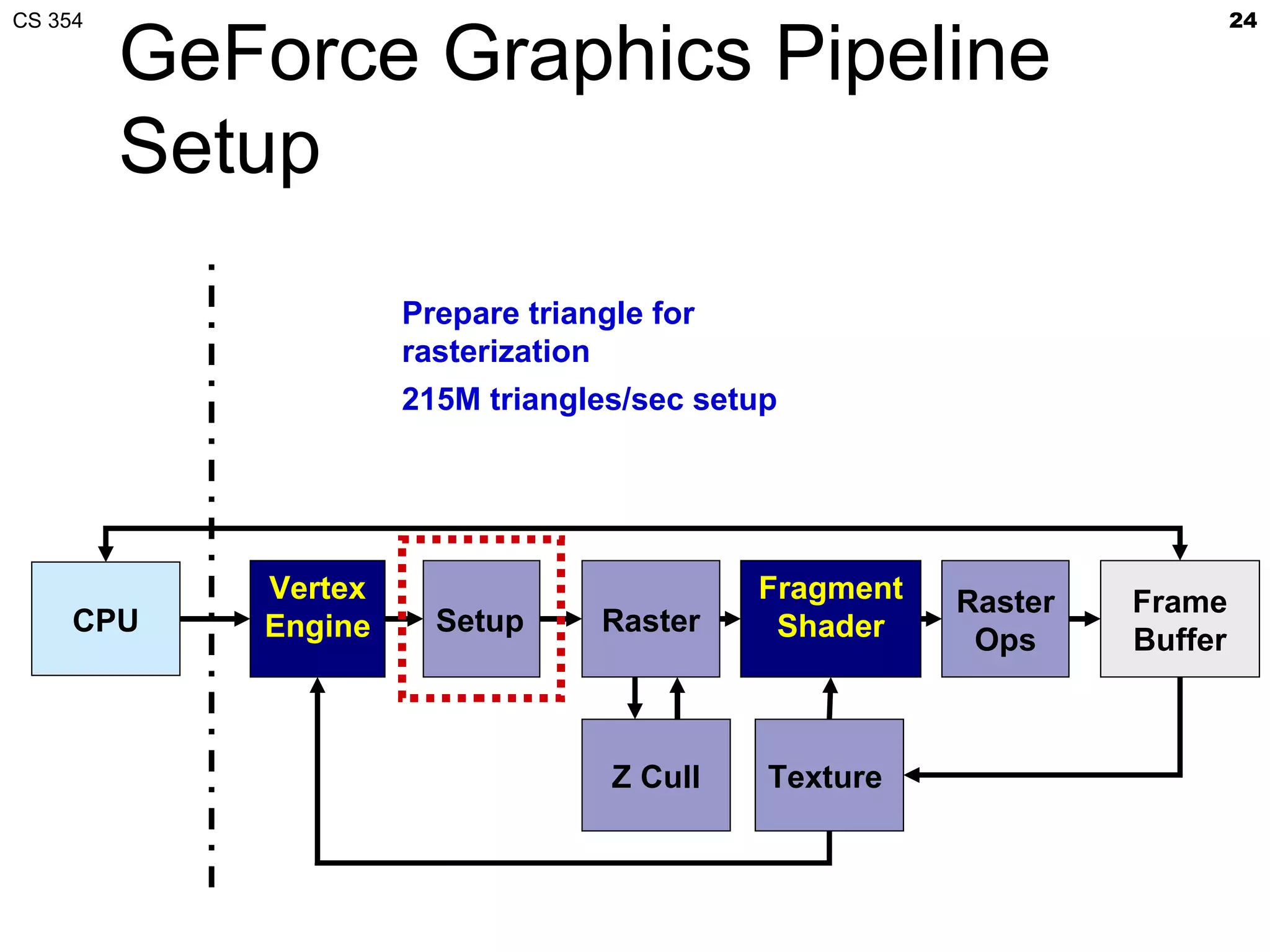
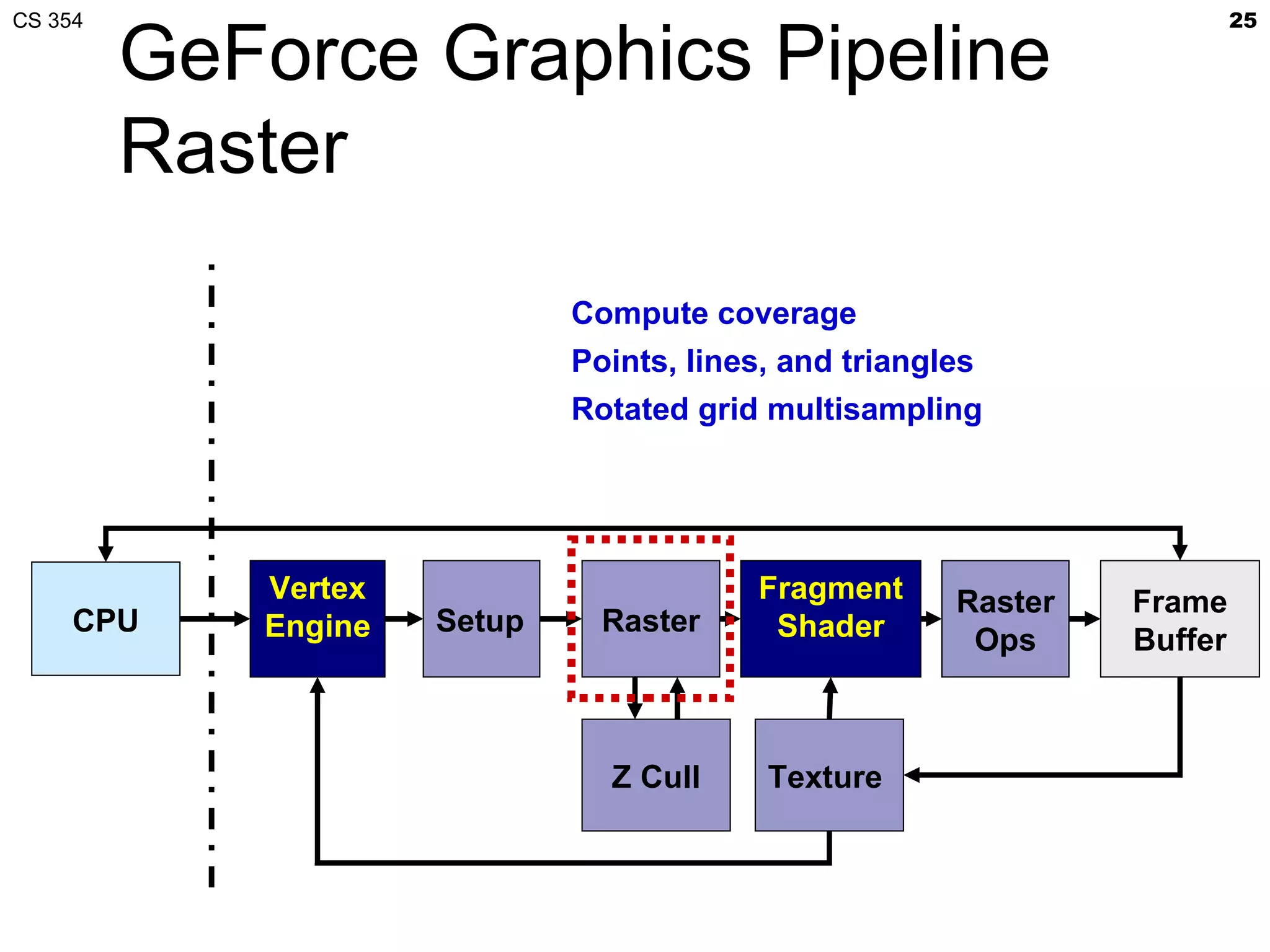
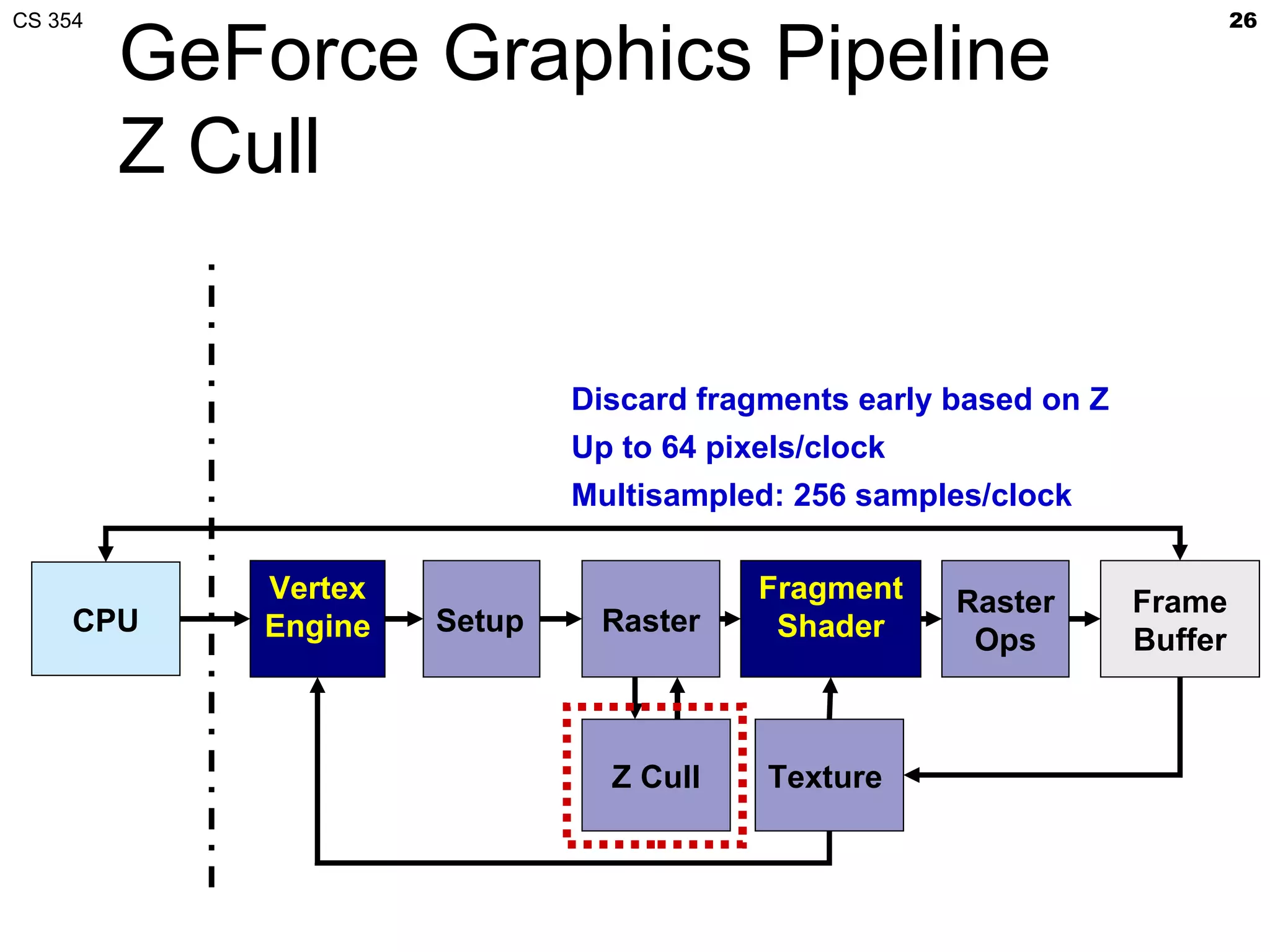
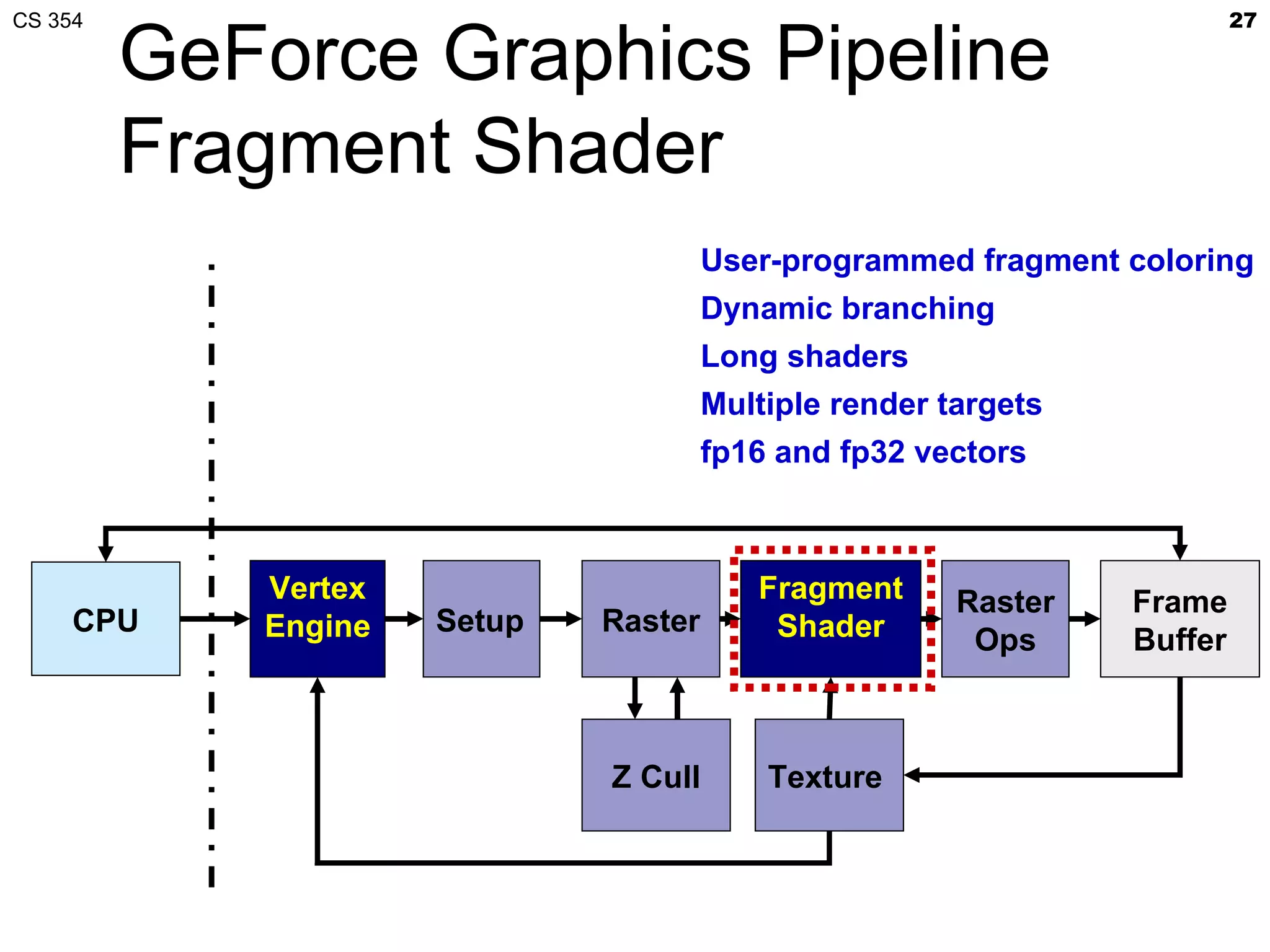
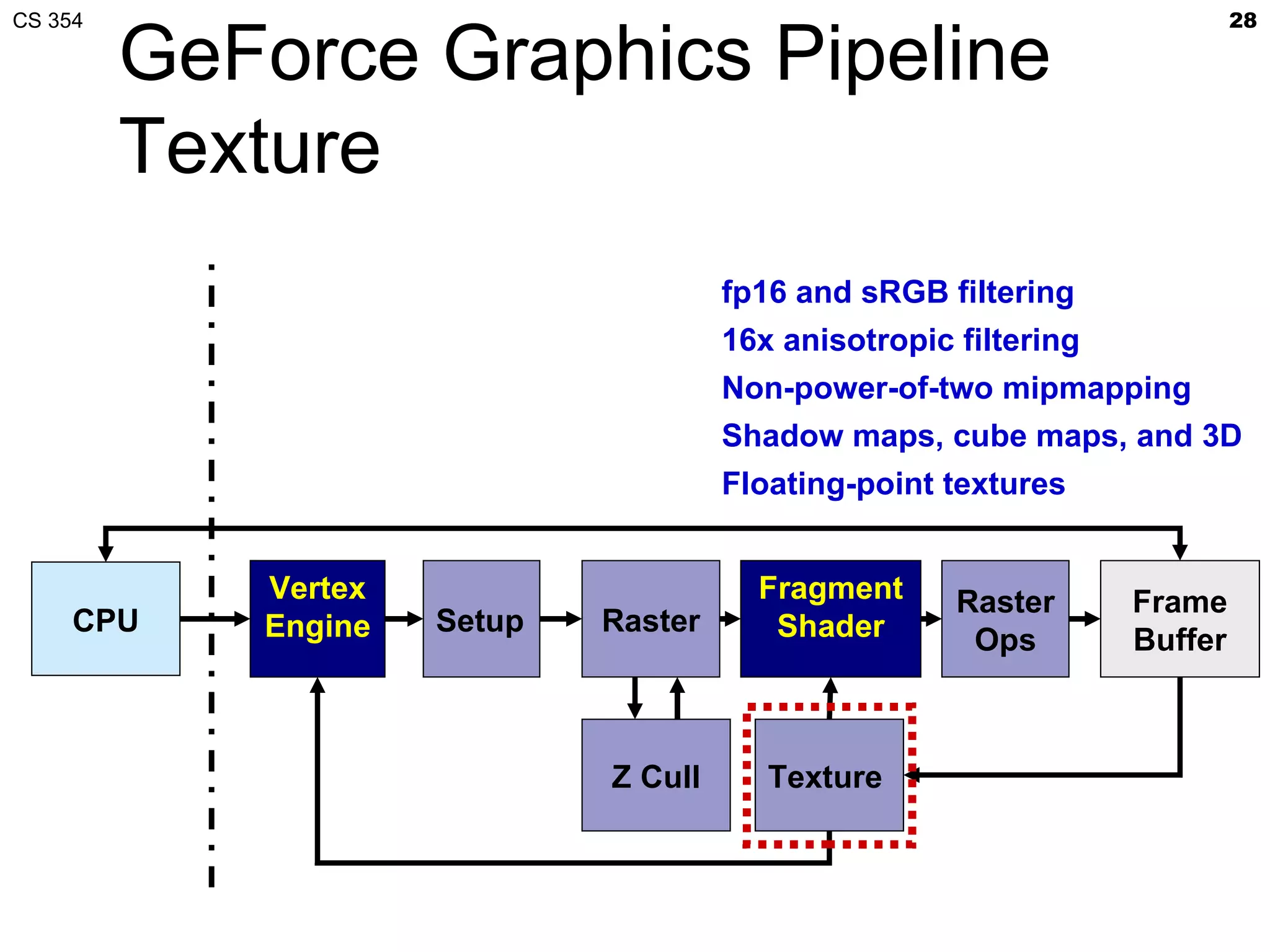
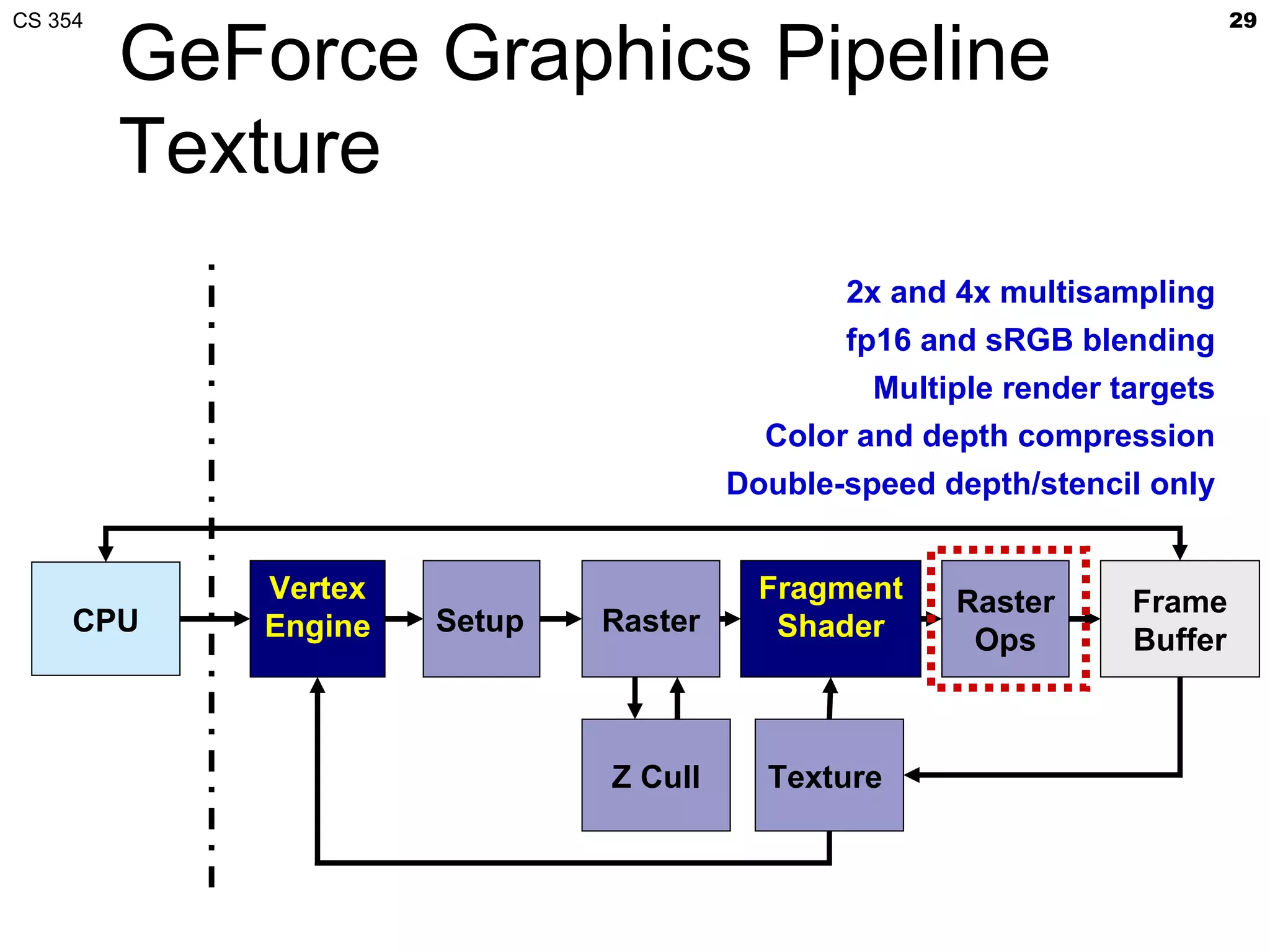
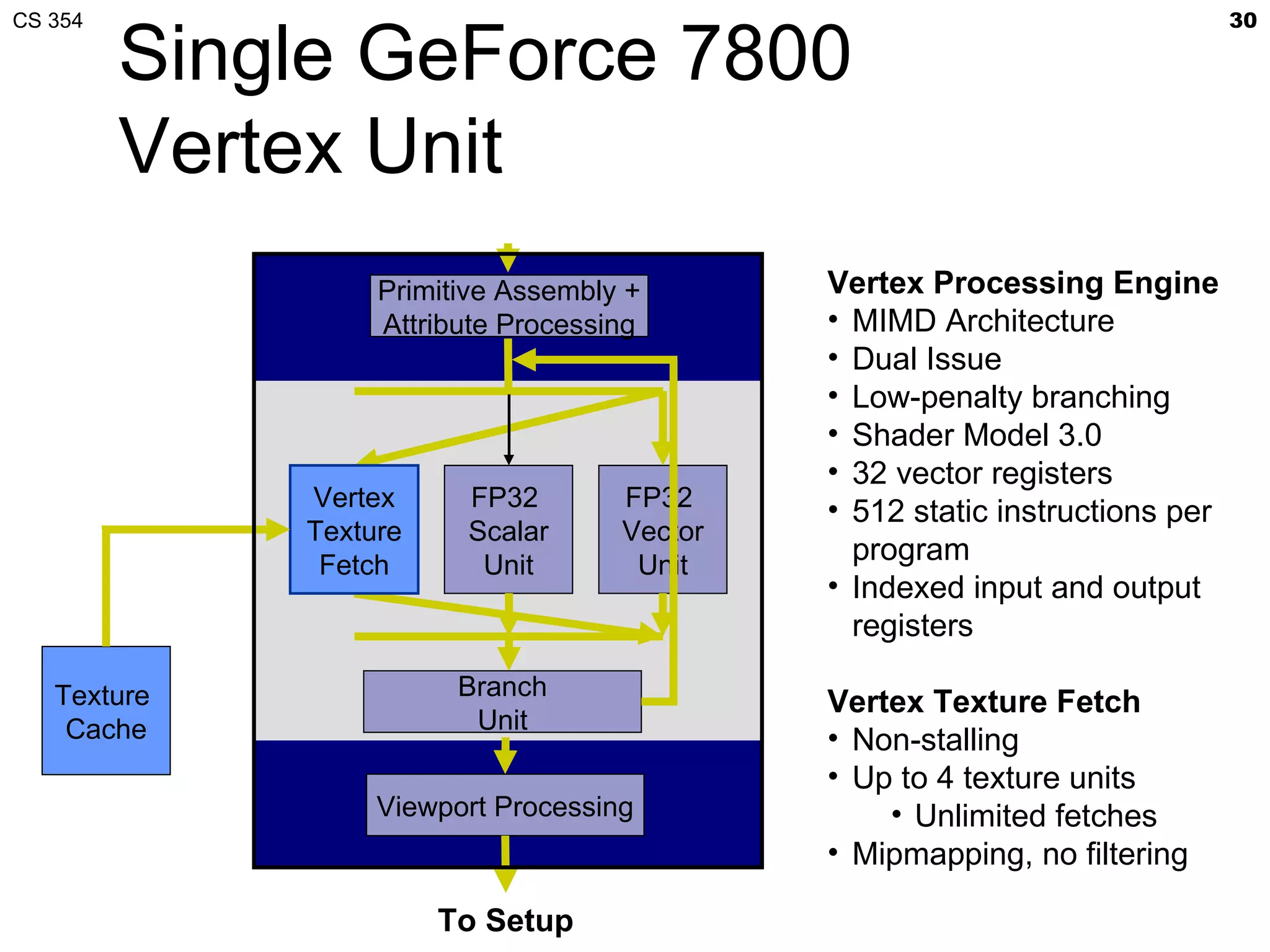



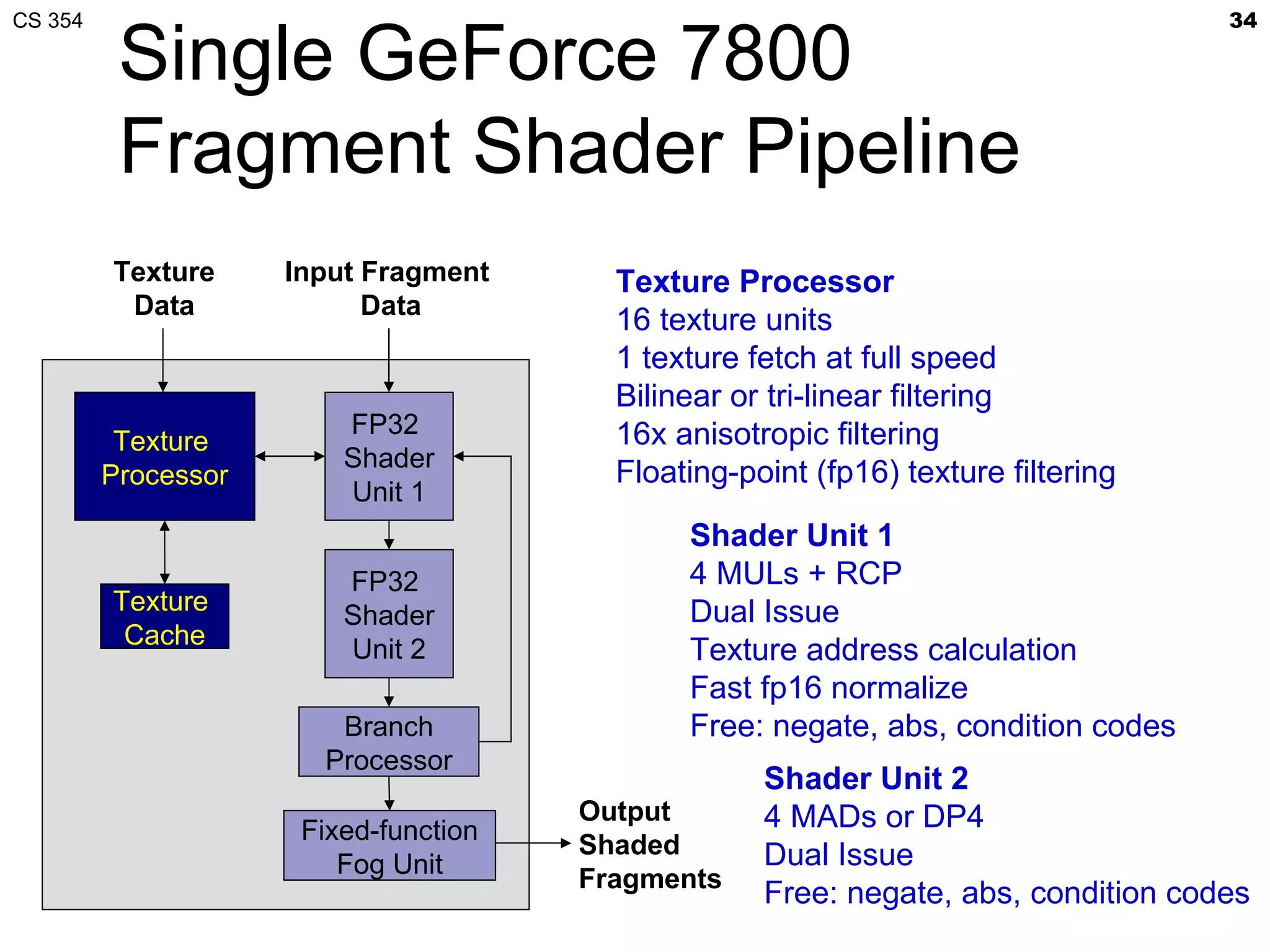
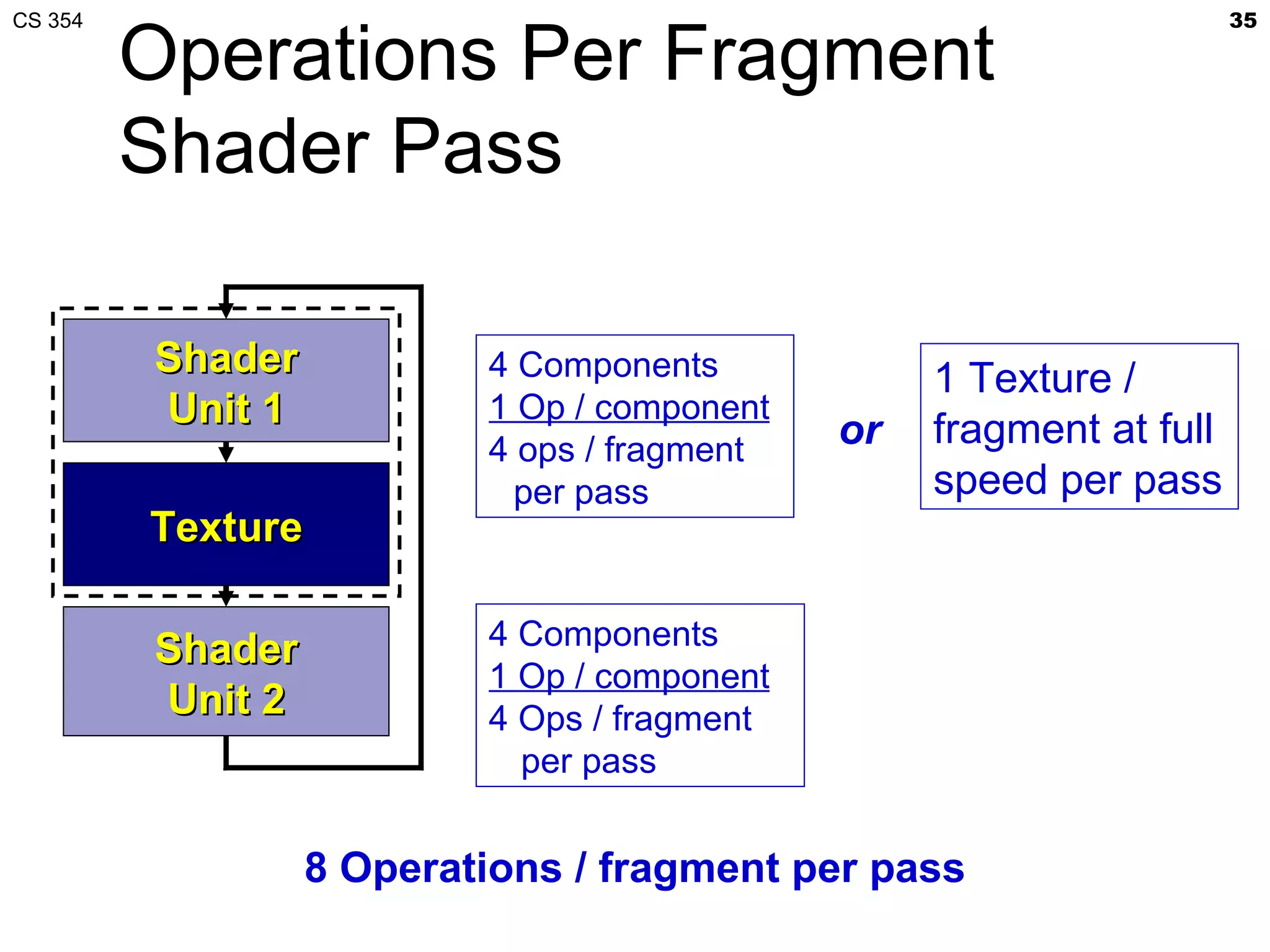
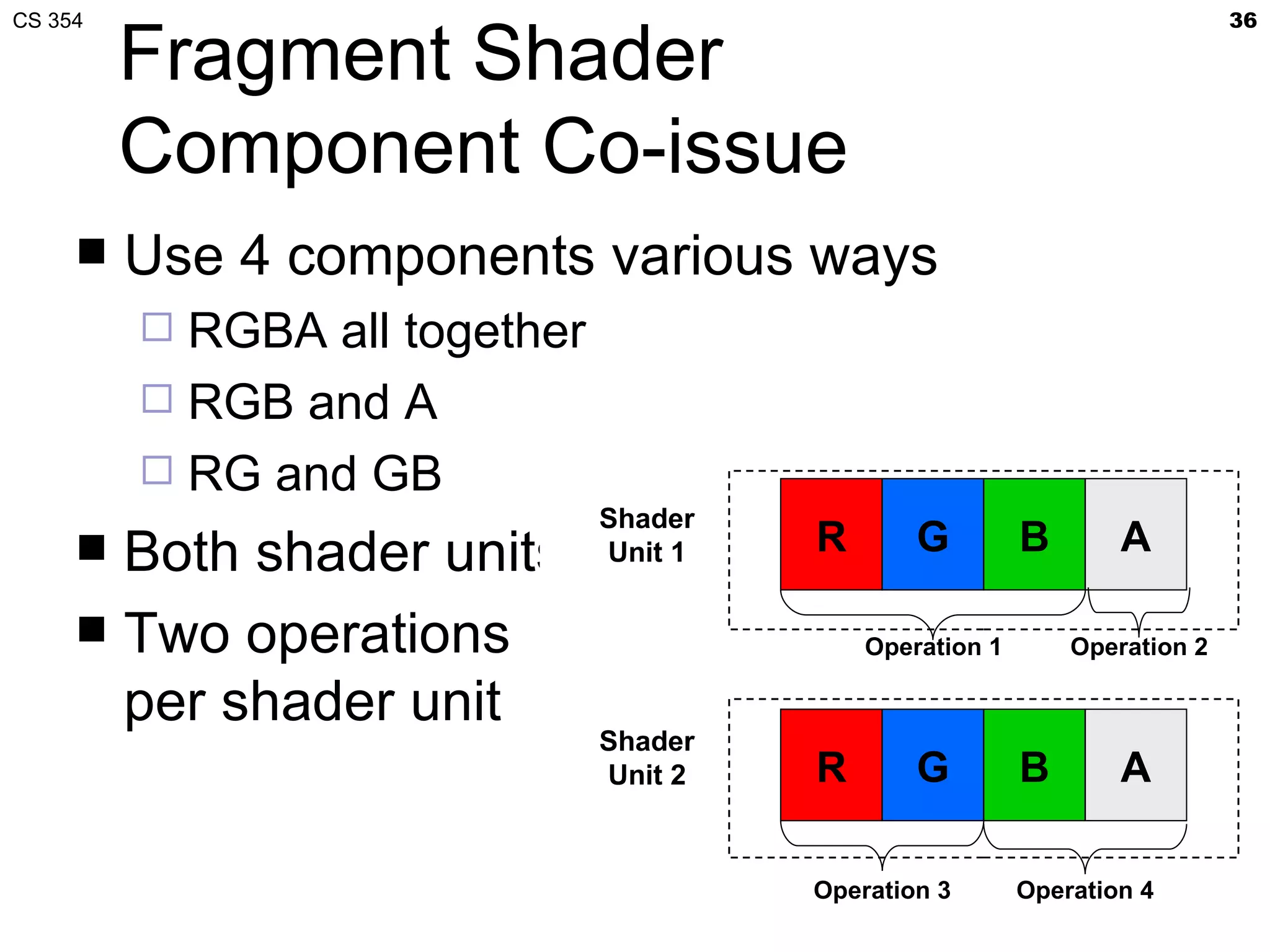
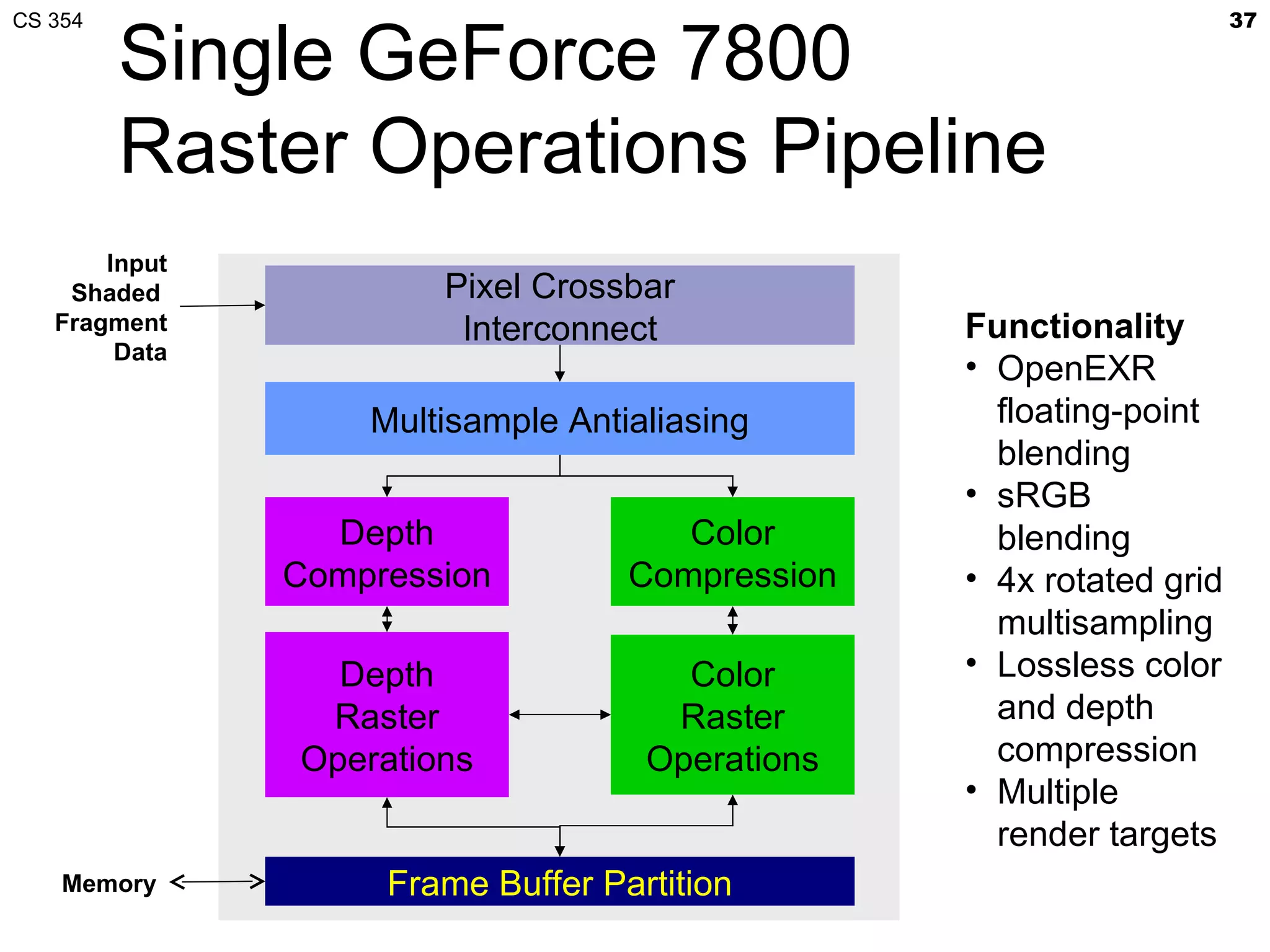



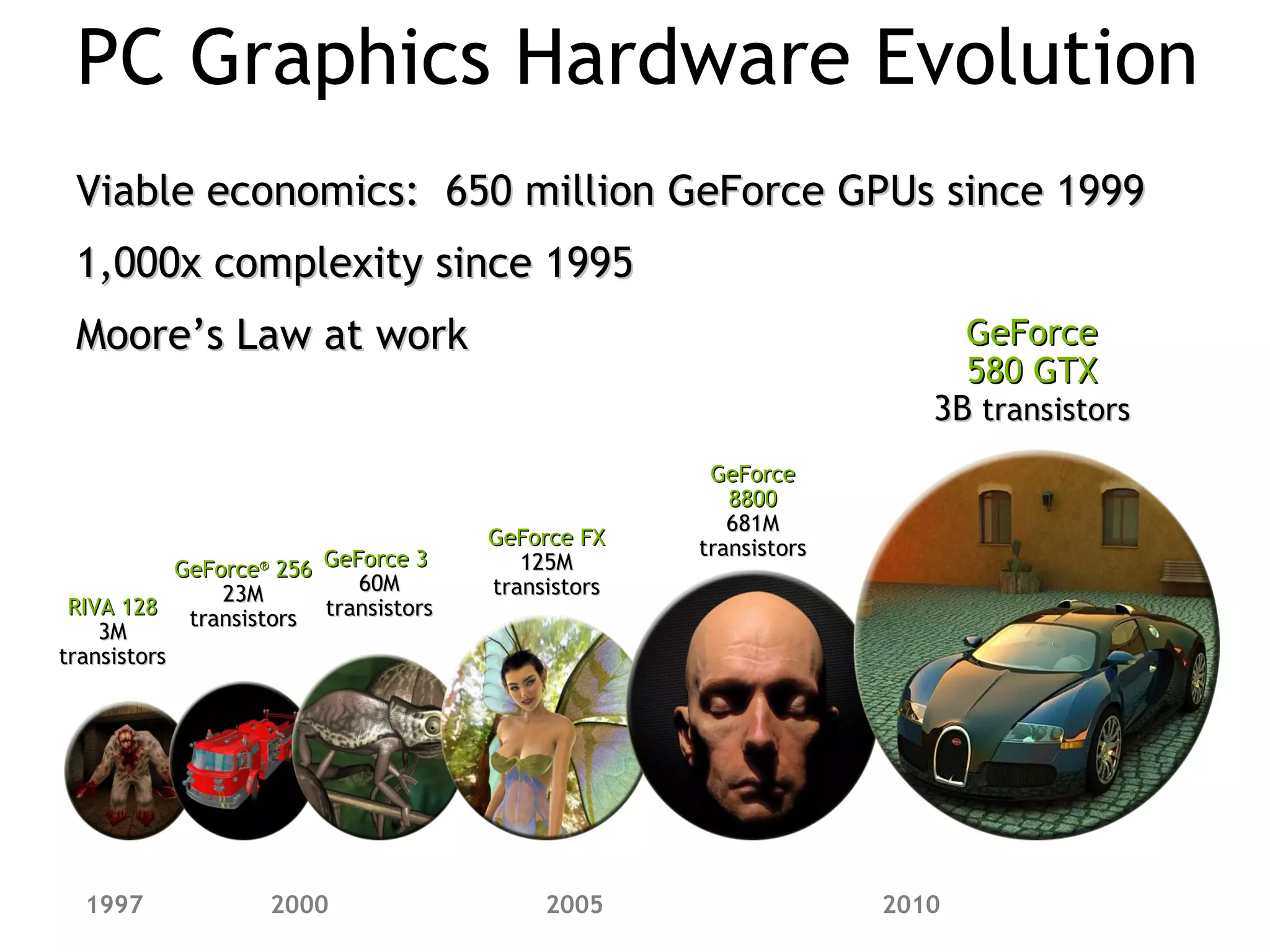

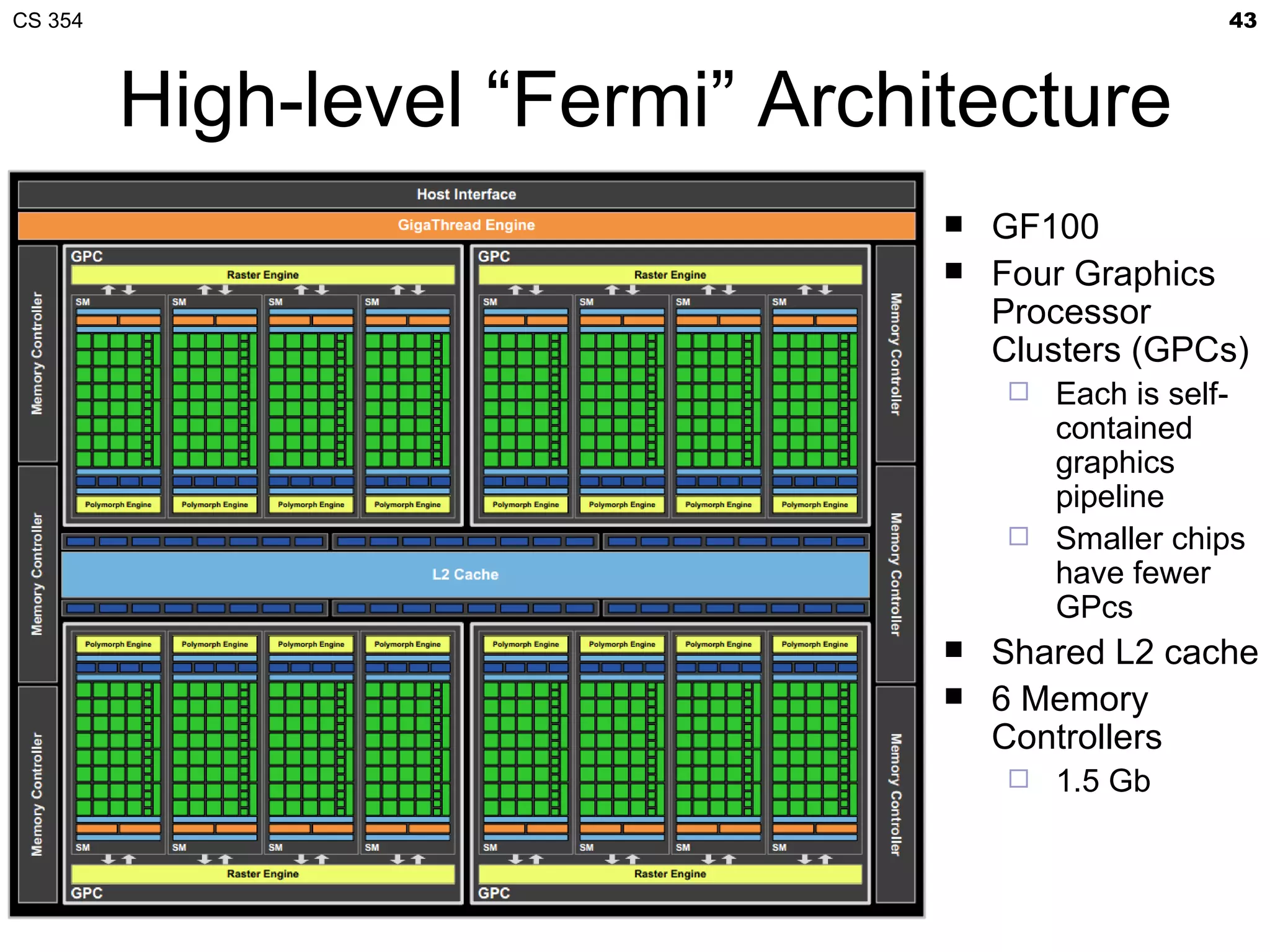
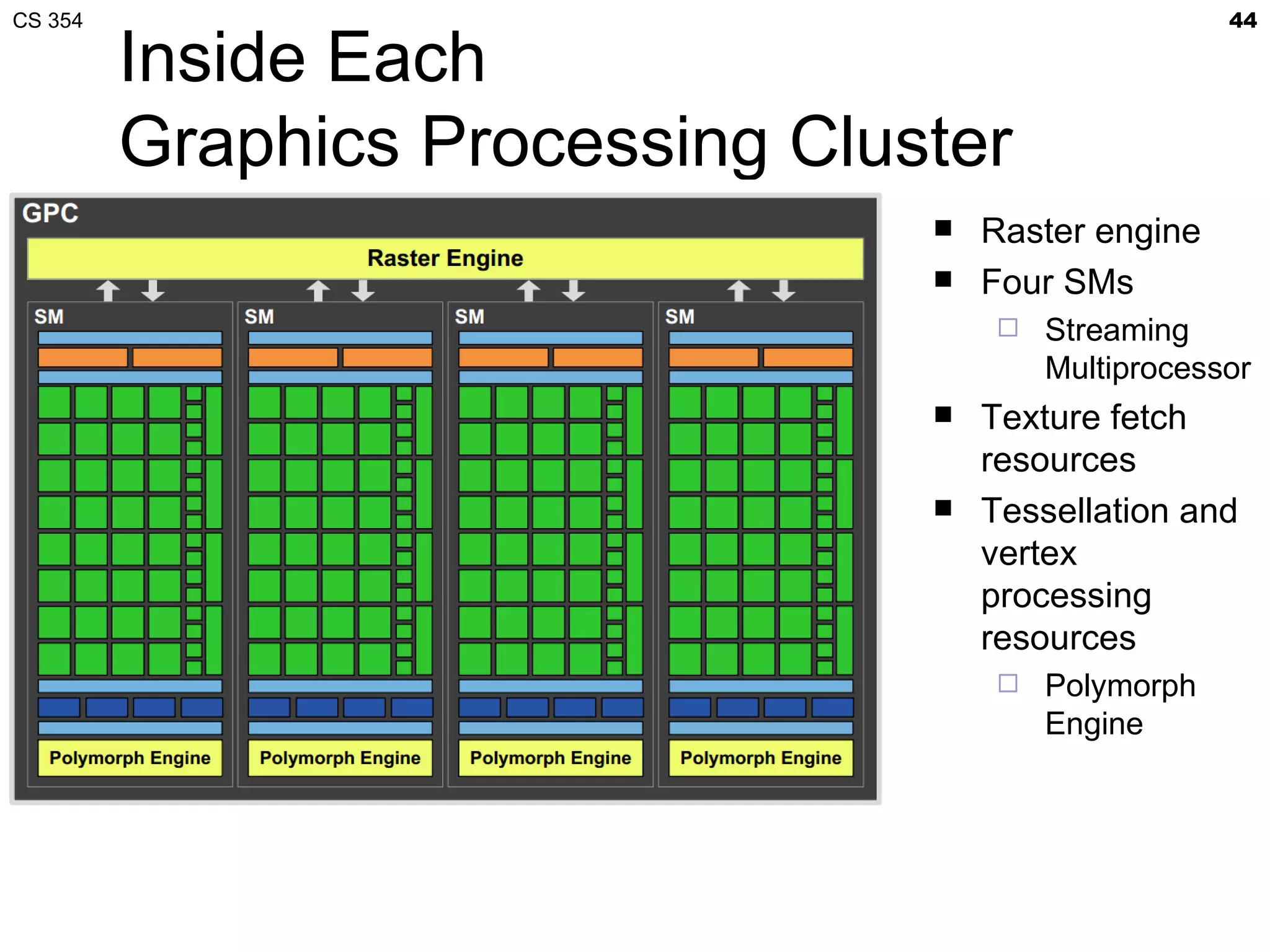
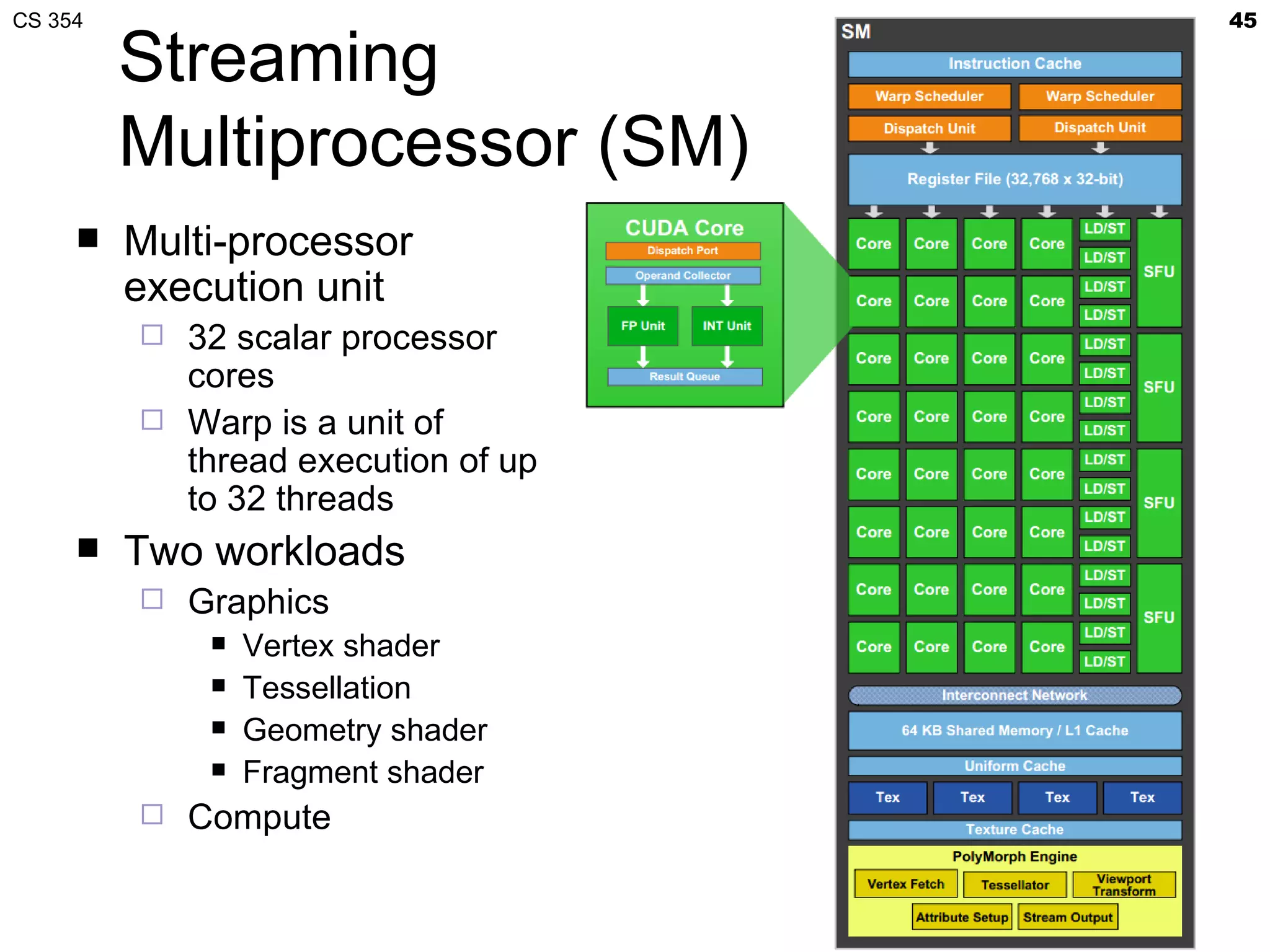
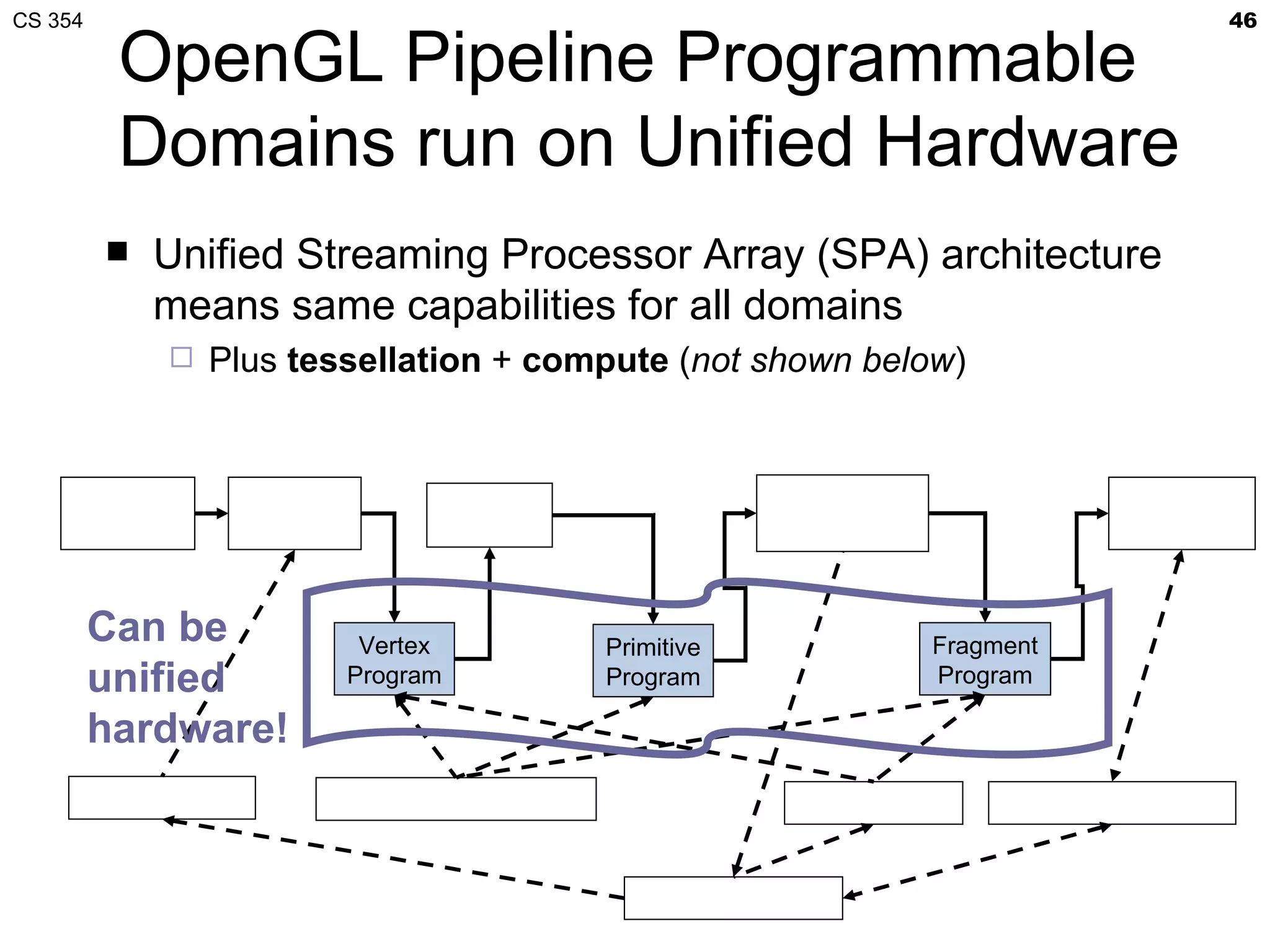
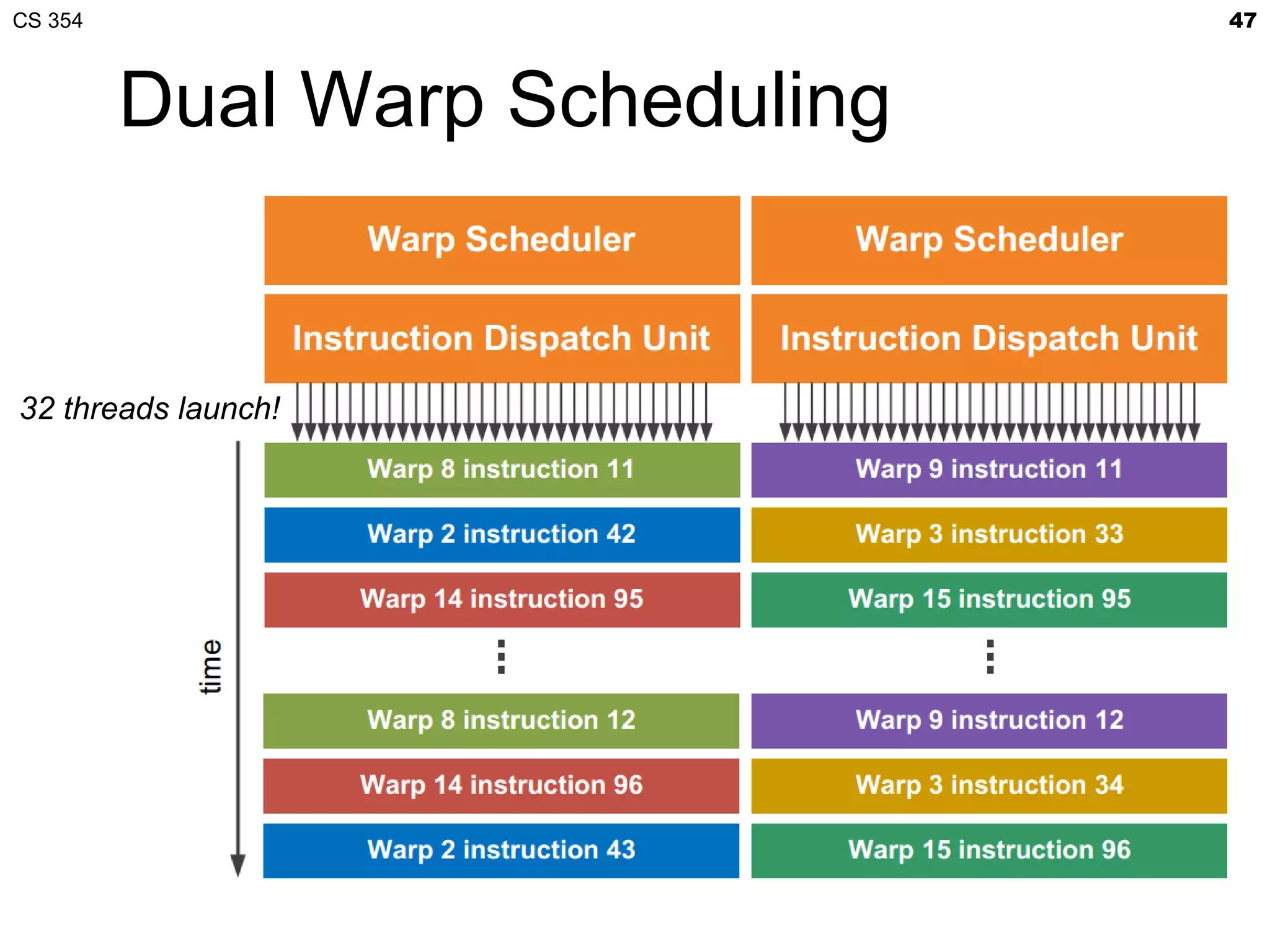
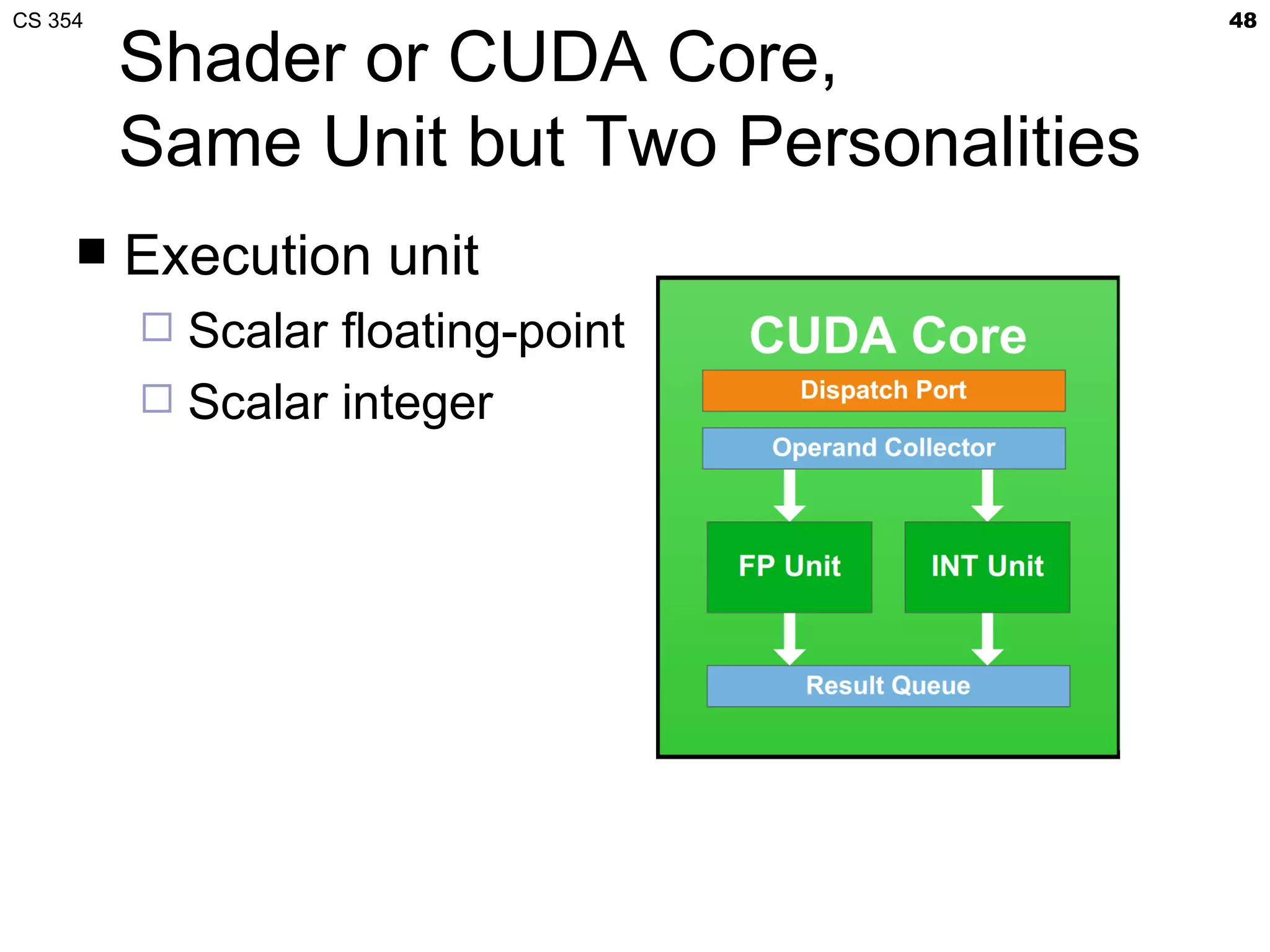
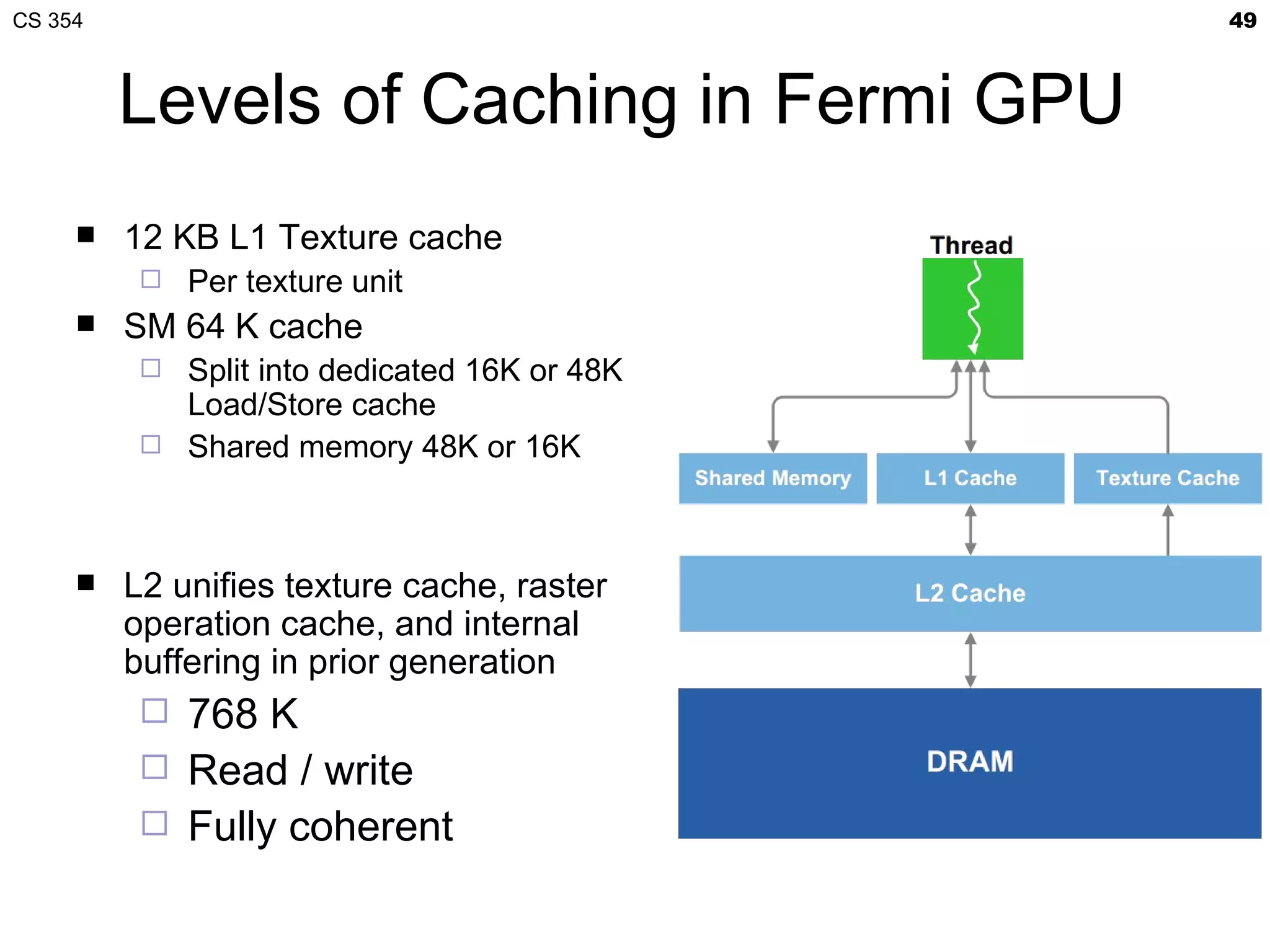
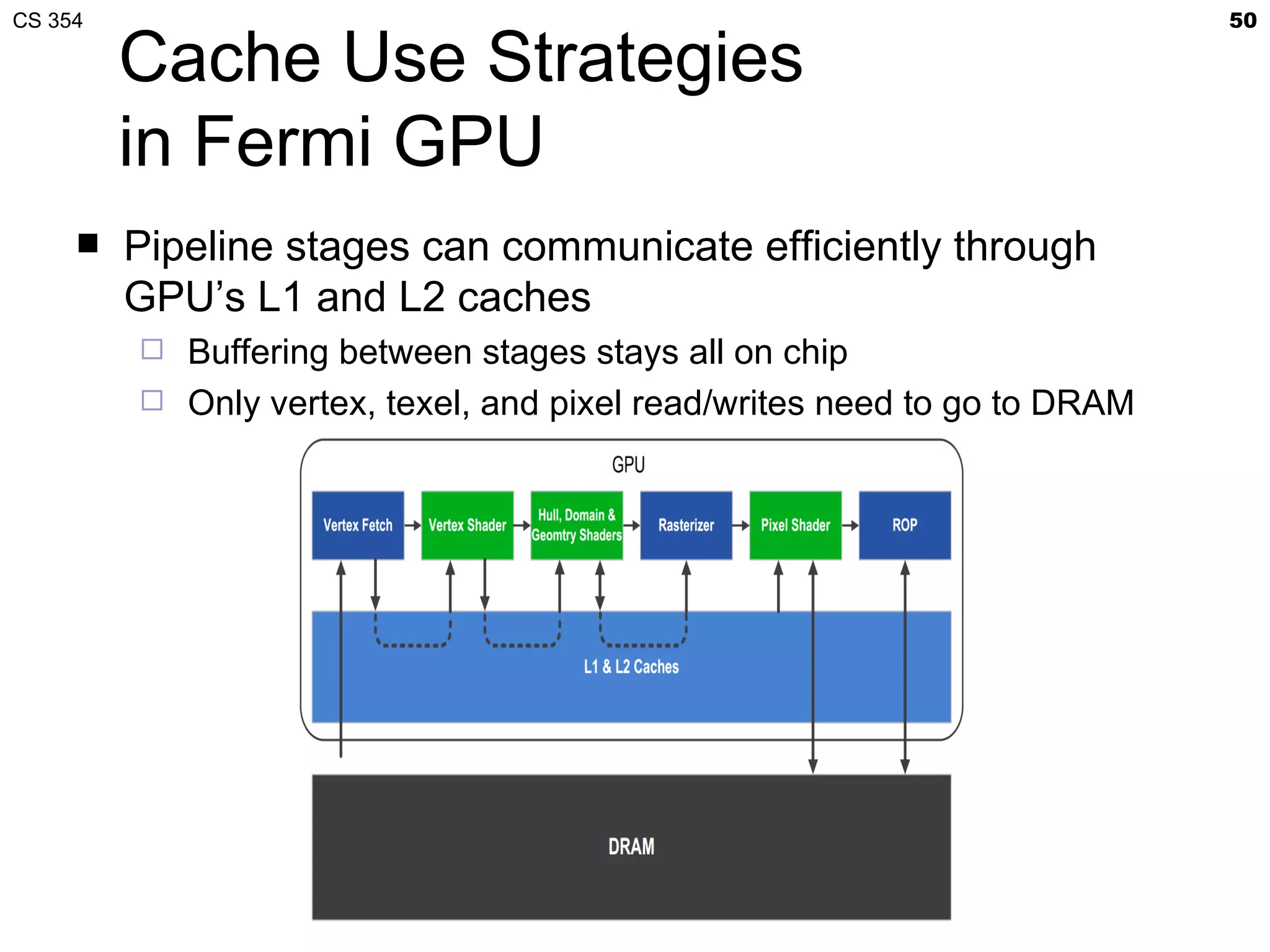



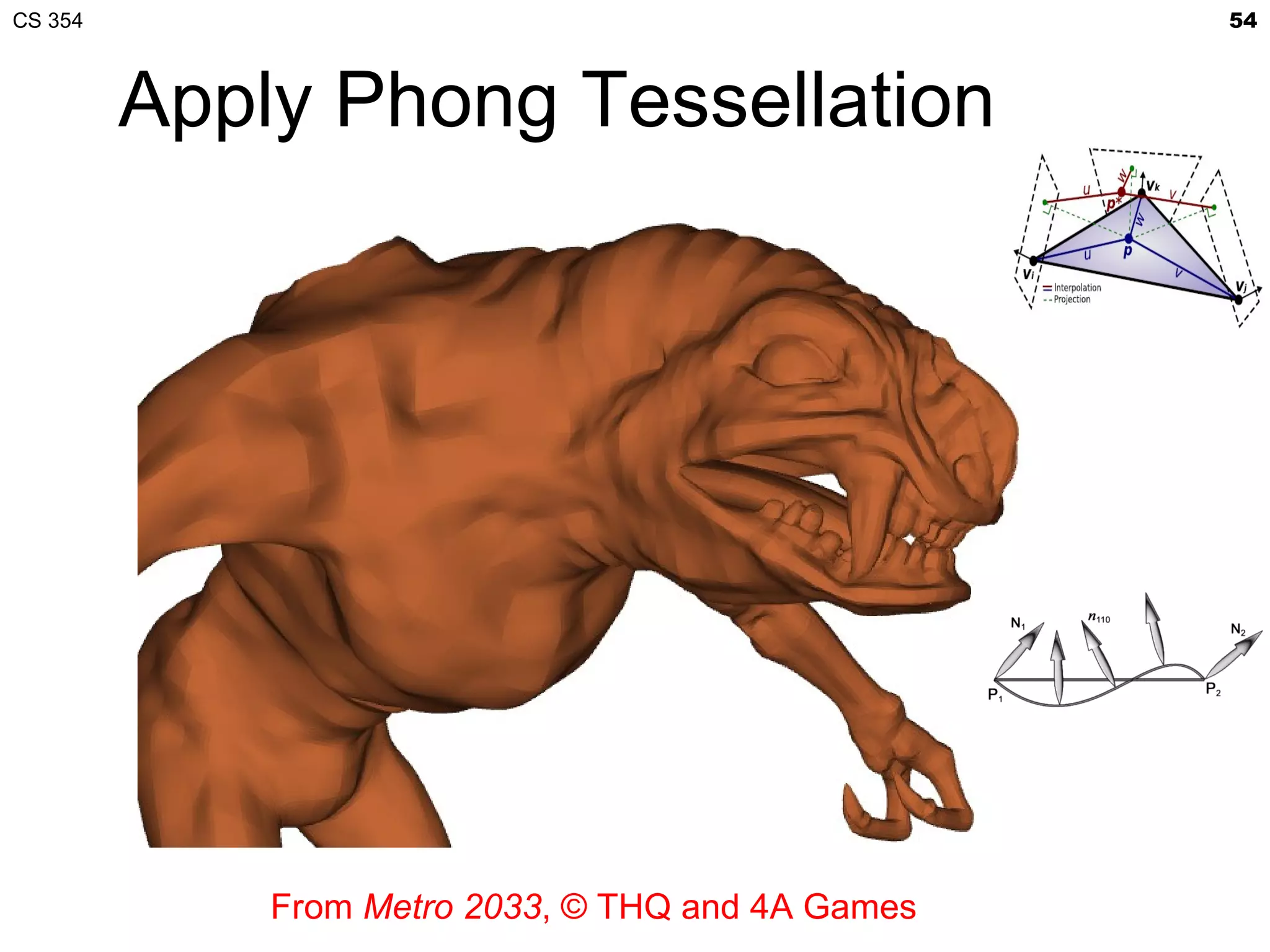








This document discusses a lecture on GPU architecture given by Mark Kilgard at the University of Texas on March 6, 2012. The lecture covers the architecture of graphics processing units and how they have evolved over the past six years. It also includes an in-class quiz, information about homework and projects, and the professor's office hours.










































![[Harvard CS264] 06 - CUDA Ninja Tricks: GPU Scripting, Meta-programming & Aut...](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201106-cudaninjasharetmp-110301171948-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

