as requested and identifies the 3 main points from the document in concise sentences: understanding process management, understanding semaphores, and inter process communication.
HOME PREVIOUS TOPIC
NEXT
PREVIOUS QUESTION PAPERS
FOR OS
CPP TUTORIALS
2
3.
Recap
Inlast class, you have learnt :
• Multilevel Queue Scheduling
• Types of Queues
• Multilevel Feed Back Queue Scheduling
3
4.
Objectives
On completionof this class, you would be able to
know
• Understand Semaphores
• Inter Process Communication
4
5.
Semaphores
• Semaphore isbasically a synchronizing tool
• Used as a solution to critical section problems
What is critical section?
– To control access to shared resources, we declare a
section of code to be critical
– We regulate access to that section
5
6.
Semaphores
Example:
• System consisting of n threads {TO, T1…Tn-1}
• Each thread has a segment of code, called “critical section”
• Where the thread may be changing common variables,
updating a table & so on
• Important feature of a system is that, when one thread is
executing in its critical section, no other thread is allowed
to execute in its critical section 6
7.
Semaphores
•Semaphore is usedto identify whether the operation is to
be executed or the CPU has to wait
• Semaphore is an integer, it is accessed through two
operations ie. wait and signal
• Wait is used to test for operation
7
• Signal is used to increment the integer
8.
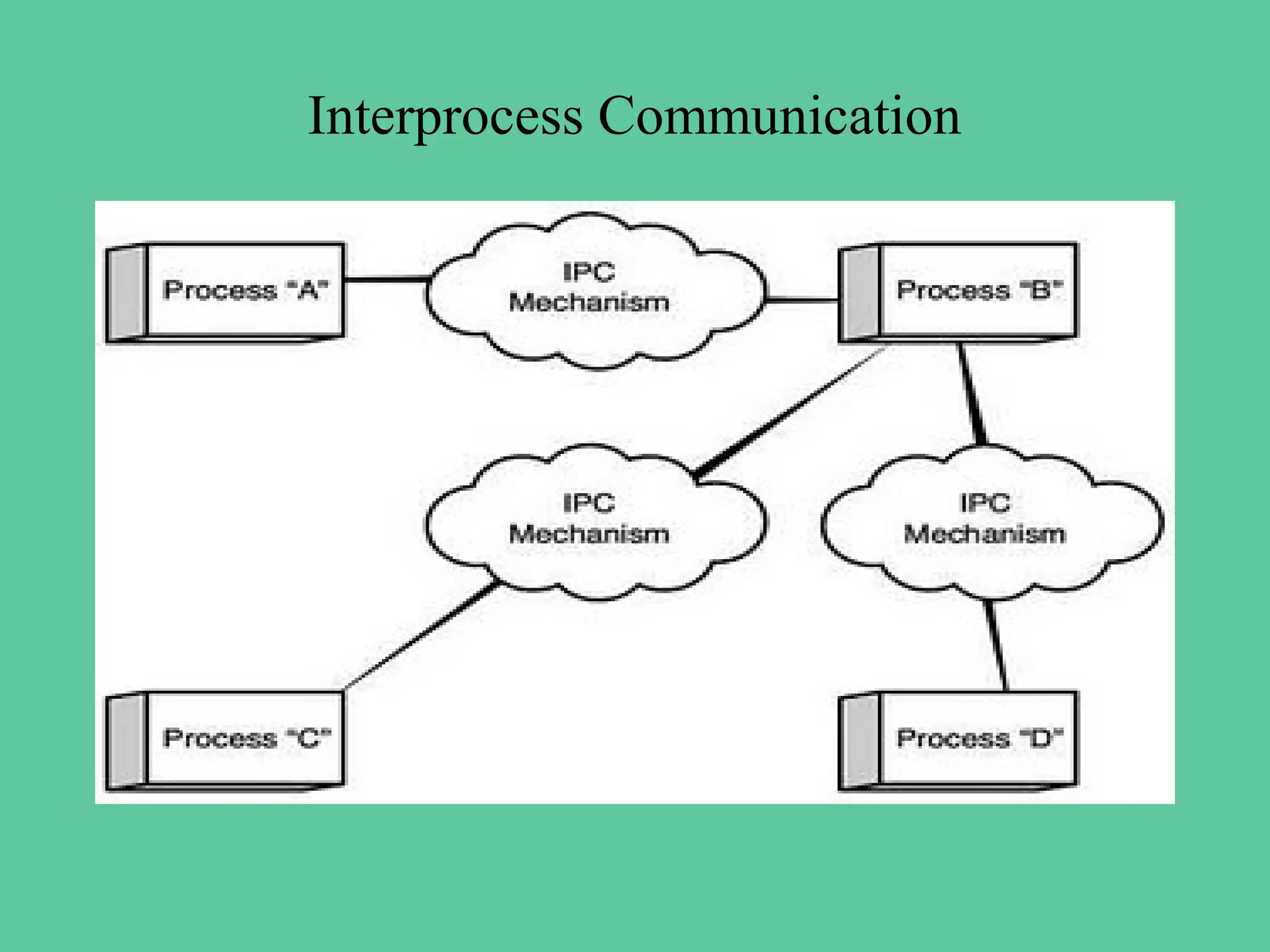
Interprocess Communication
• Interprocess communication provides a mechanism
•to allow processes to communicate and to synchronize
their actions
•without sharing the same address space
• IPC is provided by message passing systems
• If a Process want to communicate they must send
message and receive messages from each other via a
communication link existing between them
8
Interprocess Communication
• Thislink can be implemented in many ways
– Direct or Indirect communication
– Symmetric or Asymmetric communication
– Automatic or Explicit buffering
– Send a copy directly or Send by reference
– Fixed sized or Variable sized messages
10
11.
Summary
In this class,you have learnt :
---- Critical Section problem
---- Semaphores
---- Inter Process Communication
11
12.
Frequently Asked Questions
1.What is a Semaphores?
2. Explain Critical Section problem
3. Explain Inter Process Communication
12