The document discusses various techniques for implementing subprograms in programming languages. It covers:
1) The general semantics of calls and returns between subprograms and the actions involved.
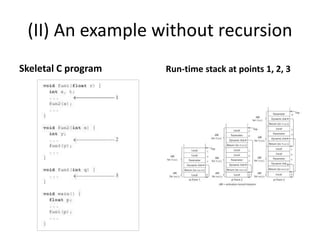
2) Implementing simple subprograms with static local variables and activation records.
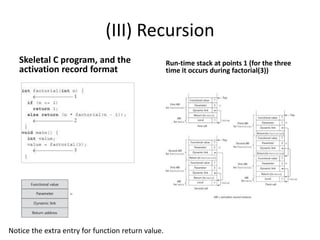
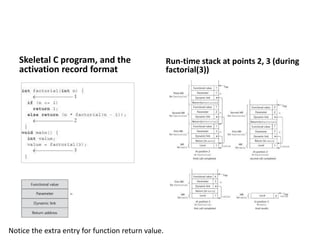
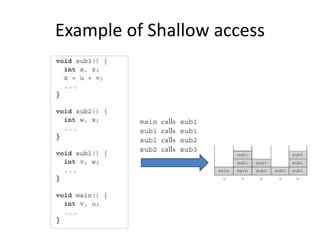
3) Implementing subprograms with stack-dynamic local variables using run-time stacks and activation records.
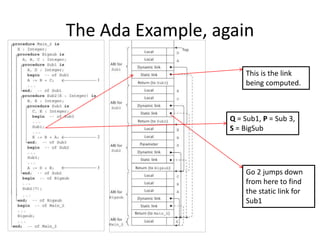
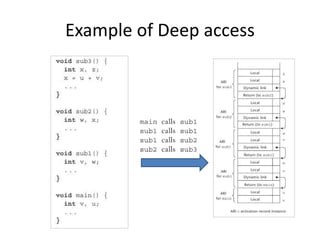
4) Techniques for implementing nested subprograms using static linking chains to access nonlocal variables.