Downloaded 11 times






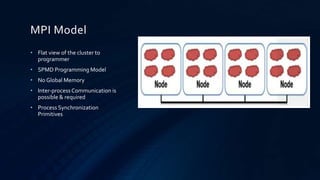




















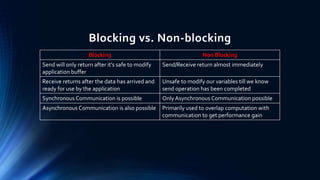

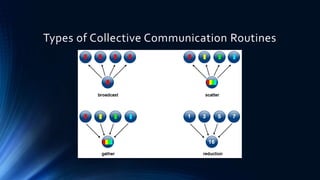








This document provides an overview of programming a heterogeneous computing cluster using the Message Passing Interface (MPI). It begins with background on heterogeneous computing and MPI. It then discusses the MPI programming model and environment management routines. A vector addition example is presented to demonstrate an MPI implementation. Point-to-point and collective communication routines are explained. Finally, it covers groups, communicators, and virtual topologies in MPI programming.



































































