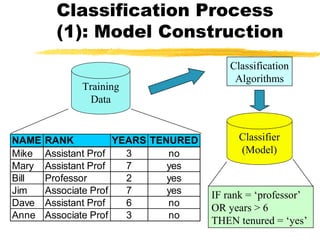
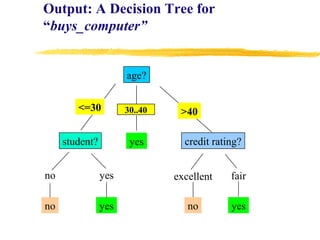
Based on the decision tree, this case would be classified as follows:
1. Outlook is overcast, so go to the overcast branch
2. For overcast, there are no further tests, so the leaf node is reached
3. The leaf node predicts Play=yes
Therefore, for the given conditions, Play=yes.