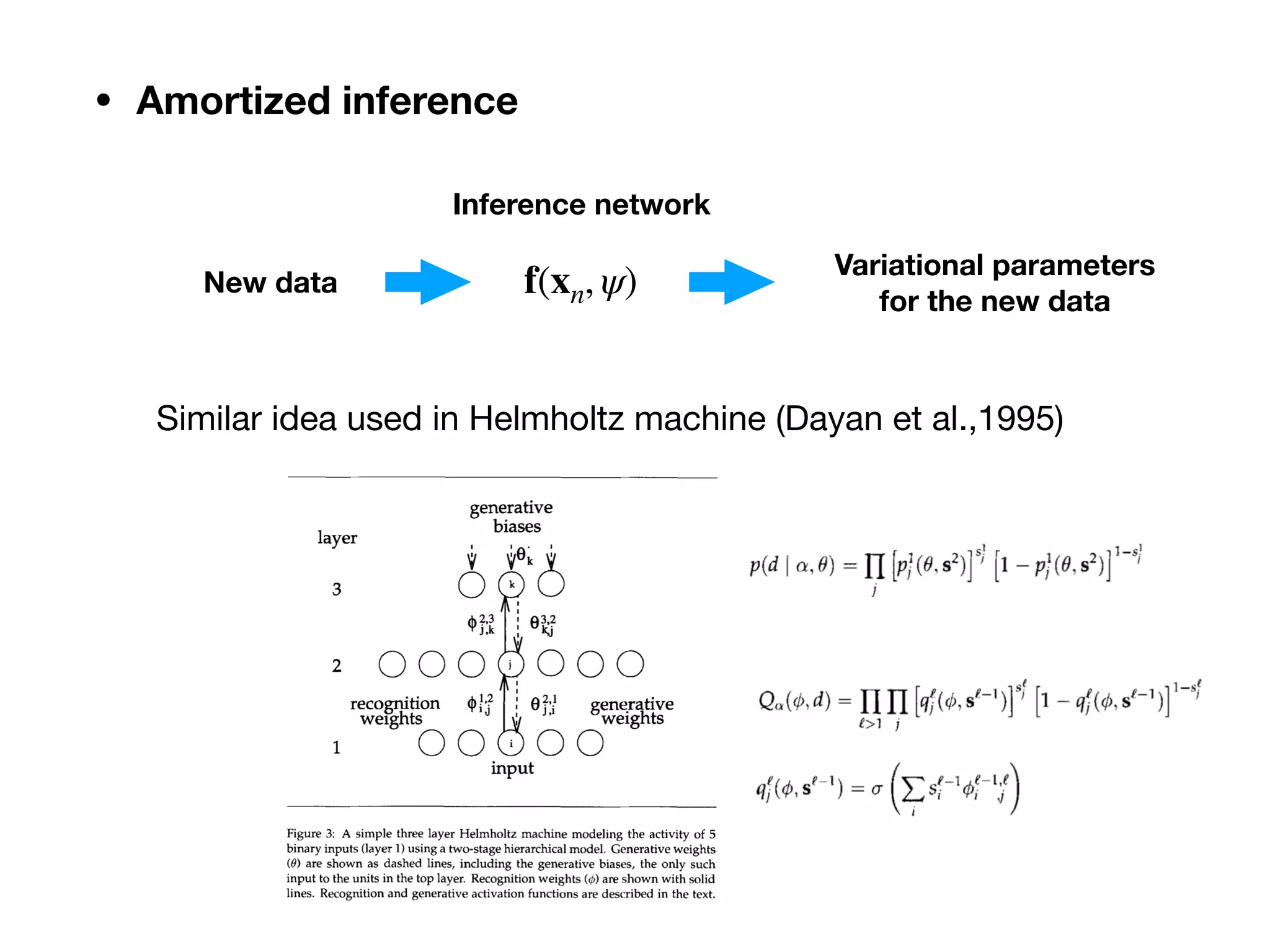
Download as PDF, PPTX

![6.1 Variational autoencoder
• Generative model
p(zn) = 𝒩(zn ∣ 0, I),
p(xn ∣ zn, W) = 𝒩 (xm ∣ f(zn; W), λ−1
x I)
(6.1)
(6.2)
f : generative network or decoder
• Posterior and objective
p(Z, W ∣ X) =
p(W)∏
N
n=1
p(xn ∣ zn, W)p(zn)
p(X)
(6.3)
DKL [q(Z, W) ∣ p(Z, W|X)] (6.4)
6.1.1 Generative and inference networks
6.1.1.1 Generative model and posterior approximation](https://image.slidesharecdn.com/20191123bayes-dl-jp-191121040236/75/20191123-bayes-dl-jp-2-2048.jpg)

![DKL [q(Z, W; X, ϕ, ξ) ∥ p(Z, W|X)]
= − {E[ln p(X, Z, W)] − E[ln q(Z; X, ψ)] − E[ln q(W; ξ)]} + ln p(X)
(6.9)
∴ ln p(X) − DKL [q(Z, W; X, ϕ, ξ) ∥ p(Z, W|X)]
= E[ln p(X, Z, W)] − E[ln q(Z; X, ψ)] − E[ln q(W; ξ)]
= ℒ(ψ, ξ) (6.10)
Maximize w.r.t. andℒ(ψ, ξ) ψ ξ
(6.11)
ℒ 𝒮(ψ, ξ)
=
N
M ∑
n∈𝒮
{E[ln p(xn ∣ zn, W)] + E[ln p(zn)] − E[ln q(zn)]}+
E[ln p(W)] − E[ln q(W; ξ)]
6.1.1.2 Training by variational inference](https://image.slidesharecdn.com/20191123bayes-dl-jp-191121040236/75/20191123-bayes-dl-jp-6-2048.jpg)
![• Gradients of parameters
∇ξℒ 𝒮(ψ, ξ)
=
N
M ∑
n∈𝒮
∇ξE[ln p(xn ∣ zn, W)] + ∇ξE[ln p(W)] − ∇ξE[ln q(W)]
(6.12)
∇ψ ℒ 𝒮(ψ, ξ)
=
N
M ∑
n∈𝒮
{∇ψ E[ln p(xn ∣ zn, W)] + ∇ψ E[ln p(zn)] − ∇ψ E[ln q(zn)]}
(6.13)
ξ : variational parameter of q(W; ξ)
ψ : inference network parameter of f(xn; ψ)](https://image.slidesharecdn.com/20191123bayes-dl-jp-191121040236/75/20191123-bayes-dl-jp-7-2048.jpg)

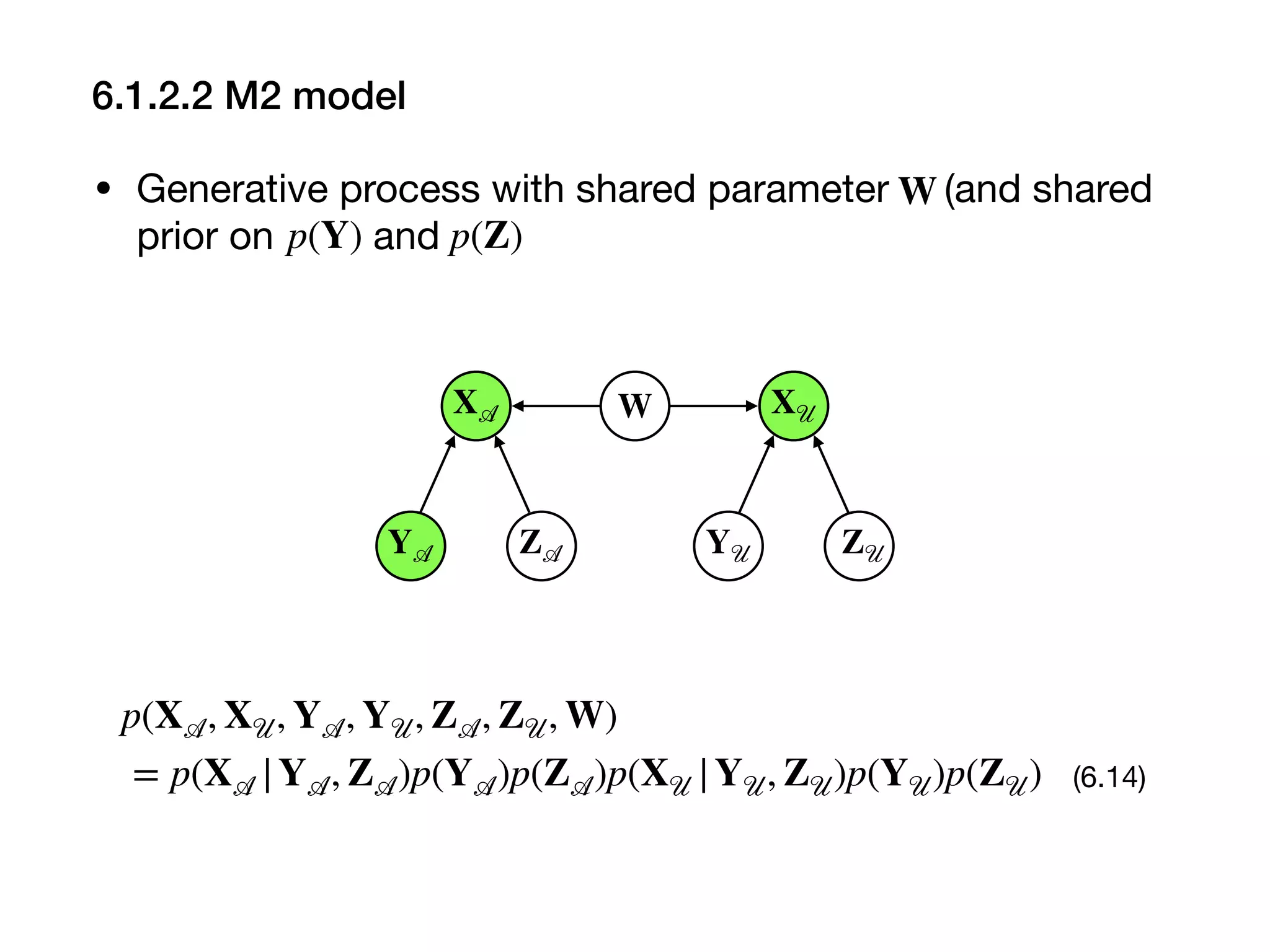

![• KL-divergence
DKL[q(Y 𝒰, Z 𝒜, Z 𝒰, W; X 𝒜, Y 𝒜, X 𝒰, ξ, ψ ∥ p(Y 𝒰, Z 𝒜, Z 𝒰, W ∣ X 𝒜, X 𝒰, Y 𝒜)]
= ℱ(ξ, ψ) + const . (6.18)
ℱ(ξ, ψ) = ℒ 𝒜(X 𝒜, Y 𝒜; ξ, ψ) + ℒ 𝒰(X 𝒰; ξ, ψ) − DKL[q(W; ψ) ∥ p(W)] (6.19)
ℒ 𝒜(X 𝒜, Y 𝒜; ξ, ψ)
= E[ln p(X 𝒜 |Y 𝒜, Z 𝒜, W)] + E[ln p(Z 𝒜)] − E[ln q(Z 𝒜; X 𝒜, Y 𝒜, ψ)] (6.20)
ℒ 𝒰(X 𝒰; ξ, ψ) = E[ln p(X 𝒰 |Y 𝒰, Z 𝒰, W)] + E[ln p(Y 𝒰)] + E[ln p(Z 𝒰)]
−E[ln q(Y 𝒰; X 𝒰, ψ)] − E[ln q(Z 𝒰; X 𝒰, ψ)]
(6.21)
• Maximize w.r.t. andℱ(ξ, ψ) ξ ψ](https://image.slidesharecdn.com/20191123bayes-dl-jp-191121040236/75/20191123-bayes-dl-jp-11-2048.jpg)


![6.1.3.2 Importance weighted AE
ℒT = Ez(t)∼q(z(t))
[
ln
1
T
T
∑
t=1
p(x, z(t)
)
q(z(t); x) ]
≤ ln Ez(t)∼q(z(t))
[
1
T
T
∑
t=1
p(x, z(t)
)
q(z(t); x)]
= ln Ez(t)∼q(z(t))
[
1
T
T
∑
t=1
p(x|z(t)
)
p(z(t)
)
q(z(t); x) ]
= ln p(x)
(6.23)
• Equivalent to ELBO when T=1
• Larger T is, tighter the bound (appendix A in the paper):
ln p(x) ≥ ⋯ ≥ ℒt+1 ≥ ℒt ≥ ⋯ℒ1 = ℒ (6.24)](https://image.slidesharecdn.com/20191123bayes-dl-jp-191121040236/75/20191123-bayes-dl-jp-14-2048.jpg)

This document summarizes key aspects of variational autoencoders (VAEs): VAE is a generative model that learns a latent representation of data. It approximates the intractable posterior using an encoder network and maximizes a variational lower bound. Semi-supervised VAE models can incorporate unlabeled data by learning shared representations. VAEs have been extended for recurrent sequences, convolutional structures, disentangled representations, and multi-modal data. Importance weighted autoencoders provide a tighter evidence lower bound than standard VAEs.










































![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)






















![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)










