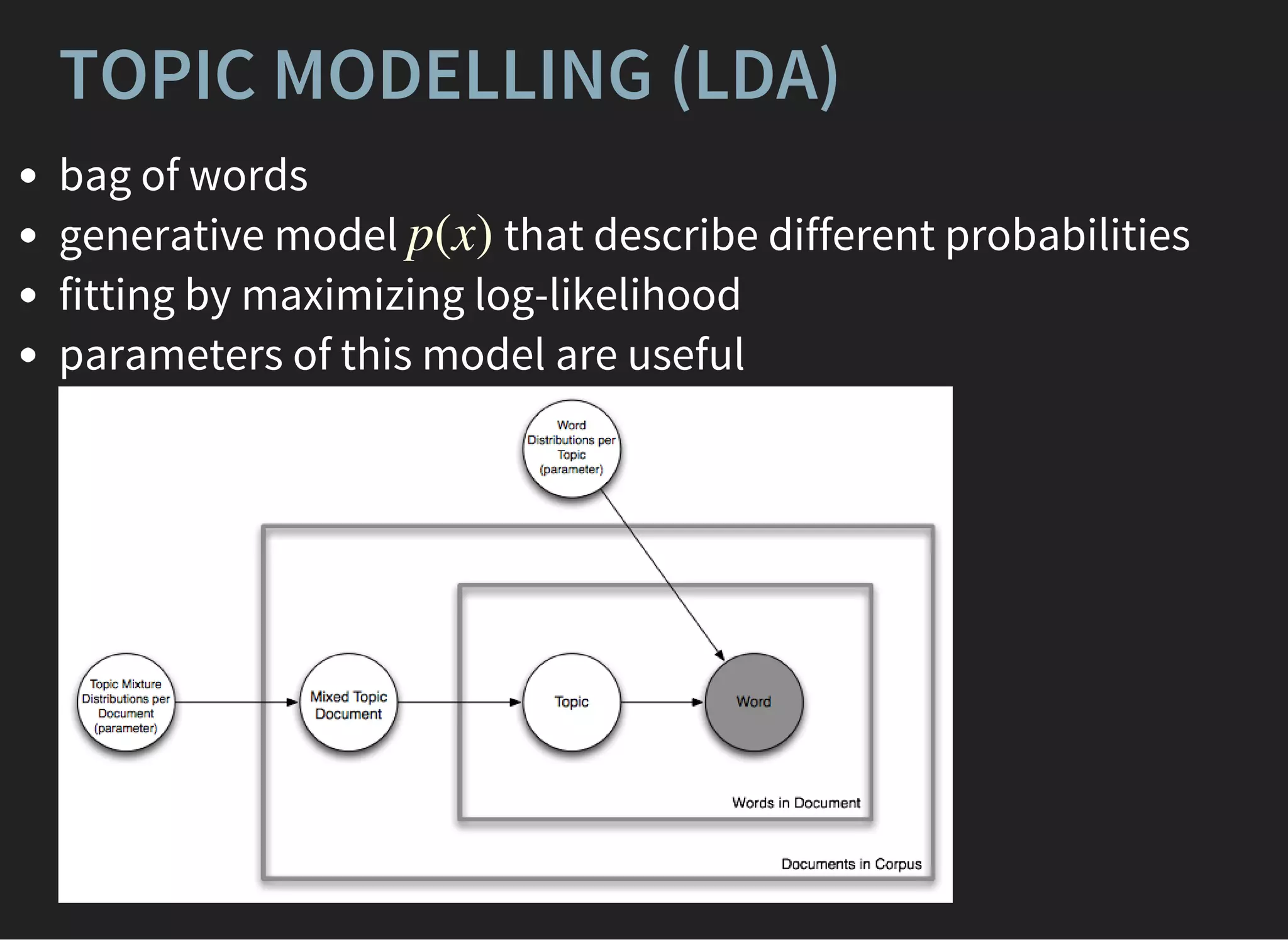
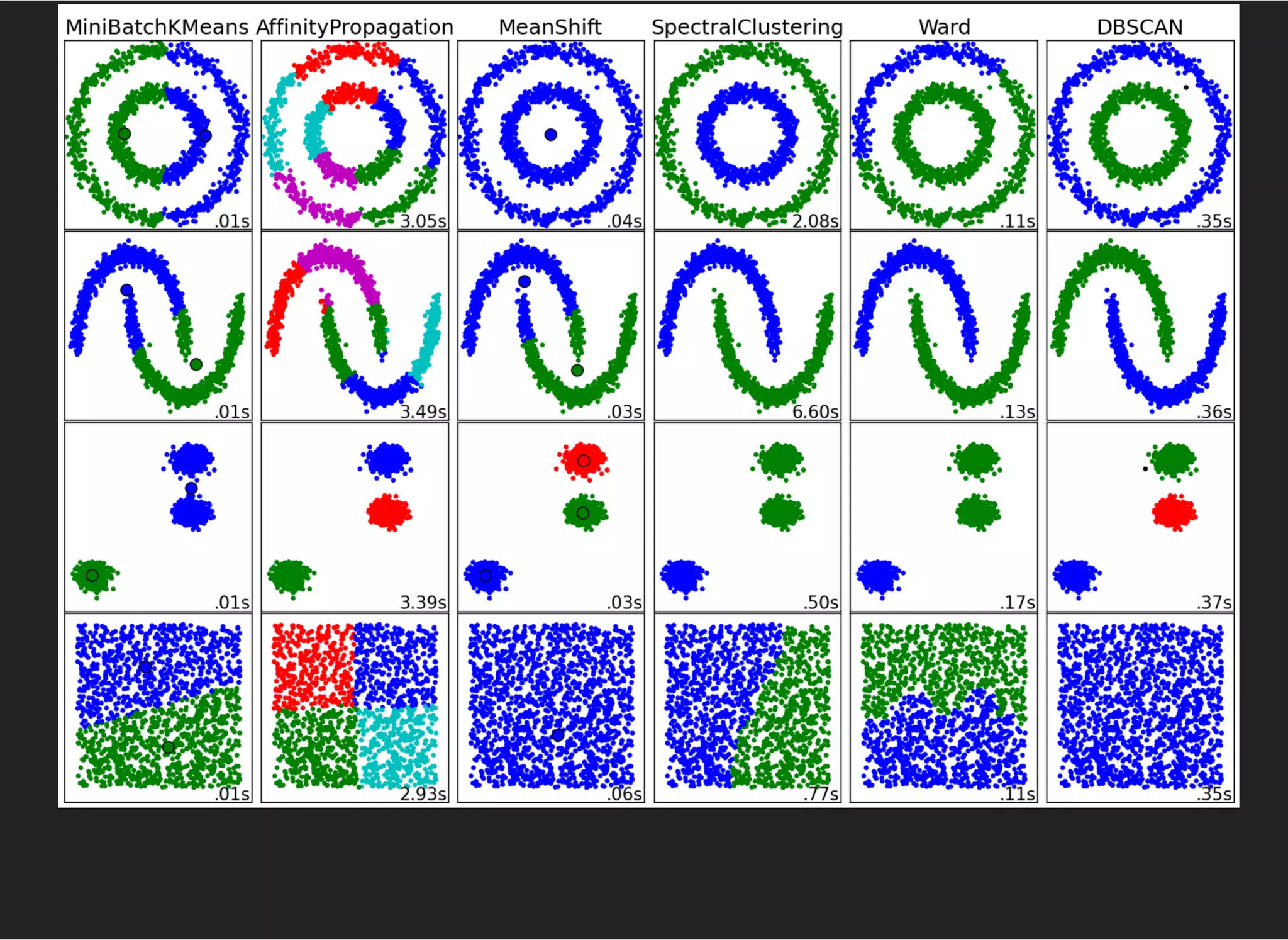
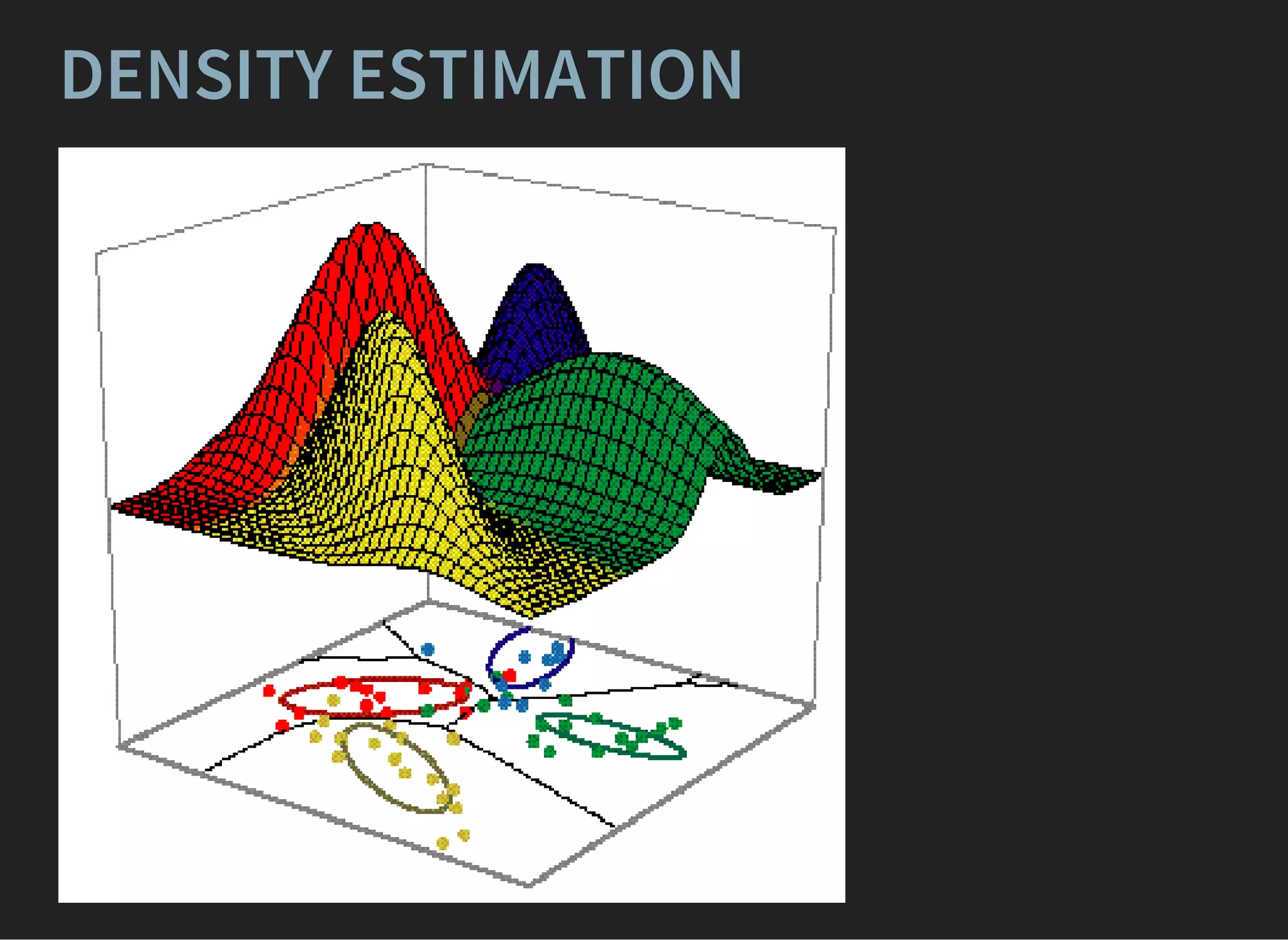
The document presents an advanced lecture on machine learning applications in high energy physics, exploring ensembling methods like boosting and bagging, as well as reweighting techniques for distributions. It details various classifiers, optimization techniques, and model evaluation strategies, including the use of Gaussian processes and principal component analysis. The lecture emphasizes practical implementations and considerations in the context of high-dimensional data and algorithm performance.



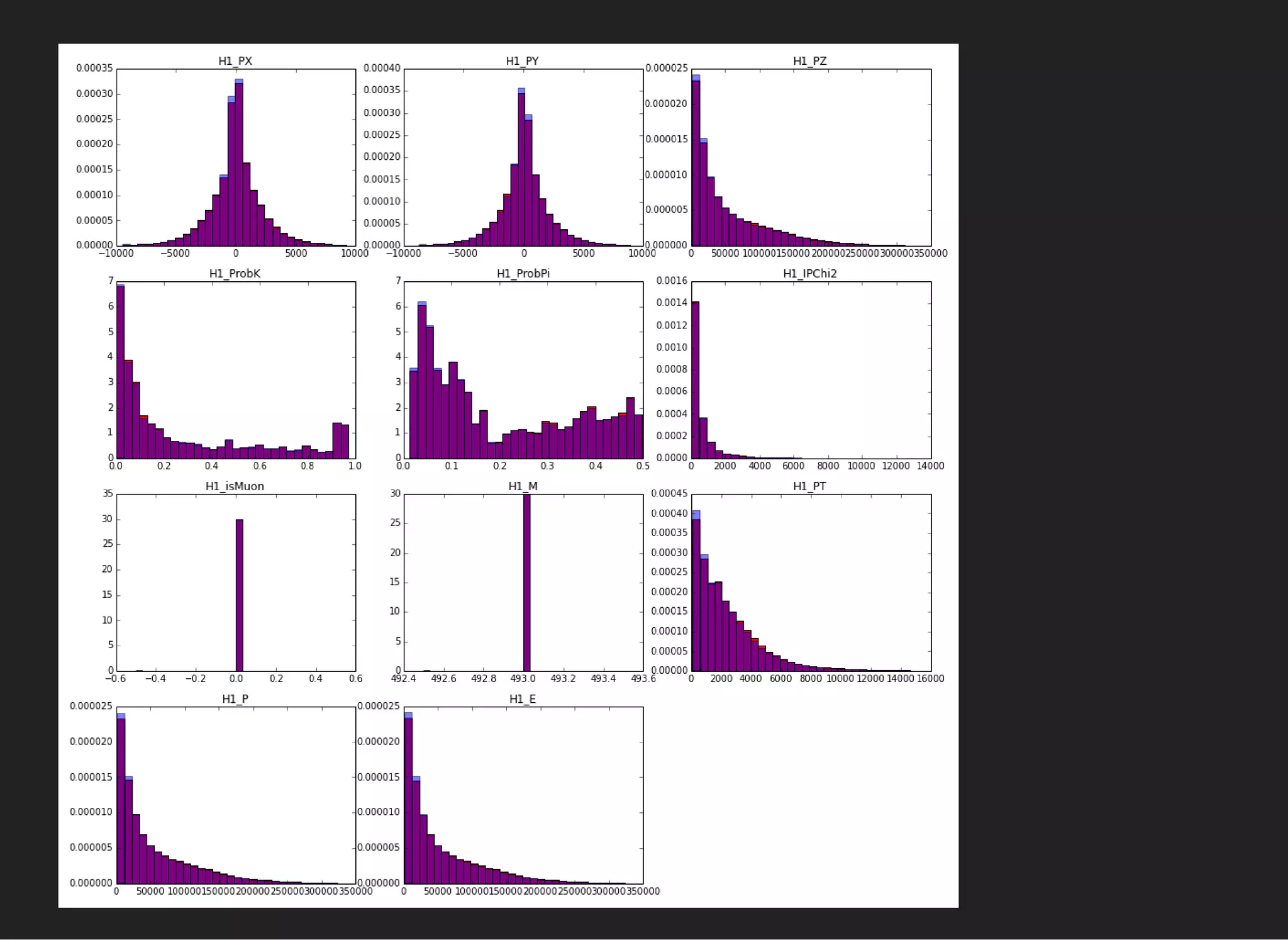
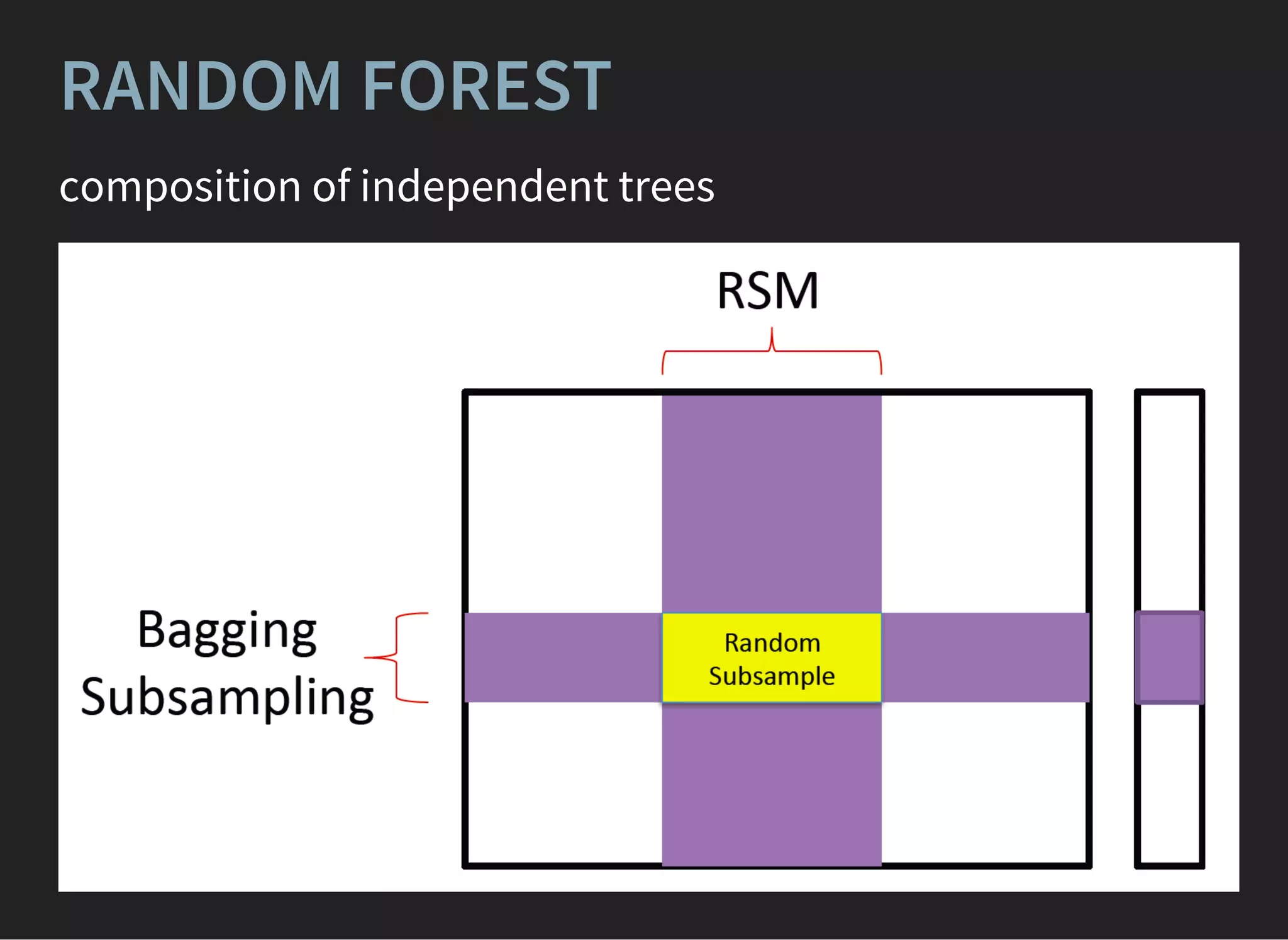




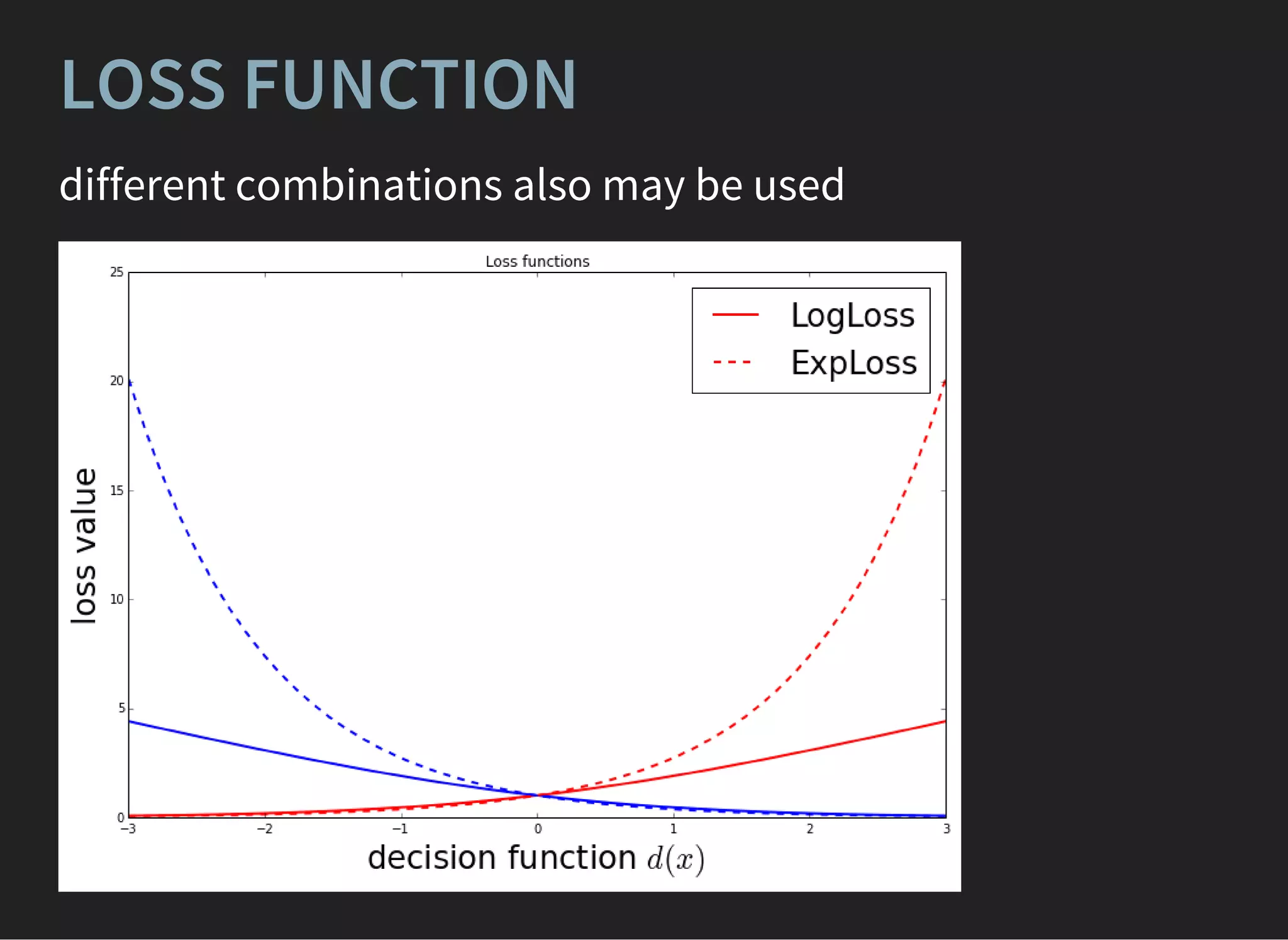

![BaggingClassifier(base_estimator=GradientBoostingClassifier(),
n_estimators=100)
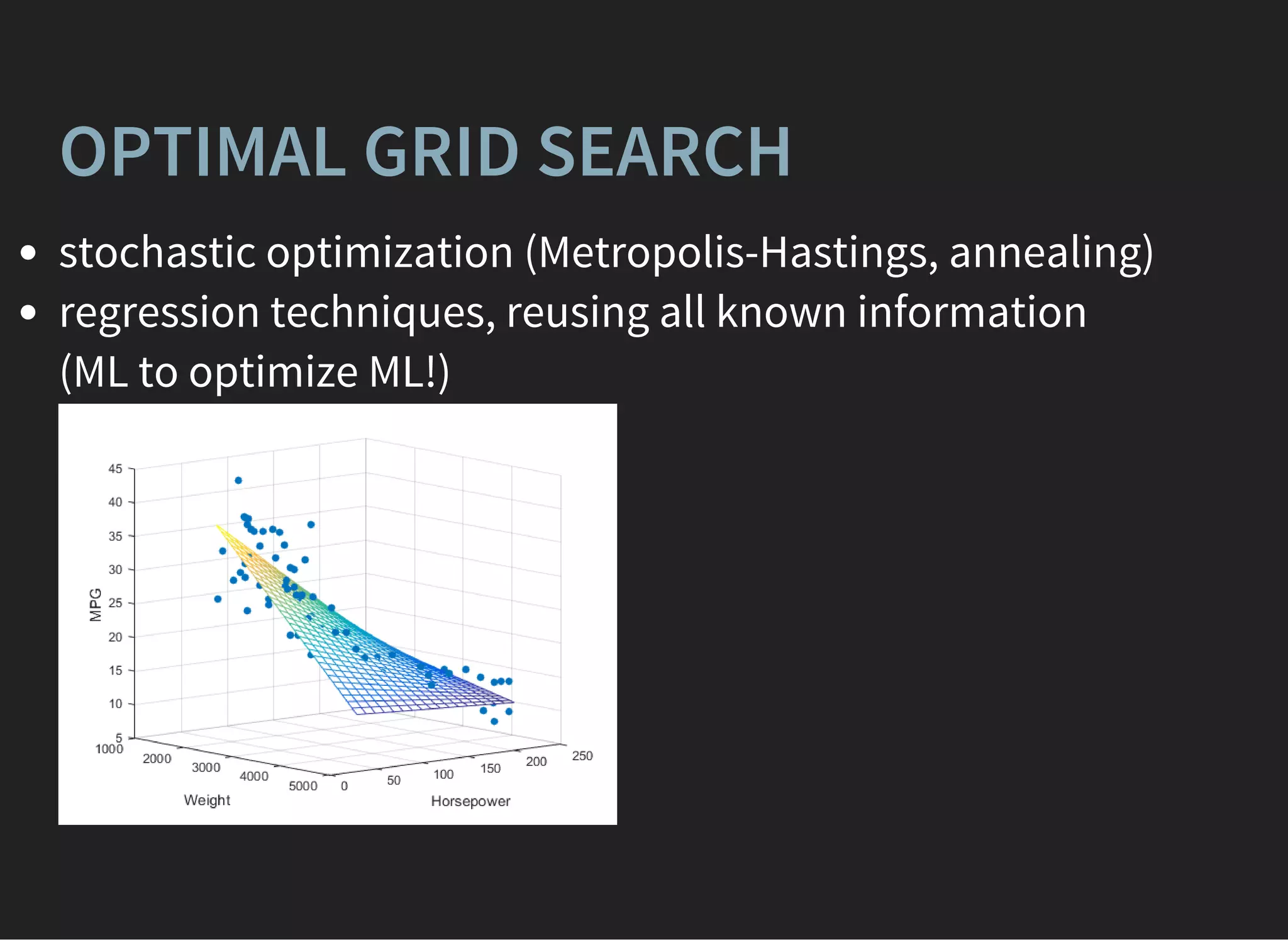
ENSEMBLES: BAGGING OVER
BOOSTING
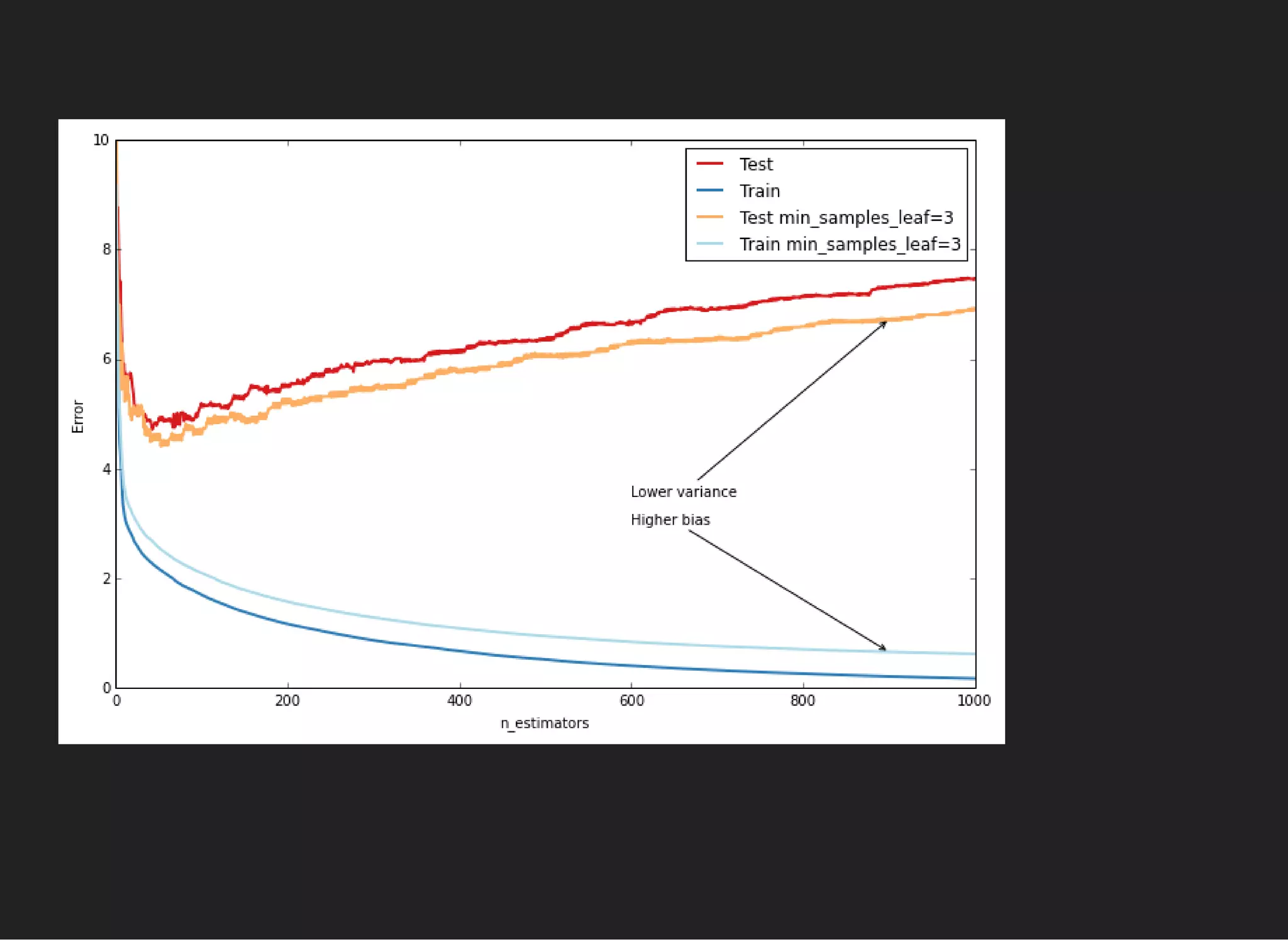
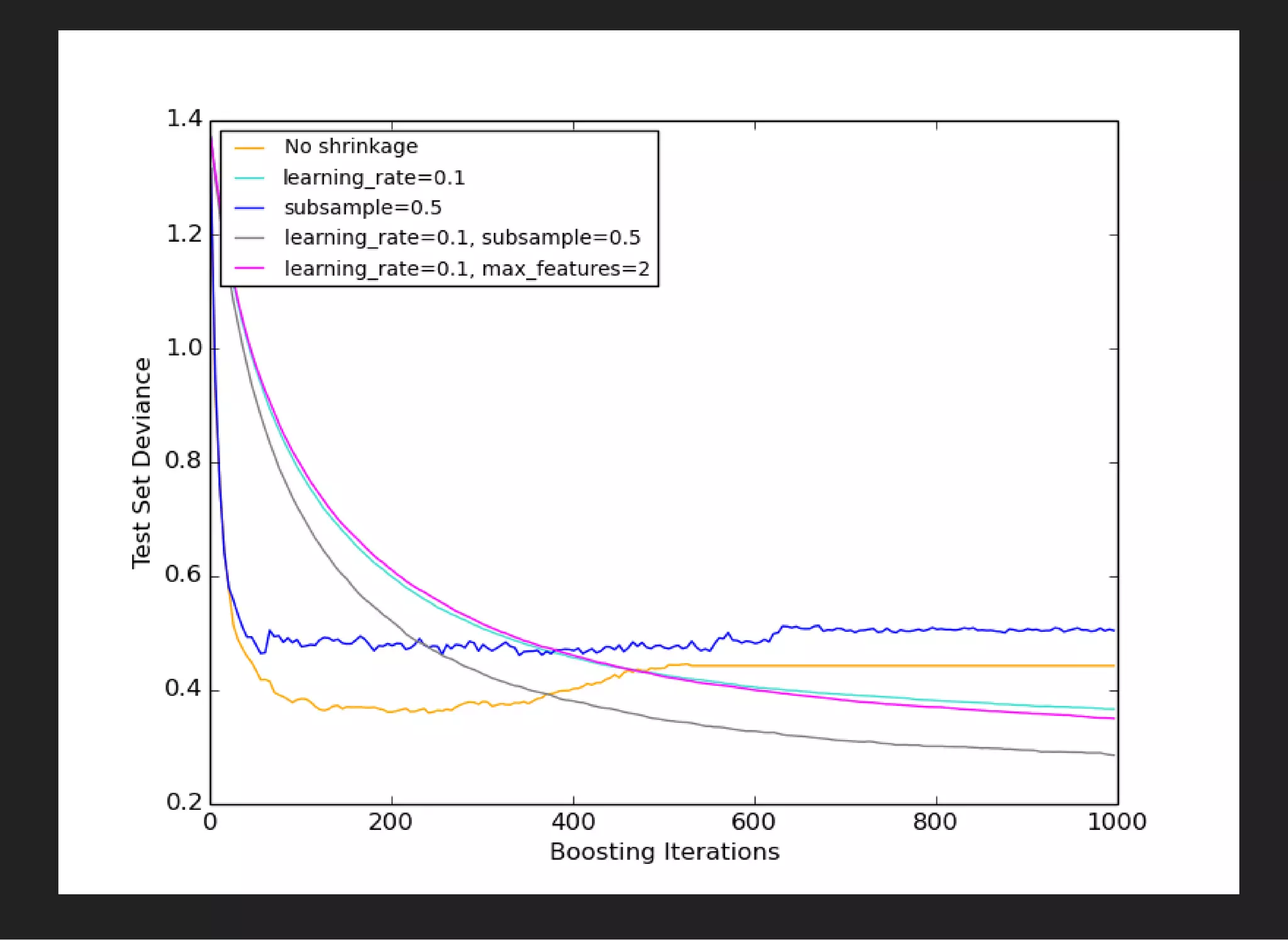
Different variations , are claimed to overcome single
GBDT.
[1] [2]
Very complex training, better quality if GB estimators are
overfitted](https://image.slidesharecdn.com/lecture4-150907124759-lva1-app6891/75/MLHEP-2015-Introductory-Lecture-4-15-2048.jpg)



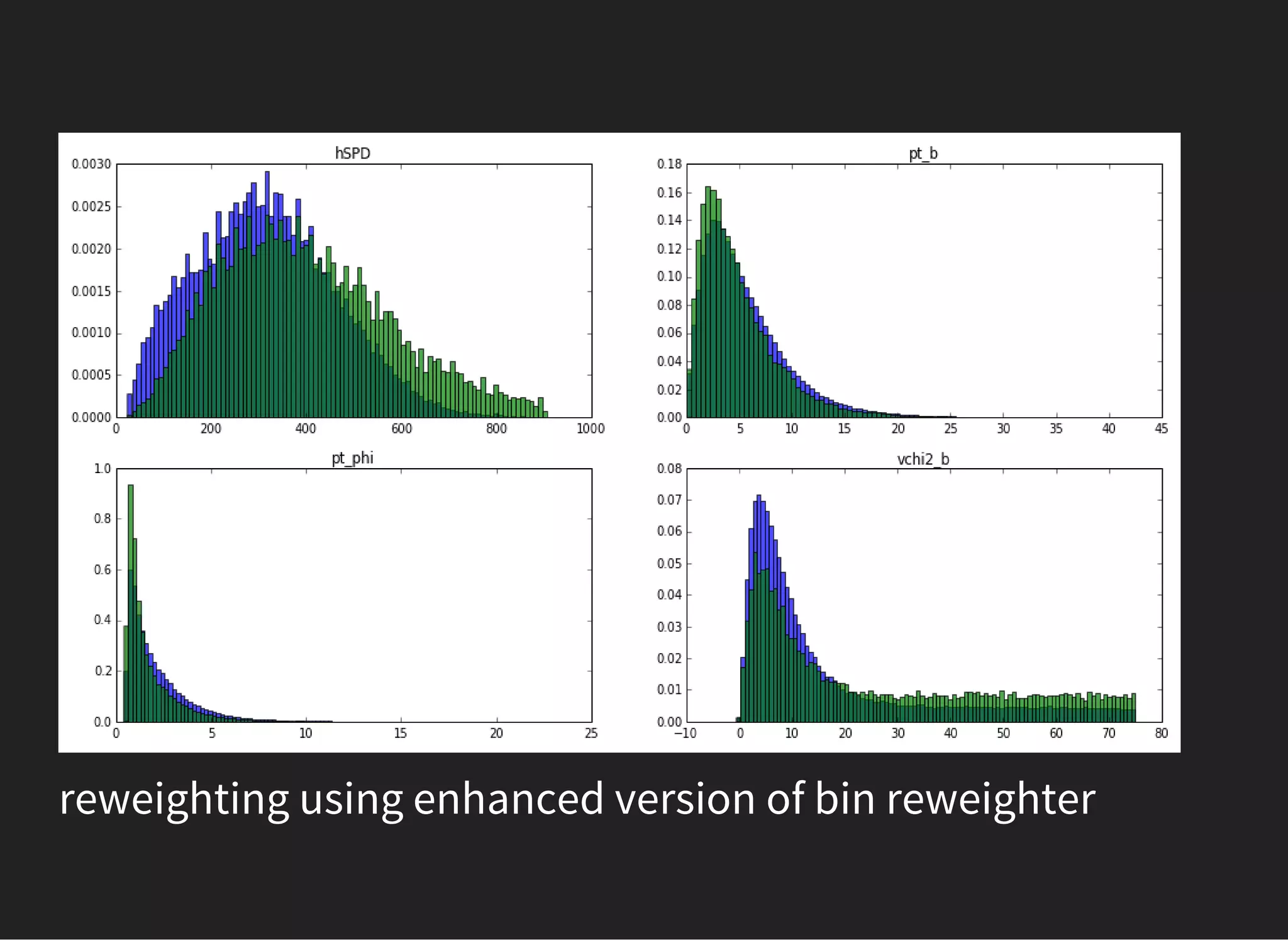
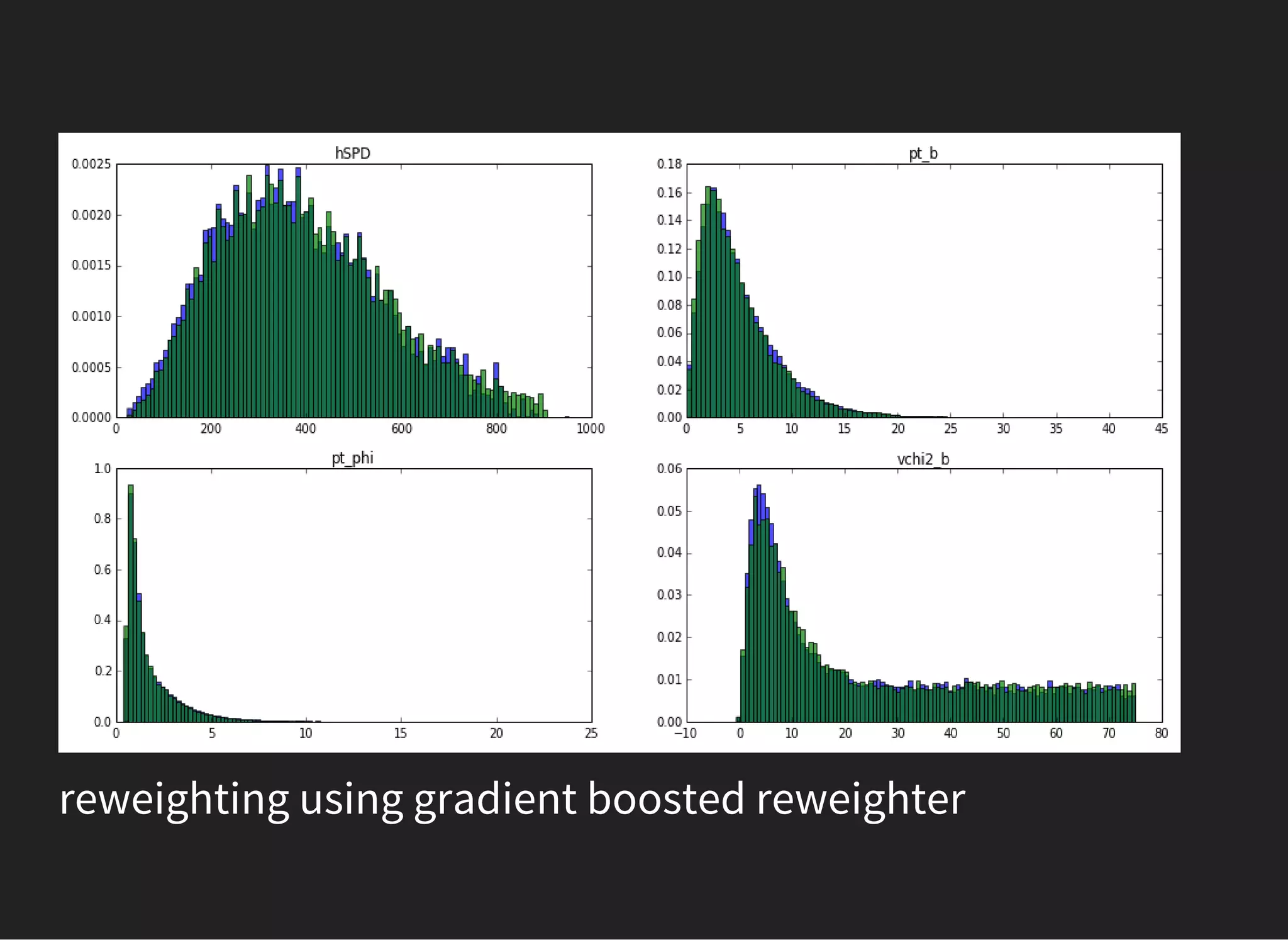



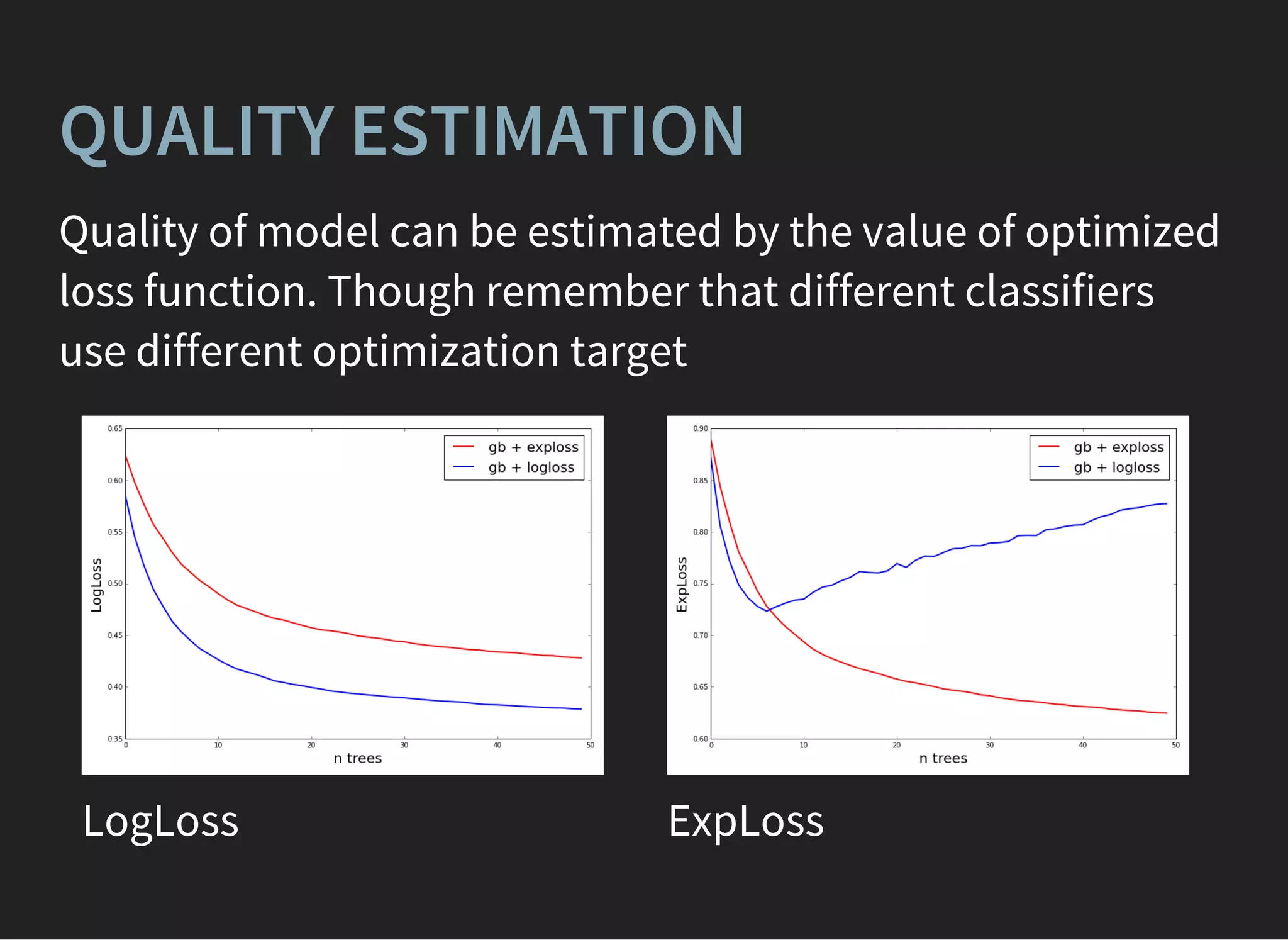
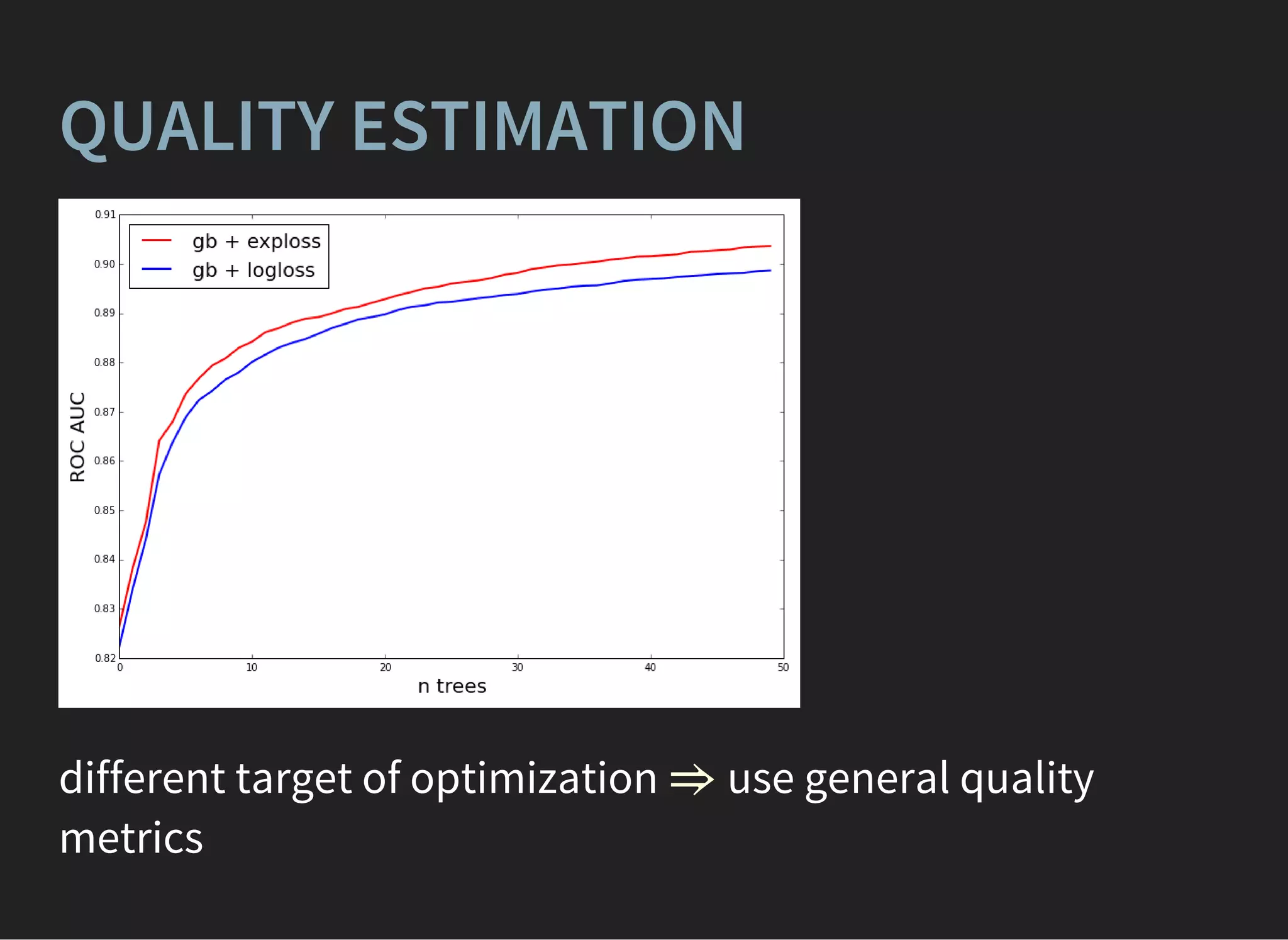












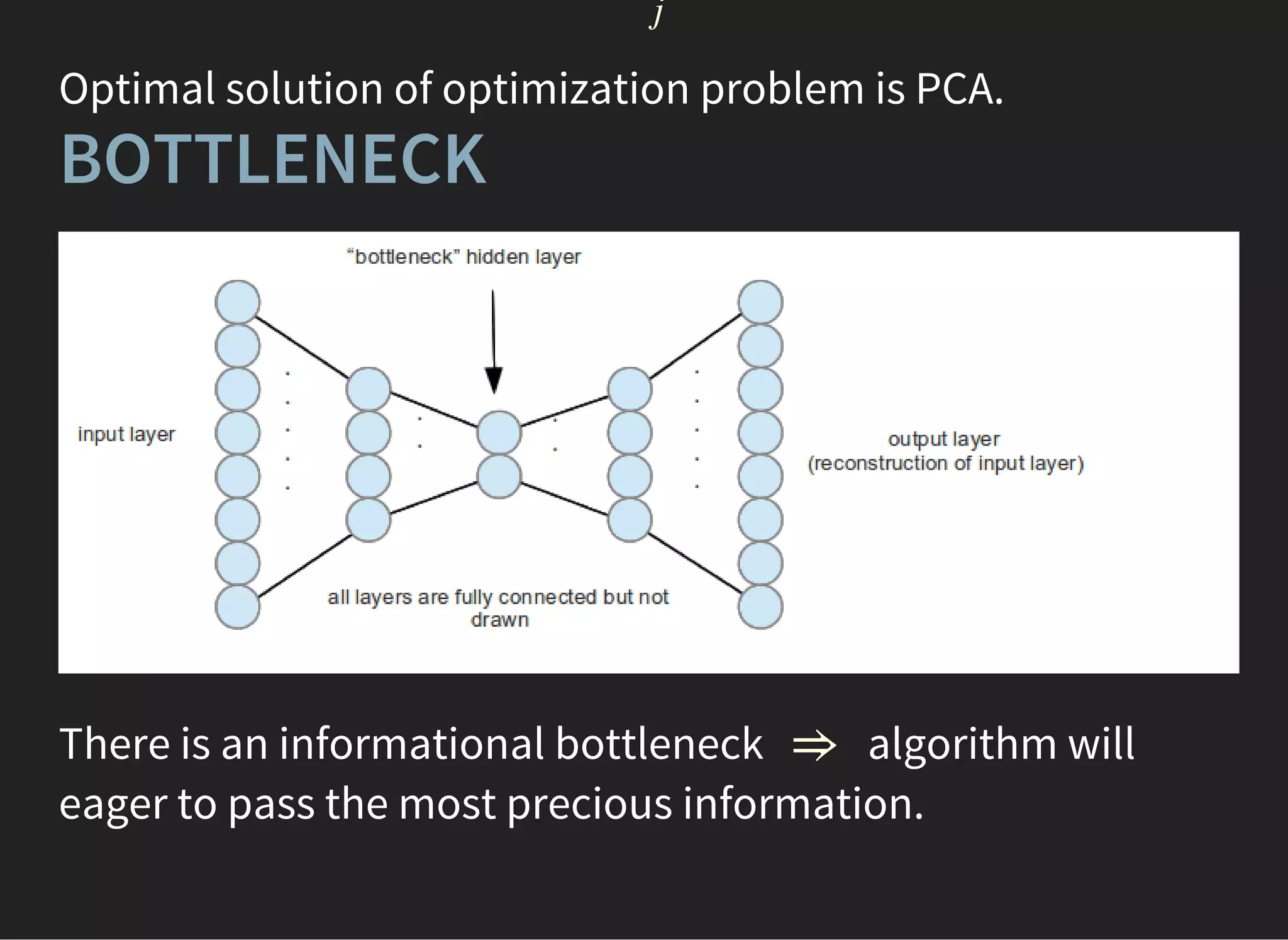
![UNSUPERVISED LEARNING: PCA
[PEARSON, 1901]
PCA is finding axes along which variation is maximal
(based on principal axis theorem)](https://image.slidesharecdn.com/lecture4-150907124759-lva1-app6891/75/MLHEP-2015-Introductory-Lecture-4-43-2048.jpg)

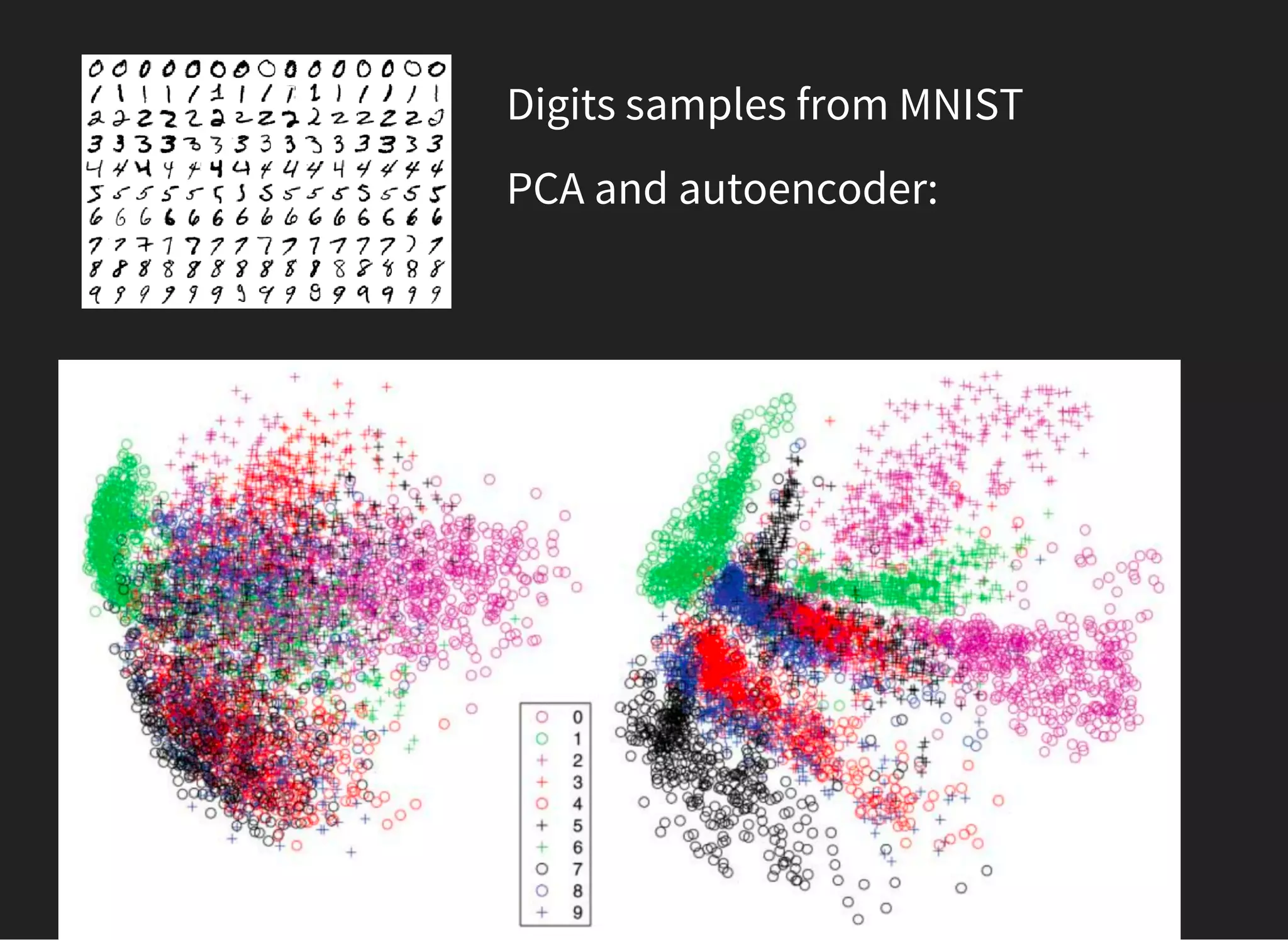
![PCA: EIGENFACES
Emotion = α[scared] + β[laughs] + γ[angry]+. . .](https://image.slidesharecdn.com/lecture4-150907124759-lva1-app6891/75/MLHEP-2015-Introductory-Lecture-4-45-2048.jpg)





































![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)





































