Download as PDF, PPTX
![[course site]
Day 3 Lecture 1
Backpropagation
Elisa Sayrol](https://image.slidesharecdn.com/dlai2017d3l1backpropagation-171017132337/85/Backpropagation-DLAI-D3L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-320.jpg)
![[course site]
Day 3 Lecture 1
Backpropagation
Elisa Sayrol](https://image.slidesharecdn.com/dlai2017d3l1backpropagation-171017132337/75/Backpropagation-DLAI-D3L1-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-2048.jpg)


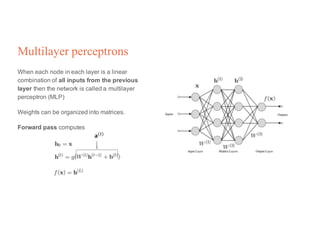


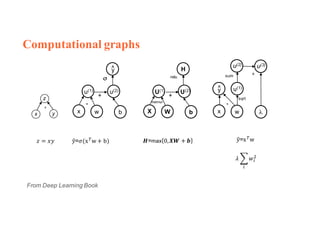
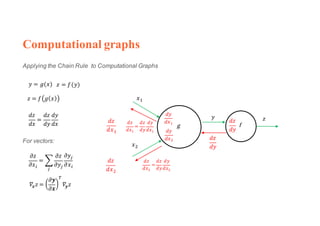
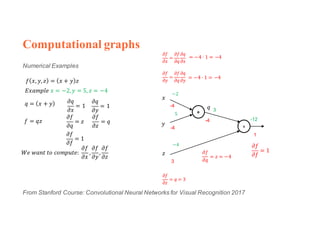
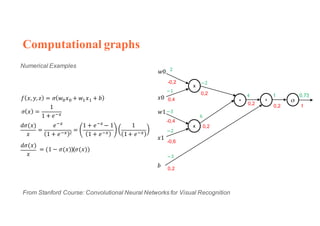
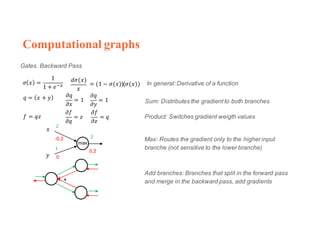


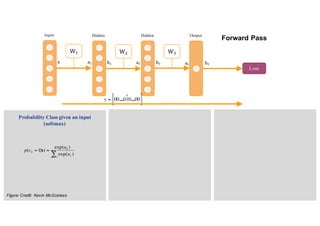
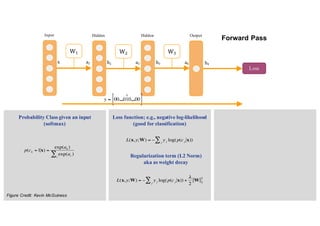
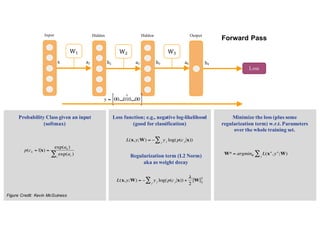
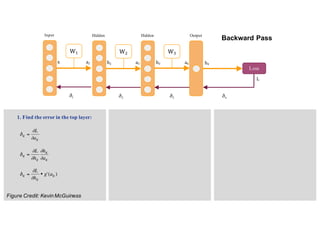
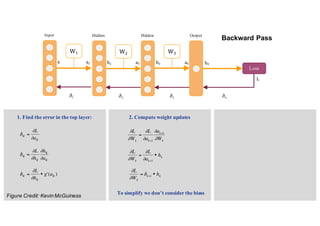
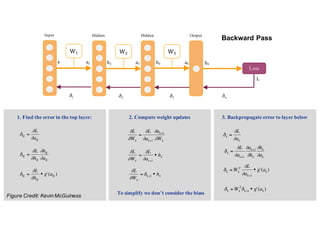

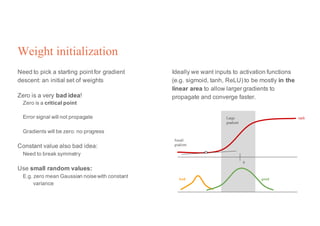
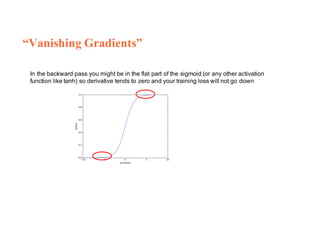


1. Backpropagation is an algorithm for training multilayer perceptrons by calculating the gradient of the loss function with respect to the network parameters in a layer-by-layer manner, from the final layer to the first layer. 2. The gradient is calculated using the chain rule of differentiation, with the gradient of each layer depending on the error from the next layer and the outputs from the previous layer. 3. Issues that can arise in backpropagation include vanishing gradients if the activation functions have near-zero derivatives, and proper initialization of weights is required to break symmetry and allow gradients to flow effectively through the network during training.








































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













