The document discusses tensor completion for partial differential equations (PDEs) with uncertain coefficients and Bayesian updates, emphasizing the importance of uncertainty quantification in simulations. It covers the stochastic forward problem, Bayesian updating methods, including Gaussian filters, and describes a tensor completion approach to handle these uncertainties efficiently. The document provides examples and techniques related to discretization, polynomial chaos expansions, and conditional expectations in the context of PDEs.




![4*
PDE with uncertain coefficient and RHS
Consider
− div(κ(x, ω) u(x, ω)) = f(x, ω) in G × Ω, G ⊂ R2,
u = 0 on ∂G,
(1)
where κ(x, ω) - uncertain diffusion coefficient. Since κ positive,
usually κ(x, ω) = eγ(x,ω).
For well-posedness see [Sarkis 09, Gittelson 10, H.J.Starkloff
11, Ullmann 10].
Further we will assume that covκ(x, y) is given.
Center for Uncertainty
Quantification
ation Logo Lock-up
4 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-5-320.jpg)
![4*
My previous work
After applying the stochastic Galerkin method, obtain:
Ku = f, where all ingredients are represented in a tensor format
Compute max{u}, var(u), level sets of u, sign(u)
[1] Efficient Analysis of High Dimensional Data in Tensor Formats,
Espig, Hackbusch, A.L., Matthies and Zander, 2012.
Research which ingredients influence on the tensor rank of K
[2] Efficient low-rank approximation of the stochastic Galerkin matrix in tensor formats,
W¨ahnert, Espig, Hackbusch, A.L., Matthies, 2013.
Approximate κ(x, ω), stochastic Galerkin operator K in Tensor
Train (TT) format, solve for u, postprocessing
[3] Polynomial Chaos Expansion of random coefficients and the solution of stochastic
partial differential equations in the Tensor Train format, Dolgov, Litvinenko, Khoromskij, Matthies, 2016.
Center for Uncertainty
Quantification
ation Logo Lock-up
5 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-6-320.jpg)

![4*
Canonical and Tucker tensor formats
[Pictures are taken from B. Khoromskij and A. Auer lecture course]
Storage: O(nd ) → O(dRn) and O(Rd + dRn).
Center for Uncertainty
Quantification
ation Logo Lock-up
7 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-8-320.jpg)
![4*
Definition of tensor of order d
Tensor of order d is a multidimensional array over a d-tuple
index set I = I1 × · · · × Id ,
A = [ai1...id
: iµ ∈ Iµ] ∈ RI
, Iµ = {1, ..., nµ}, µ = 1, .., d.
A is an element of the linear space
Vn =
d
µ=1
Vµ, Vµ = RIµ
equipped with the Euclidean scalar product ·, · : Vn × Vn → R,
defined as
A, B :=
(i1...id )∈I
ai1...id
bi1...id
, for A, B ∈ Vn.
Center for Uncertainty
Quantification
ation Logo Lock-up
8 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-9-320.jpg)








![4*
Numerical computation of NLBU
∂
∂ϕα
E
q2
(ξ) − 2
β∈J
qϕβΦβ(z) +
β,γ∈J
ϕβϕγΦβ(z)Φγ(z)
= 2E
−qΦα(z) +
β∈J
ϕβΦβ(z)Φα(z)
= 2
β∈J
E [Φβ(z)Φα(z)] ϕβ − E [qΦα(z)]
= 0 ∀α ∈ J .
Center for Uncertainty
Quantification
ation Logo Lock-up
17 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-19-320.jpg)
![4*
Numerical computation of NLBU
Now, rewriting the last sum in a matrix form, obtain the linear
system of equations (=: A) to compute coefficients ϕβ:
... ... ...
... E [Φα(z(ξ))Φβ(z(ξ))]
...
... ... ...
...
ϕβ
...
=
...
E [q(ξ)Φα(z(ξ))]
...
,
where α, β ∈ J , A is of size |J | × |J |.
Center for Uncertainty
Quantification
ation Logo Lock-up
18 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-20-320.jpg)
![4*
Numerical computation of NLBU
We can rewrite the system above in the compact form:
[Φ] [diag(...wi...)] [Φ]T
...
ϕβ
...
= [Φ]
w0q(ξ0)
...
wNq(ξN)
[Φ] ∈ RJα×N, [diag(...wi...)] ∈ RN×N, [Φ] ∈ RJα×N.
Solving this system, obtain vector of coefficients (...ϕβ...)T for
all β.
Finally, the assimilated parameter qa will be
qa = qf + ˜ϕ(ˆy) − ˜ϕ(z), (2)
z(ξ) = y(ξ) + ε(ω), ˜ϕ = β∈Jp
ϕβΦβ(z(ξ))
Center for Uncertainty
Quantification
ation Logo Lock-up
19 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-21-320.jpg)
![4*
Explanation of ” Bayesian Update surrogate” from E. Zander
Let the stochastic model of the measurement is given by
y = M(q) + ε, ε -measurement noise (3)
Best estimator ˜ϕ for q given z, i.e.
˜ϕ = argminϕ E[ q(·) − ϕ(z(·)) 2
2]. (4)
The best estimate (or predictor) of q given the
measurement model is
qM(ξ) = ˜ϕ(z(ξ))). (5)
The remainder, i.e. the difference between q and qM, is
given by
q⊥
M(ξ) = q(ξ) − qM(ξ), (6)
Due to the minimisation property of the MMSE
estimator—orthogonal to qM(ξ), i.e. cov(q⊥
M, qM) = 0.
Center for Uncertainty
Quantification
ation Logo Lock-up
20 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-22-320.jpg)

![4*
Example: 1D elliptic PDE with uncertain coeffs
− · (κ(x, ξ) u(x, ξ)) = f(x, ξ), x ∈ [0, 1]
+ Dirichlet random b.c. g(0, ξ) and g(1, ξ).
3 measurements: u(0.3) = 22, s.d. 0.2, x(0.5) = 28, s.d. 0.3,
x(0.8) = 18, s.d. 0.3.
κ(x, ξ): N = 100 dofs, M = 5, number of KLE terms 35, beta distribution for κ, Gaussian covκ, cov.
length 0.1, multi-variate Hermite polynomial of order pκ = 2;
RHS f(x, ξ): Mf = 5, number of KLE terms 40, beta distribution for κ, exponential covf , cov. length 0.03,
multi-variate Hermite polynomial of order pf = 2;
b.c. g(x, ξ): Mg = 2, number of KLE terms 2, normal distribution for g, Gaussian covg , cov. length 10,
multi-variate Hermite polynomial of order pg = 1;
pφ = 3 and pu = 3
Center for Uncertainty
Quantification
ation Logo Lock-up
22 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-24-320.jpg)
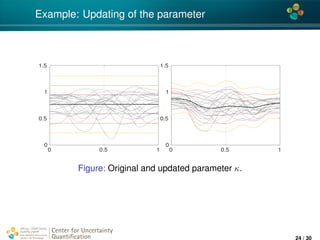
![4*
Example: updating of the solution u
0 0.5 1
-20
0
20
40
60
0 0.5 1
-20
0
20
40
60
Figure: Original and updated solutions, mean value plus/minus 1,2,3
standard deviations
[graphics are built in the stochastic Galerkin library sglib, written by E. Zander in TU Braunschweig]
Center for Uncertainty
Quantification
ation Logo Lock-up
23 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-25-320.jpg)



![4*
Numerical experiments for SPDEs: Tensor completion
[L. Grasedyck, M. Kluge, S. Kraemer, SIAM J. Sci. Comput., Vol 37/5, 2016]
Applied ALS and ADF methods to:
− div(κ(x, ω) u(x, ω)) = 1 in D × Ω,
u(x, ω) = 0 on ∂G × Ω,
(13)
D = [−1, 1]. The goal is to determine u(ω) := D u(x, ω)dx.
FE with 50 dofs, KLE with d terms, d-stochastic independent
RVs,
Yields to tensor Ai1...id
:= u(i1, ..., id ),
n = 100, d = 5, slice density CSD = 6.
Software (matlab) is available.
Center for Uncertainty
Quantification
ation Logo Lock-up
28 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-30-320.jpg)
![4*
Example: updating of the solution u
0 0.5 1
-20
0
20
40
60
0 0.5 1
-20
0
20
40
60
0 0.5 1
-20
0
20
40
60
0 0.5 1
-20
0
20
40
60
0 0.5 1
-20
0
20
40
60
Figure: Original and updated solutions, mean value plus/minus 1,2,3
standard deviations. Number of available measurements {0, 1, 2, 3, 5}
[graphics are built in the stochastic Galerkin library sglib, written by E. Zander in TU Braunschweig]
Center for Uncertainty
Quantification
ation Logo Lock-up
29 / 30](https://image.slidesharecdn.com/litvinenkosiamcse-170302223052/85/Tensor-Completion-for-PDEs-with-uncertain-coefficients-and-Bayesian-Update-techniques-31-320.jpg)












































































































