Recommended
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
PPTX
画像処理ライブラリ OpenCV で 出来ること・出来ないこと
PDF
計算機アーキテクチャを考慮した高能率画像処理プログラミング
PDF
PDF
PDF
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
PPTX
PDF
PDF
PDF
PDF
Visual SLAM: Why Bundle Adjust?の解説(第4回3D勉強会@関東)
PPTX
PDF
2015年度GPGPU実践プログラミング 第5回 GPUのメモリ階層
PDF
Anomaly detection 系の論文を一言でまとめた
PDF
PDF
PDF
数式を綺麗にプログラミングするコツ #spro2013
PPTX
PDF
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PPTX
PDF
PDF
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
PDF
PPTX
PDF
HalideでつくるDomain Specific Architectureの世界
PDF
機械学習とこれを支える並列計算 : 並列計算の現状と産業応用について
More Related Content
PDF
SSII2019TS: 実践カメラキャリブレーション ~カメラを用いた実世界計測の基礎と応用~
PDF
PPTX
画像処理ライブラリ OpenCV で 出来ること・出来ないこと
PDF
計算機アーキテクチャを考慮した高能率画像処理プログラミング
PDF
PDF
PDF
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
What's hot
PPTX
PDF
PDF
PDF
PDF
Visual SLAM: Why Bundle Adjust?の解説(第4回3D勉強会@関東)
PPTX
PDF
2015年度GPGPU実践プログラミング 第5回 GPUのメモリ階層
PDF
Anomaly detection 系の論文を一言でまとめた
PDF
PDF
PDF
数式を綺麗にプログラミングするコツ #spro2013
PPTX
PDF
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PPTX
PDF
PDF
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
PDF
PPTX
Similar to 画像処理の高性能計算
PDF
HalideでつくるDomain Specific Architectureの世界
PDF
機械学習とこれを支える並列計算 : 並列計算の現状と産業応用について
PDF
PDF
【関東GPGPU勉強会#4】GTX 1080でComputer Vision�アルゴリズムを色々動かしてみる
PPTX
PDF
Fpga online seminar by fixstars (1st)
PPTX
計算スケジューリングの効果~もし,Halideがなかったら?~
PDF
(文献紹介)エッジ保存フィルタ:Side Window Filter, Curvature Filter
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究
PDF
PDF
PPTX
PDF
Opencv object detection_takmin
PDF
PDF
CMSI計算科学技術特論B(14) OpenACC・CUDAによるGPUコンピューティング
PDF
PDF
PDF
PDF
PDF
More from Norishige Fukushima
PPTX
PPTX
PPTX
PPTX
PPTX
PPTX
Comparison between Blur Transfer and Blur Re-Generation in Depth Image Based ...
PPTX
Non-essentiality of Correlation between �Image and Depth Map in Free Viewpoin...
PDF
PDF
PDF
PDF
PDF
組み込み関数(intrinsic)によるSIMD入門
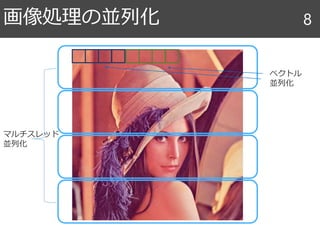
画像処理の高性能計算 1. 2. 3. 4. 5. 6. 7. コンシューマ向け最上位 Intel Core i9
9980XEは3.0 GHz,18コア,512ビットベク
トル演算器,FMAユニット2つ搭載
–単純:3.0 GFLOPS
–理想:3.5 TFLOPS (倍精度:1.8TFLOPS)
• 3.0*18*16*2*2
• ターボブーストや増加したL2キャッシュ,SMTを活
用するとさらに性能向上
FLOPS(Floating-point Operations Per Second)
–秒間浮動小数点演算を何回計算できるかの指標
計算機の並列性 7
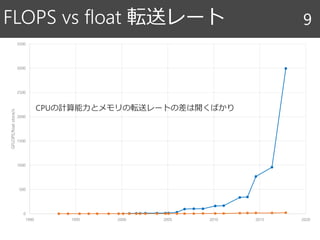
8. 9. FLOPS vs float 転送レート 9
0
500
1000
1500
2000
2500
3000
3500
1990 1995 2000 2005 2010 2015 2020
GFLOPS,float
store/s
CPUの計算能力とメモリの転送レートの差は開くばかり
10. 11. 12. 13. 画像同士の積和はほぼメモリコピーと同速
– ax+b
• 行列プログラミングで書くと
• Mat a,x,b;
• Add(Mul(a,x),b)
• 画素のスキャン2回.
• これくらいの計算だとメモリコピー2回と計算時間はほぼ一緒
– for
• ai*xi+bi
• スキャン一回で書けば,メモリコピー一回分くらいの計算時間
計算に必要な要素がそろった場合は,一回にループ
ですべて計算すると大きく高速化
– AddやMulの関数を最適化するだけでは,実現不可能
• AddMul関数を作るなどしなければだめ
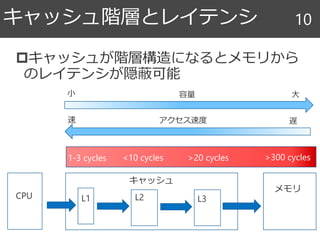
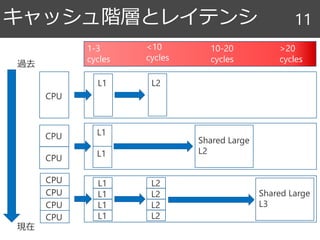
時間的局所性 13
14. 15. 16. タイリング 16
Tile-0
Imin: 149
Imax: 219
Full Image: Imin: 0, Imax: 255
Tile-1
Imin: 0
Imax: 210
Tile-15
Imin: 18
Imax: 243
Tile-2
Imin: 3
Imax: 233
Tile-3
Imin: 140
Imax: 177
r
マクロブロックとして小さなブロック画像を処
理することで空間的局所性の向上
問題点
「各ブロックで並列に計算する場合に冗長計算
が必要」
例えばフィルタリング:
畳み込み半径分ブロックの外側の情報も存在し
なければいけない
逐次計算なら問題ない
→順次計算していけばよい
ブロック境界が目立ってもよい処理なら簡単だ
が,ブロック境界を考えると冗長処理が必要
境界部分をオーバー
ラップして再計算
17. 18. 19. マルチプラットフォームに対応
– CPU
• X86, ARM, MIPS, Hexagon, Power-PC...
– GPU
• CUDA, OpenCL, OpenGL, Direct X 12...
– OS
• Linux, Windows, MacOS, Android, iOS...
ハードウェアによったチューニングが容易
– アルゴリズムを変えることなく,様々なハードウェアに依っ
てスケジュールだけを変更可能
– 深層学習の最適化バックエンドはHalideから構成(されてい
た)
Halide 19
20. void blur(const Image &in, Image &blurred)
{
Image tmp(in.width(), in.height());
for (int y = 0; y < in.height(); y++)
for (int x = 0; x < in.width(); x++)
tmp(x, y) = (in(x - 1, y) + in(x, y) + in(x + 1, y)) / 3;
for (int y = 0; y < in.height(); y++)
for (int x = 0; x < in.width(); x++)
blurred(x, y) = (tmp(x, y - 1) + tmp(x, y) + tmp(x, y + 1)) / 3;
}
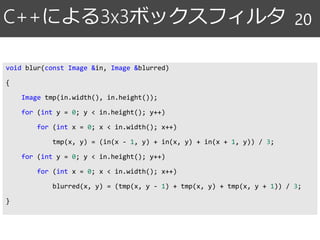
C++による3x3ボックスフィルタ 20
21. void fast_blur(const Image &in, Image &blurred)
{
m128i one_third = _mm_set1_epi16(21846);
#pragma omp parallel for
for (int yTile = 0; yTile < in.height(); yTile += 32)
{
m128i a, b, c, sum, avg;
m128i tmp[(256 / 8) * (32 + 2)];
for (int xTile = 0; xTile < in.width(); xTile += 256)
{
m128i *tmpPtr = tmp;
for (int y = -1; y < 32 + 1; y++)
{
const uint16_t *inPtr = &(in(xTile, yTile + y));
for (int x = 0; x < 256; x += 8)
{
a = _mm_loadu_si128((m128i *)(inPtr - 1));
b = _mm_loadu_si128((m128i *)(inPtr + 1));
c = _mm_load_si128((m128i *)(inPtr));
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(tmpPtr++, avg);
inPtr += 8;
}
}
tmpPtr = tmp;
for (int y = 0; y < 32; y++)
{
m128i *outPtr = (m128i *)(&(blurred(xTile, yTile + y)));
for (int x = 0; x < 256; x += 8)
{
a = _mm_load_si128(tmpPtr + (2 * 256) / 8);
b = _mm_load_si128(tmpPtr + 256 / 8);
c = _mm_load_si128(tmpPtr++);
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(outPtr++, avg);
}
}
}
}
}
Intel CPU向けに最適化 21
22. Func halide_blur(Func in)
{
Func tmp, blurred;
Var x, y, xi, yi;
// The algorithm
tmp(x, y) = (in(x - 1, y) + in(x, y) + in(x + 1, y)) / 3;
blurred(x, y) = (tmp(x, y - 1) + tmp(x, y) + tmp(x, y + 1)) / 3;
// The schedule
blurred.tile(x, y, xi, yi, 256, 32)
.vectorize(xi, 8)
.parallel(y);
tmp.compute_at(blurred, x).vectorize(x, 8);
return blurred;
}
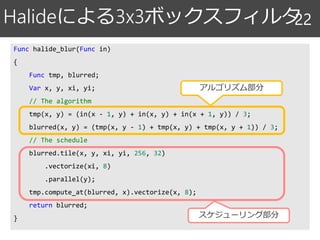
Halideによる3x3ボックスフィルタ
22
アルゴリズム部分
スケジューリング部分
23. 計算機
– CPU : Intel Core i7-8550U
– RAM : 8GB
– OS : Windows 10 Pro
入力画像
– 512x512 グレー画像
ガウシアンフィルタのパラメータ
– σ = 5
– カーネル半径 = 15
Halideの性能 23
24. Halide vs ナイーブな実装 vs 手作業で最適化 vs OepnCV
– Halide ... 0.406005 ms
– ナイーブ(naive) ... 58.4152 ms
– 手作業最適化(optimized) ... 1.40956 ms
– OpenCV ... 2.16409 ms
実験結果 24
0
10
20
30
40
50
60
70
Halide naive Optimize openCV
time
[ms]
25. Halide vs ナイーブな実装 vs 手作業で最適化 vs OepnCV
– Halide ... 0.406005 ms
– ナイーブ(naive) ... 58.4152 ms
– 手作業最適化(optimized) ... 1.40956 ms
– OpenCV ... 2.16409 ms
実験結果 25
0
10
20
30
40
50
60
70
Halide naive Optimize openCV
time
[ms]
144倍高速
3.5倍高速
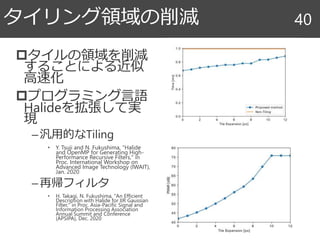
26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. タイルの領域を削減
することによる近似
高速化
プログラミング言語
Halideを拡張して実
現
–汎用的なTiling
• Y. Tsuji and N. Fukushima, "Halide
and OpenMP for Generating High-
Performance Recursive Filters," in
Proc. International Workshop on
Advanced Image Technology (IWAIT),
Jan. 2020
–再帰フィルタ
• H. Takagi, N. Fukushima, "An Efficient
Description with Halide for IIR Gaussian
Filter," in Proc. Asia-Pacific Signal and
Information Processing Association
Annual Summit and Conference
(APSIPA), Dec. 2020
タイリング領域の削減 40
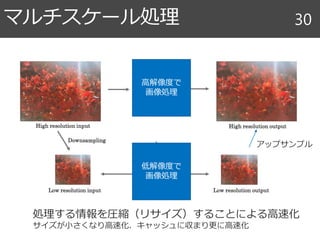
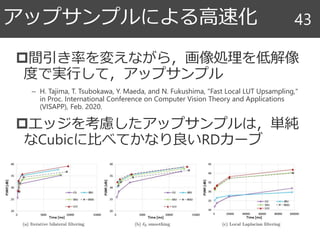
41. 42. 43. 間引き率を変えながら,画像処理を低解像
度で実行して,アップサンプル
– H. Tajima, T. Tsubokawa, Y. Maeda, and N. Fukushima, "Fast Local LUT Upsampling,"
in Proc. International Conference on Computer Vision Theory and Applications
(VISAPP), Feb. 2020.
エッジを考慮したアップサンプルは,単純
なCubicに比べてかなり良いRDカーブ
アップサンプルによる高速化 43
44. 45.











![ぼかして足して
の繰り返し
時間の局所性を
上げるように
コードを書きな
おすと...?
例えばSSIMの計算 14
Method Time [ms]
Naïve 21.01
Proposed 3.30 6.36 times faster
Widely used form](https://image.slidesharecdn.com/ie-210121032408/85/slide-14-320.jpg)





![void fast_blur(const Image &in, Image &blurred)
{
m128i one_third = _mm_set1_epi16(21846);
#pragma omp parallel for
for (int yTile = 0; yTile < in.height(); yTile += 32)
{
m128i a, b, c, sum, avg;
m128i tmp[(256 / 8) * (32 + 2)];
for (int xTile = 0; xTile < in.width(); xTile += 256)
{
m128i *tmpPtr = tmp;
for (int y = -1; y < 32 + 1; y++)
{
const uint16_t *inPtr = &(in(xTile, yTile + y));
for (int x = 0; x < 256; x += 8)
{
a = _mm_loadu_si128((m128i *)(inPtr - 1));
b = _mm_loadu_si128((m128i *)(inPtr + 1));
c = _mm_load_si128((m128i *)(inPtr));
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(tmpPtr++, avg);
inPtr += 8;
}
}
tmpPtr = tmp;
for (int y = 0; y < 32; y++)
{
m128i *outPtr = (m128i *)(&(blurred(xTile, yTile + y)));
for (int x = 0; x < 256; x += 8)
{
a = _mm_load_si128(tmpPtr + (2 * 256) / 8);
b = _mm_load_si128(tmpPtr + 256 / 8);
c = _mm_load_si128(tmpPtr++);
sum = _mm_add_epi16(_mm_add_epi16(a, b), c);
avg = _mm_mulhi_epi16(sum, one_third);
_mm_store_si128(outPtr++, avg);
}
}
}
}
}
Intel CPU向けに最適化 21](https://image.slidesharecdn.com/ie-210121032408/85/slide-21-320.jpg)

![Halide vs ナイーブな実装 vs 手作業で最適化 vs OepnCV
– Halide ... 0.406005 ms
– ナイーブ(naive) ... 58.4152 ms
– 手作業最適化(optimized) ... 1.40956 ms
– OpenCV ... 2.16409 ms
実験結果 24
0
10
20
30
40
50
60
70
Halide naive Optimize openCV
time
[ms]](https://image.slidesharecdn.com/ie-210121032408/85/slide-24-320.jpg)
![Halide vs ナイーブな実装 vs 手作業で最適化 vs OepnCV
– Halide ... 0.406005 ms
– ナイーブ(naive) ... 58.4152 ms
– 手作業最適化(optimized) ... 1.40956 ms
– OpenCV ... 2.16409 ms
実験結果 25
0
10
20
30
40
50
60
70
Halide naive Optimize openCV
time
[ms]
144倍高速
3.5倍高速](https://image.slidesharecdn.com/ie-210121032408/85/slide-25-320.jpg)





































![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)

































