Recommended
PPTX
20160713 srws第六回後半、revmanでのメタ・アナリシス・ハンズオン
PDF
PPT
PPTX
201707srws第六回その1メタ・アナリシスと存在、発生、効果の指標
PPTX
20160713 srws第六回@メタ・アナリシス前半
PPTX
20161222 srws第五回 Risk of Bias 2.0 toolを用いた文献評価
PDF
PPTX
6.1メタアナリシス revman practice
PDF
PPTX
PPTX
201707srws第六回その2メタアナリシス・異質性・出版バイアス
PPTX
PPTX
20170202 srws第七回統合、層別・感度分析、欠測への対処
PPTX
PPTX
PDF
PPTX
20170524 srws第三回pubmedを用いた系統的検索その1
PPTX
20160622 srws第五回risk of biasの評価
PPTX
20170608 srws第四回pubmed検索その2
PDF
PPTX
PDF
PPTX
PDF
PPTX
PPTX
PDF
PPT
PDF
PPTX
冬期セミナーWS19簡単にアクセスできる臨床研究リソース
More Related Content
PPTX
20160713 srws第六回後半、revmanでのメタ・アナリシス・ハンズオン
PDF
PPT
PPTX
201707srws第六回その1メタ・アナリシスと存在、発生、効果の指標
PPTX
20160713 srws第六回@メタ・アナリシス前半
PPTX
20161222 srws第五回 Risk of Bias 2.0 toolを用いた文献評価
PDF
PPTX
6.1メタアナリシス revman practice
What's hot
PDF
PPTX
PPTX
201707srws第六回その2メタアナリシス・異質性・出版バイアス
PPTX
PPTX
20170202 srws第七回統合、層別・感度分析、欠測への対処
PPTX
PPTX
PDF
PPTX
20170524 srws第三回pubmedを用いた系統的検索その1
PPTX
20160622 srws第五回risk of biasの評価
PPTX
20170608 srws第四回pubmed検索その2
PDF
PPTX
PDF
PPTX
PDF
PPTX
PPTX
PDF
PPT
Viewers also liked
PDF
PPTX
冬期セミナーWS19簡単にアクセスできる臨床研究リソース
PPTX
PPTX
20170212やっつけ仕事にしない「研究」ポートフォリオ 進行スライド1218
PPTX
20170305 srws robins i最終版
PPTX
20170223 srws第八回 sof、grade、prospero登録
PPTX
20170223 srws第八回 sof、grade、prospero登録
PPTX
20170202 srws第7回補講RoB2.0で決める知りたい効果とは?
PPTX
PPTX
20161106予測指標の作り方当日1031 配布版
DOCX
PPTX
Similar to 20170112 srws第六回メタ・アナリシス
PDF
PPTX
20161023 srws第五回補足新しいrob評価 紹介
PPTX
20160727 srws第七回@滋賀医大統合、層別・感度分析、欠測への対処
PDF
PPTX
201708 srws第七回統合、層別・感度分析、欠測への対処
PPTX
PPTX
20161023 srws第五回補足non rctのrob評価
PDF
PPTX
20161015 srws第一回preliminarysearching 公開用
PPTX
DOCX
PPTX
201708 srws第八回 sof、grade、prospero登録
PPTX
201708 srws第八回 grade、prospero登録、PRISMA
PPTX
201704 srws第一回preliminarysearching 一般公開
PPTX
PDF
PDF
PDF
PPTX
2016.9.24診断精度の系統的レビューワークショップ事前課題 "質の評価とアウトカム"
PDF
More from SR WS
PDF
PPTX
PPTX
20170120おおさかどまんなか原著論文 公開用
PPTX
PPTX
PPTX
201707srws第六回その3revmanでのメタ・アナリシス・ハンズオン
PPTX
PPTX
PPTX
20170610 AIと予測研究 slideshare
PPTX
PPTX
DOCX
冬期セミナーWS19臨床研究事前匿名化アンケートのまとめ
Recently uploaded
PDF
高等専門学校卒業資格における準学士学位 (Associate Degre) の制度的展望 —国際的学位制度との比較から—
PDF
プログラミング講座 【小学校高学年向け】Revision 6 2025/11/30
PPTX
Introduction to Japanese Language Learning.pptx
PDF
横浜国立大学3年生に向けて研究室を紹介する資料【2026年度研究室配属について】
PDF
横浜国立大学3年生に向けて研究室を紹介するスライド【2026年度研究室配属について】
PDF
ふみこんで学ぶ世界遺産700<第2版>世界遺産検定準1級公式テキスト(2026年発売)
20170112 srws第六回メタ・アナリシス 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 通常の研究で解析を行う方法©山崎新先生
25
アウトカム変数 2値 連続 生存時間
分布の記述 頻度集計
分割表
ヒストグラム
平均、SD
Kaplan-Meier法
単変量解析 カイ二乗検定
(または
フィッシャー検定)
リスク比の推定
T検定
F検定
平均値の差
Log-rank検定
率比の推定
多変量解析 ロジスティック
回帰分析
重回帰分析 Cox回帰分析
お経ですね
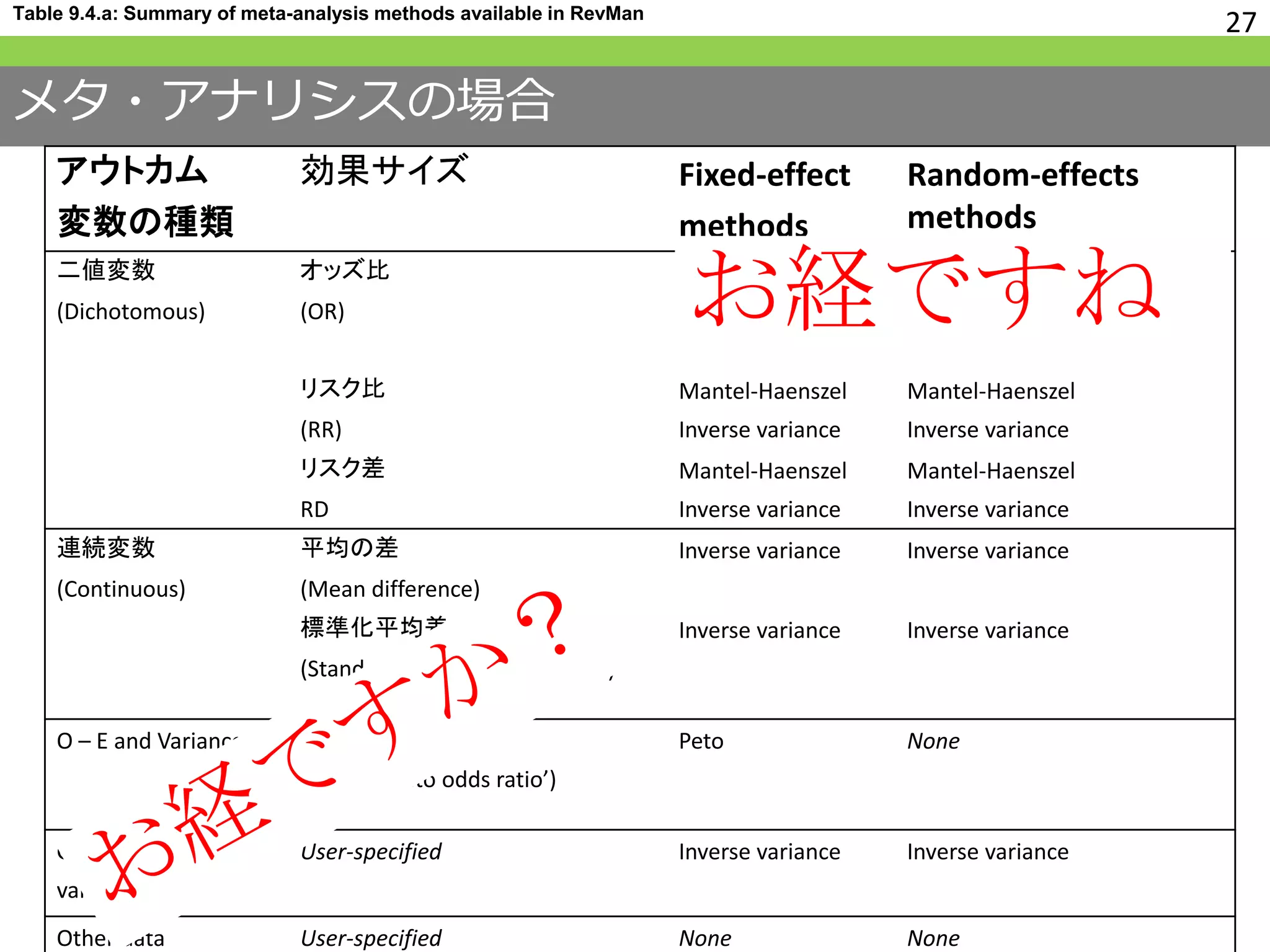
26. メタ・アナリシスの場合
• 個々の研究で使用されているアウトカム変
数の種類に慣れ親しむ
• 効果の比較を行うに適した測定方法を選ぶ
アウトカム変数の型
2値 連続 生存時間
分布の記述 頻度集計 ヒストグラム Kaplan-Meier
分割表 平均、SD
単変量解析 χ2検定 t検定、F検定 Log-rank検定
(リスク比) (平均値の差) (率比)
多変量解析 Logistic回帰 重回帰分析 Cox回帰
アウトカム
変数の種類
効果サイズ Fixed-effect
methods
Random-effects
methods
二値変数
(Dichotomous)
オッズ比
(OR)
Mantel-Haenszel
Inverse variance
Peto
Mantel-Haenszel
Inverse variance
リスク比
(RR)
Mantel-Haenszel
Inverse variance
Mantel-Haenszel
Inverse variance
リスク差
RD
Mantel-Haenszel
Inverse variance
Mantel-Haenszel
Inverse variance
連続変数
(Continuous)
平均の差
(Mean difference)
Inverse variance Inverse variance
標準化平均差
(Standardized mean difference)
Inverse variance Inverse variance
O – E and Variance User-specified
(default ‘Peto odds ratio’)
Peto None
Generic inverse
variance
User-specified Inverse variance Inverse variance
Other data User-specified None None
26Table 9.4.a: Summary of meta-analysis methods available in RevMan
27. メタ・アナリシスの場合
• 個々の研究で使用されているアウトカム変
数の種類に慣れ親しむ
• 効果の比較を行うに適した測定方法を選ぶ
アウトカム変数の型
2値 連続 生存時間
分布の記述 頻度集計 ヒストグラム Kaplan-Meier
分割表 平均、SD
単変量解析 χ2検定 t検定、F検定 Log-rank検定
(リスク比) (平均値の差) (率比)
多変量解析 Logistic回帰 重回帰分析 Cox回帰
アウトカム
変数の種類
効果サイズ Fixed-effect
methods
Random-effects
methods
二値変数
(Dichotomous)
オッズ比
(OR)
Mantel-Haenszel
Inverse variance
Peto
Mantel-Haenszel
Inverse variance
リスク比
(RR)
Mantel-Haenszel
Inverse variance
Mantel-Haenszel
Inverse variance
リスク差
RD
Mantel-Haenszel
Inverse variance
Mantel-Haenszel
Inverse variance
連続変数
(Continuous)
平均の差
(Mean difference)
Inverse variance Inverse variance
標準化平均差
(Standardized mean difference)
Inverse variance Inverse variance
O – E and Variance User-specified
(default ‘Peto odds ratio’)
Peto None
Generic inverse
variance
User-specified Inverse variance Inverse variance
Other data User-specified None None
27Table 9.4.a: Summary of meta-analysis methods available in RevMan
お経ですね
28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38. 39. 40. 41. 42. 43. 44. 統計学的異質性の検討法
フォレストプロット
Odds ratio and 95%CI
Value
0.050
0.352
1.000
0.214
0.557
0.029
0.5 1 2
Favours A Favours B
dy name Statistics for each study Odds ratio and 95%CI
Odds Lower Upper
ratio limit limit Z-Value p-Value
1.200 1.000 1.440 1.960 0.050
0.800 0.600 1.067 -1.520 0.128
1.500 1.100 2.045 2.562 0.010
0.700 0.600 0.817 -4.535 0.000
1.800 1.500 2.160 6.319 0.000
1.125 0.762 1.661 0.592 0.554
0.5 1 2
Favours A Favours B
Analysis
45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. References
• Systematic Reviews in Health Care,
Egger M, Smith GD, Altman DG
• Chapter 9 and 10, Cochrane
Handbook for Systematic Reviews of
Intervention, Higgins JP
• Applied Meta-Analysis with R, Chen
DG, Peace KE
65. 66. Editor's Notes #4 まず前回の復習です。みなさんがスコープ付きの銃でターゲットを狙いたいとします。
https://en.wikipedia.org/wiki/Telescopic_sight #5 2つの銃の写真がありますが、右の銃のようにスコープが曲がっていると、ターゲットを狙うのは難しいでしょう。それと同様に治療や介入の効果を正しく推定したいという状況でバイアスがある研究では推定が難しいです。前回はこのバイアスの程度をrisk of bias toolで評価していきました。
http://visualhunt.com/f/photo/3061519440/16124f8965/ #6 左のフローチャートががRCT実施の流れになります。
ランダム手順や、割付の隠蔽化というものは割付前に行います。
ブラインド化やマスク化といったいわゆる二重盲検化というものは割付後の話です。
そして、試験終了後のアウトカム評価では評価者の盲検化、アウトカムの欠測について評価します。
さらに、きちんと規定されたアウトカムや、重要なアウトカムが報告されているかを評価します。
#7 隠蔽化とマスク化についてはきちんと違いを説明できますでしょうか? #8 隠蔽化とマスク化についてはきちんと違いを説明できますでしょうか? #9 隠蔽化とマスク化についてはきちんと違いを説明できますでしょうか? #10 隠蔽化とマスク化についてはきちんと違いを説明できますでしょうか? #12 ワークフローをお示しします。いよいよ今回は組み入れた研究を統合するという過程に入っていきます
#14 今回の講義内容は少し難しいものになっております。課題については補講のスライドを見るだけで提出可能となっております。
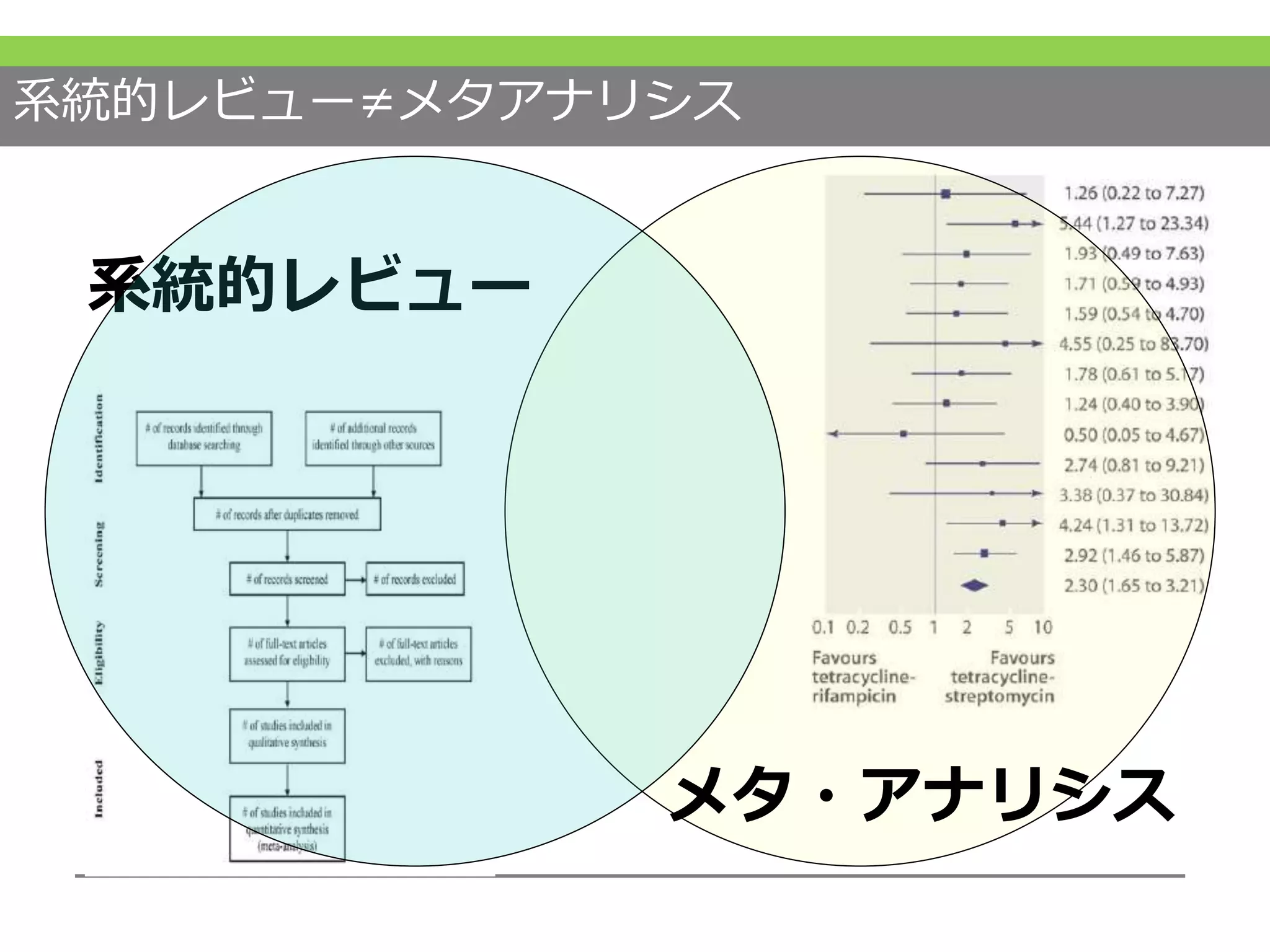
可能な限り簡単に説明はしておりますが、やや難易度が高くなってもいいよという方のみついてきていただければと思います。 #15 本講義の目標です #18 まず繰り返し述べていることだと思いますが、系統的レビューとメタアナリシスは別物だということを念頭においてください。
系統的レビューは科学的に事前に定められた方法で集められた文献をレビューすること
メタアナリシスはいくつかの研究の結果を統合することでした。
#19 メタアナリシスでは2つ以上の別の試験の結果を統計的に統合していきますが、何を統合しているのかという点も重要です。
例えば左側のようにりんごとオレンジのような違うものをただくっつけただけというのは、あまり良くないですし、何を見ているのかわからなくなります。
メタアナリシスの注意点としてはこのような違うものを混ぜ合わせて、良く分からない結果を出してしまうくらいならしない方がマシです
右側のようにうまく混ぜ合わせることができるものを統合することが重要です。
https://pixabay.com/ja/%E3%82%A2%E3%83%83%E3%83%97%E3%83%AB-%E3%82%AA%E3%83%AC%E3%83%B3%E3%82%B8-%E3%83%9F%E3%83%83%E3%82%AF%E3%82%B9-%E3%83%95%E3%83%AB%E3%83%BC%E3%83%84-%E9%A3%9F%E5%93%81-%E5%81%A5%E5%BA%B7-%E6%96%B0%E9%AE%AE%E3%81%AA-531163/
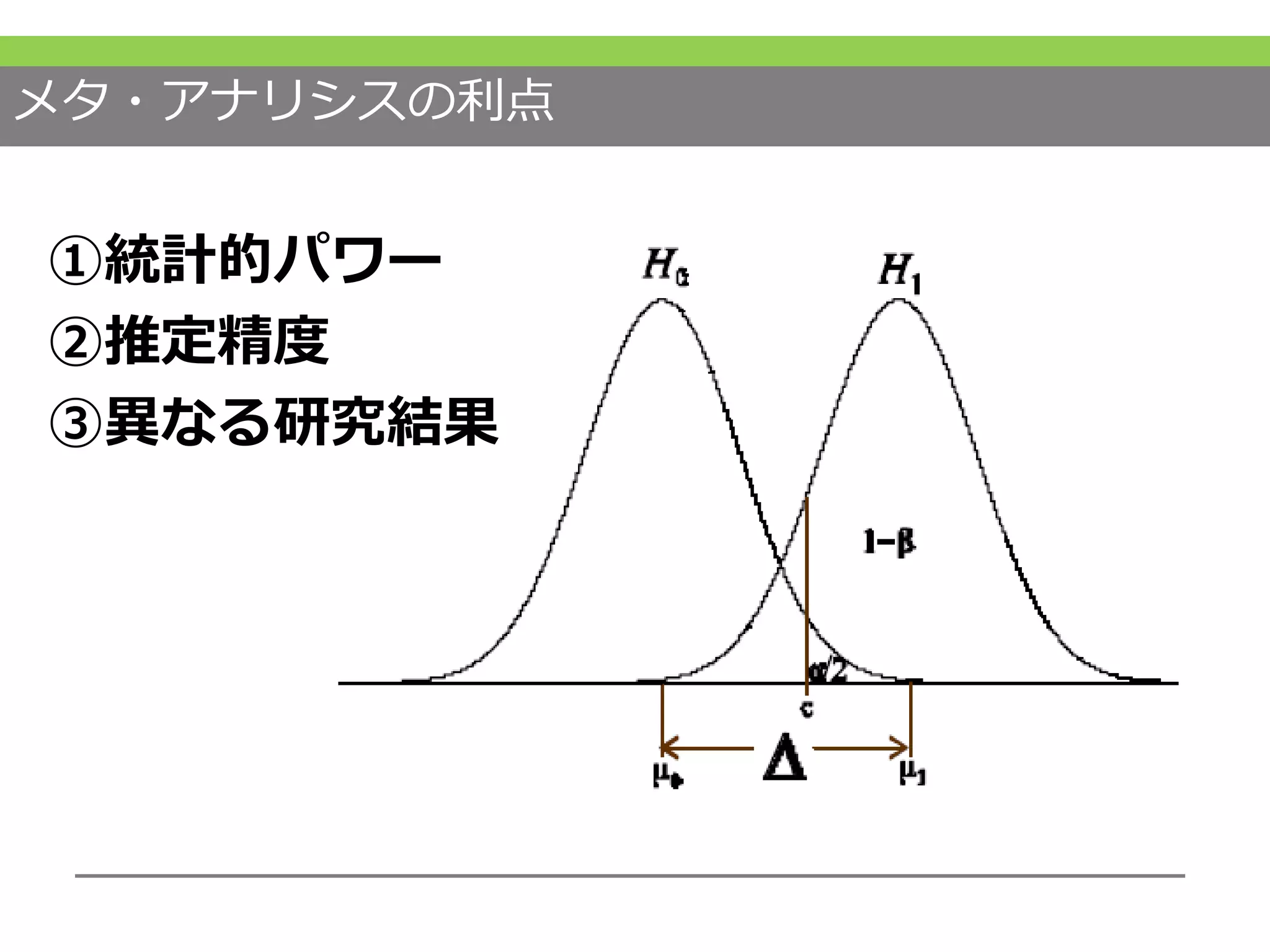
https://en.wikipedia.org/wiki/Drink_mixer #20 実際にメタアナリシスをした結果というのはこの図のように表されます。詳しい説明は後ほど行います。 #21 メタアナリシスの利点としては、1つの研究だけでは結論が出なかった研究も、同様の研究を集めることでより統計的パワーを持ち精度のよい推定が得られる可能性があります。
また、異なる研究結果の原因が一体なんなのかを探索的に考察することができます。 #22 メタアナリシスをする前にメタアナリシスのいくつかの種類についてご説明します。
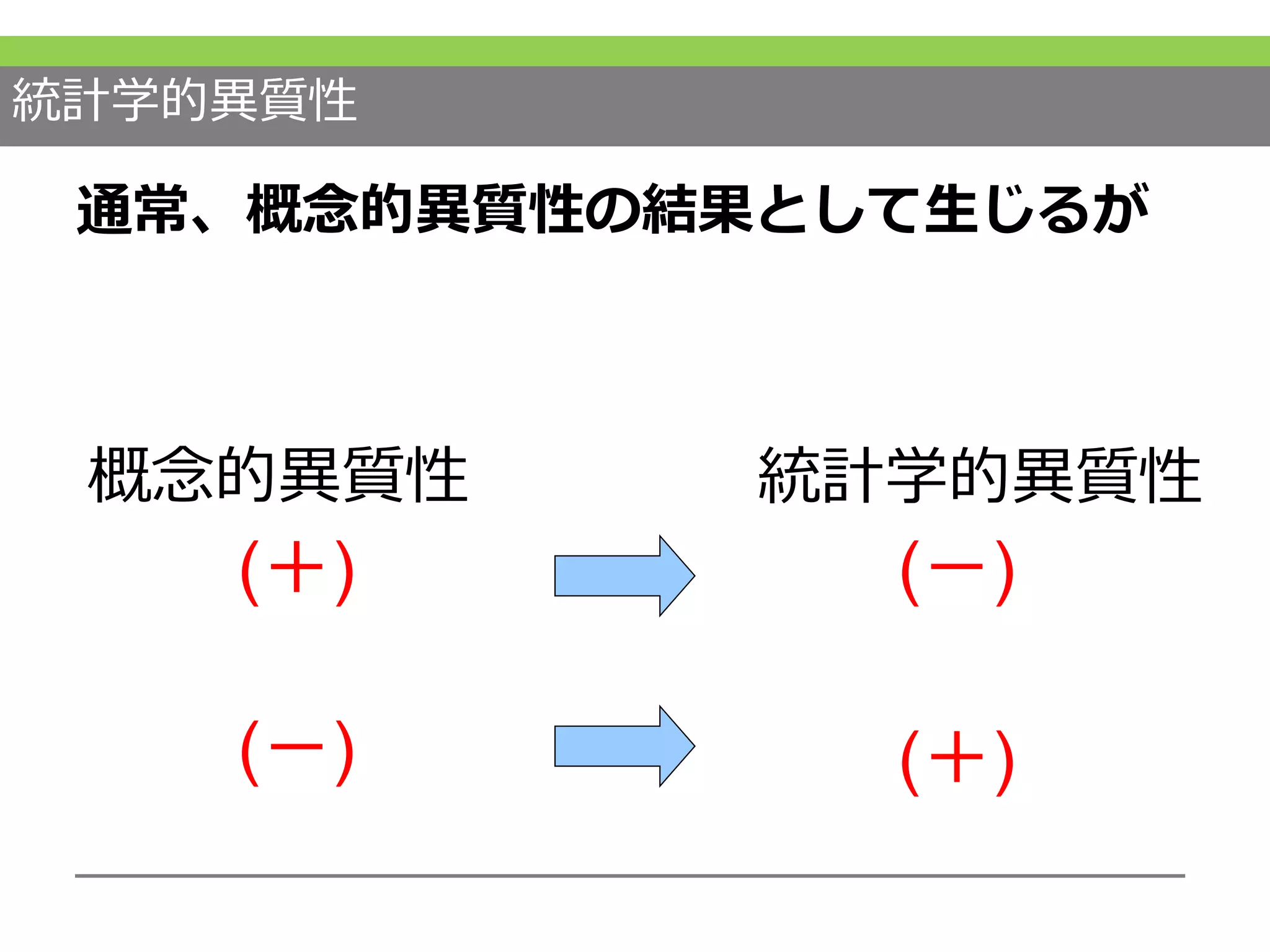
まずこの図のように、メタアナリシスには一つの比較をするものと、複数の比較をするものがあります。後者はネットワークメタアナリシスと呼ばれます。
今回は前者の一つの比較を取り上げます #23 次に、メタアナリシスで統合するものの基本単位が研究に含まれる個人なのか、それとも1つの研究が基本単位なのかでもメタアナリシスの手法は違ってきます。
前者はIPD(individual patient data)を用いたメタ・アナリシスと呼ばれます。
今回扱うのは後者です。
https://pixabay.com/ja/%E8%88%B9%E5%93%A1-%E7%B7%8F%E5%93%A1-%E6%B5%B7%E8%BB%8D-%E8%BB%8D%E4%BA%8B-%E4%BA%BA-%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97-%E7%94%B7%E6%80%A7-%E5%A5%B3%E6%80%A7-%E7%BE%A4%E8%A1%86-903044/
https://pixabay.com/ja/%E3%82%B1%E3%83%B3%E3%83%96%E3%83%AA%E3%83%83%E3%82%B8-%E5%BB%BA%E7%89%A9-%E6%A7%8B%E9%80%A0-%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%81%E3%83%A3-%E9%80%9A%E3%82%8A-%E4%BD%8F%E5%AE%85-66714/ #24 さて、ここからまた少し難しいパートに移ります。
個々の研究のアウトカムはどういうものなのか、ということを少し考えていきましょう。
研究のアウトカムは数字、つまり変数で表されます。その変数にもいくつかの種類があり、主なものとしてここに挙げた3つがあるかと思います。
2値変数 あり/なし になるもの。有害事象の有無、など。
連続変数 体重とか身長とか
生存期間という時間の長さと死亡や何らかのイベントといった2つの要素をもつ変数があります。 #25 そして効果量とは介入群とコントロール群のアウトカム変数の違い、つまり差や比といったものを指します。
2値変数ですと、、、 #26 なぜアウトカム変数の種類に分けて考えなければならないのかというと、それぞれの種類に応じて解析する方法が変わってくるということがあります。
今はまだ全ての意味を詳しく覚える必要はありませんが、ただ単にこの3x3表をお経として覚えていただければと思います。
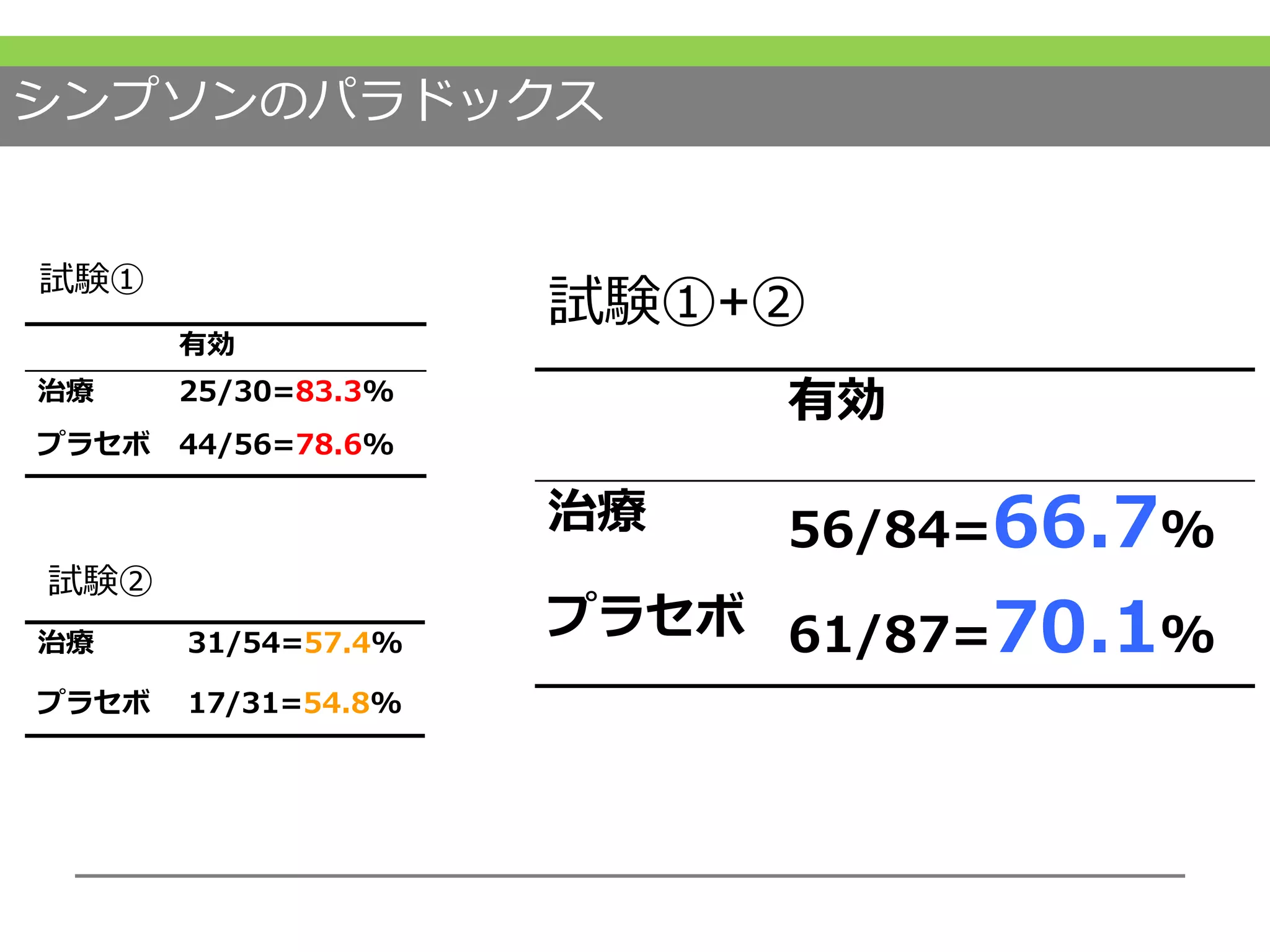
みなさんのリサーチクエスチョンのアウトカム変数が決まれば、それぞれ対応する記述方法や単変量解析の方法といったものは概ね決まってくるのだと思ってください。 #27 メタアナリシスでも全く一緒で、2値変数や連続変数といったアウトカム変数の種類が決まれば、その効果サイズが選べます。そしてその効果サイズによって使われる統計解析方法も表のように概ね決まってきます。 #28 ここもお経として覚えていただければと思います。 #29 例えば、みなさんのアウトカムが30日死亡割合であると、30日時点で生きているか死んでいるかの2値ですので、2値変数です。その効果サイズとしてはリスク比やオッズ比などがよく用いられます #30 繰り返しになりますが、難しいところまで覚える必要は今はまだありません。しかし、みなさんの研究のアウトカムが何なのか、どのアウトカム変数なのか、効果サイズは何で表現するか、ということは研究計画段階で決めておきましょう。 #31 続いて研究を統合するときに、単純に足し合わせてしまうと生じる数字のマジックを紹介します。
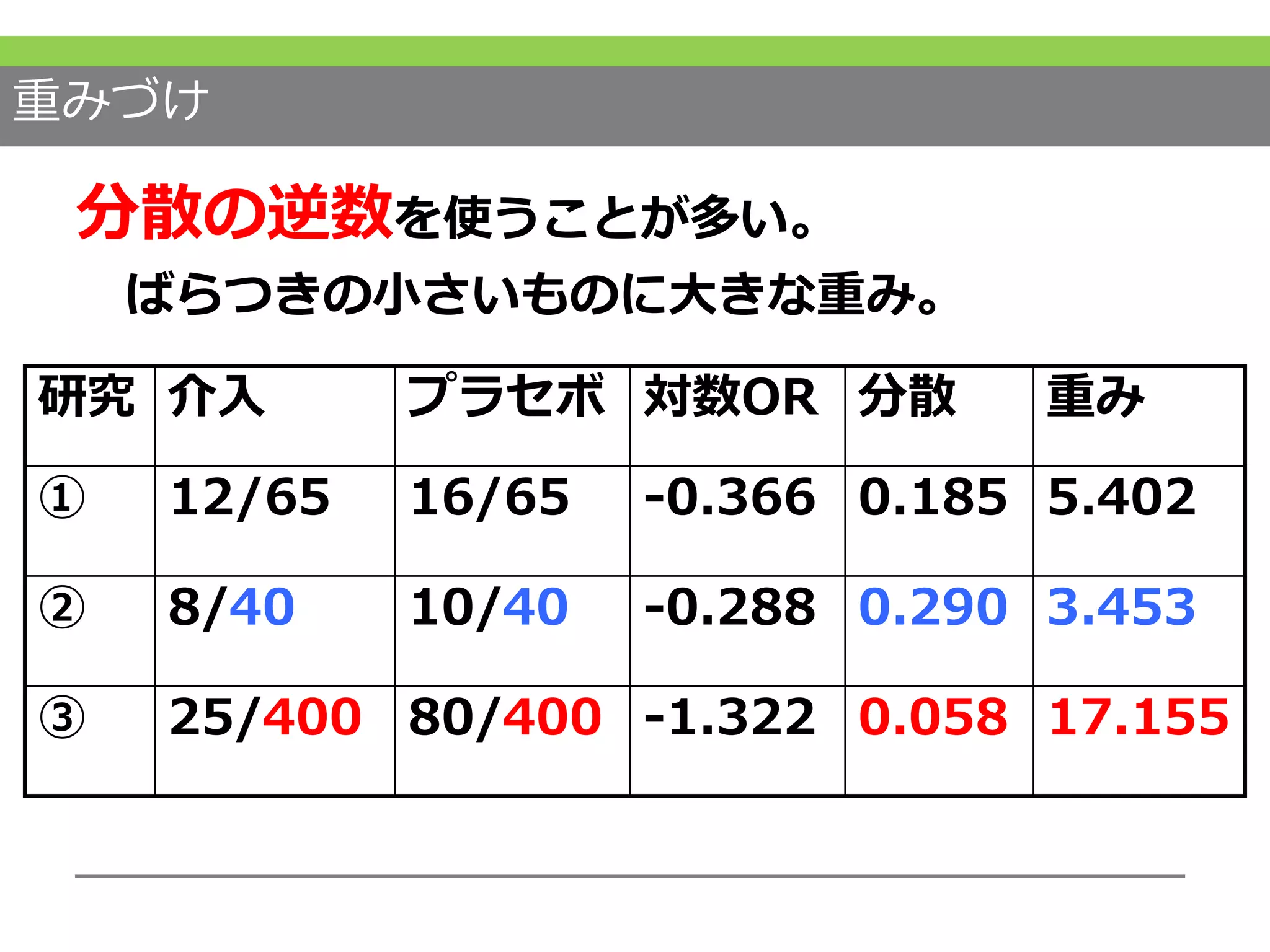
ここにお示しするような試験があるとします。分母が割付者数、分子がアウトカム発生数です。
どちらの試験も治療群の方が効果があったという報告でした。
しかし、両群の割付数とアウトカム発生数を単純に足すと #32 不思議なことにプラセボ群の方がアウトカム発生割合が多くなり、効果が高いということになってしまいます。
これをシンプソンのパラドックスといいます。 #33 なぜこのようなことが起こるのかというと、研究毎の推定精度、つまりこれはサンプルサイズ(N)に依存しますが、これを考慮にいれていないということがまず挙げられます。研究の精度に合わせ重み付けをする必要があったのですね。
そして、治療アームの数ではなく効果サイズで検討しないといけません。 #34 重み付けについては、分散の逆数を使うことが多いです。
分散が小さい、つまりサンプルサイズが大きく信頼区間が狭いような推定精度が高い研究により大きな重みがつくようになります。
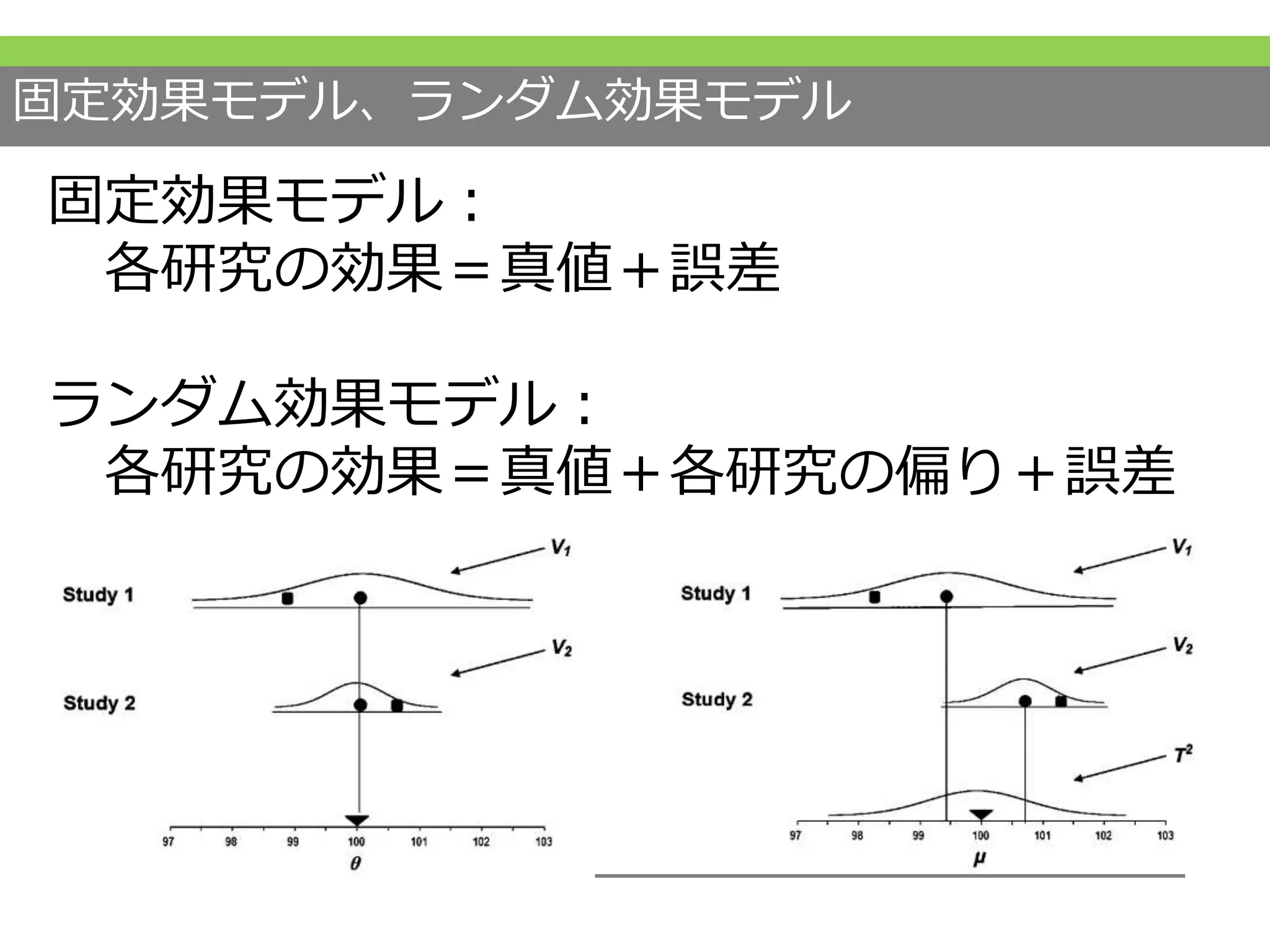
#35 また統合の際には、固定効果モデル(fixed effect model)というものと変量効果モデル(random effects model)というもののどちらかのモデルを当てはめて結果を統合することも頭に入れておいてください。
固定効果モデルでは各研究の効果は真の値と誤差で成り立っていると仮定します。
つまり、全ての研究の真の値は一緒で、効果量がずれているのは偶然のためであるとしています。
一方、ランダム効果モデルでは各研究で真の値はランダムにバラツキを持っていて、それにさらに誤差がついていると仮定しているモデルです。
集めてきた研究が全て条件的にも同じで、同じ真の値を見ているとするのは非常に強い仮定ですので、ランダム効果モデルが使われることが多いです。
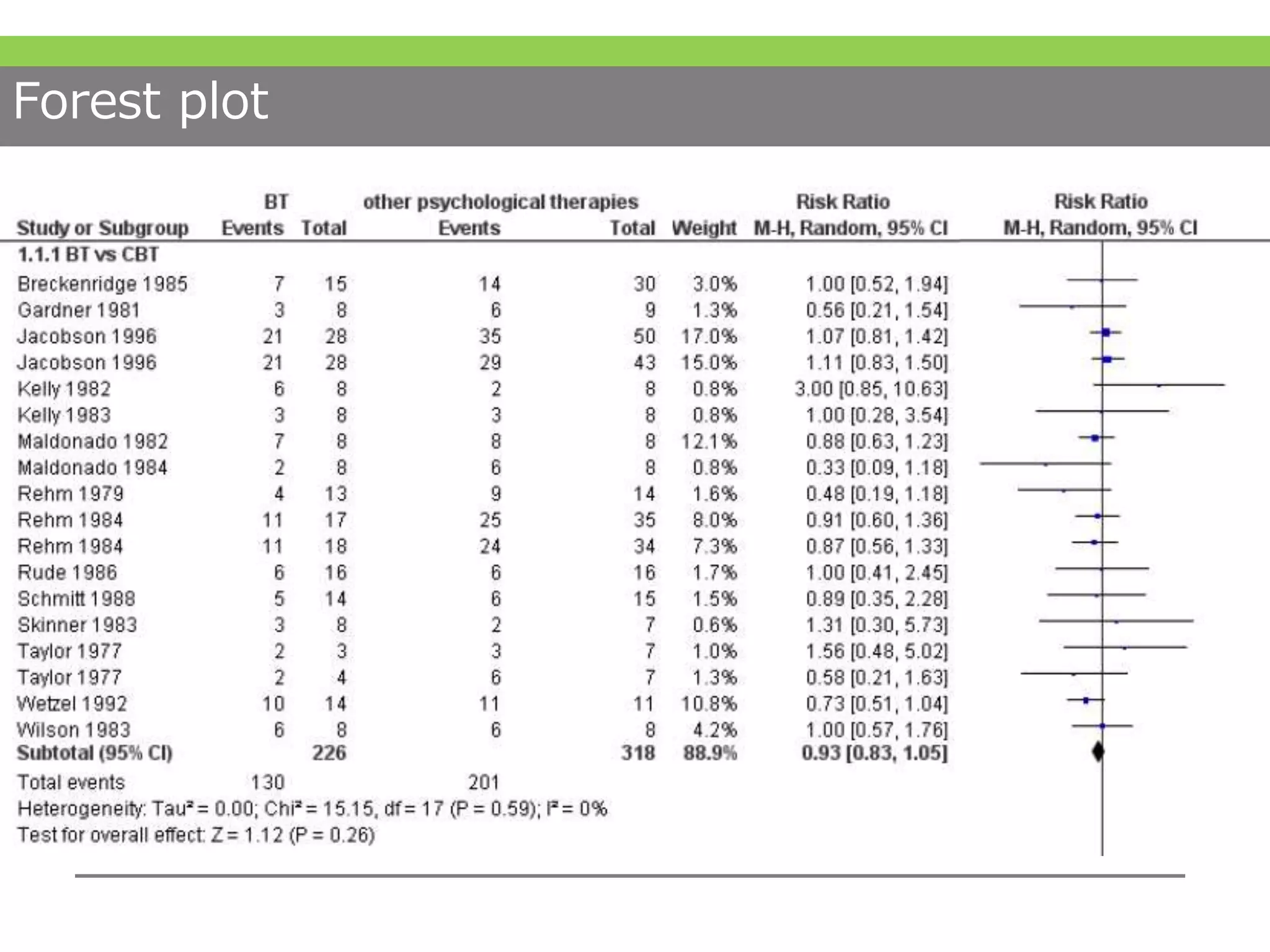
#36 目にした方も多いフォレストプロットです。今回は2値アウトカムのフォレストプロットですので、左からアウトカム数、トータルのn数、次にあるのがweightで各研究毎の重みになります。そして、効果量であるリスク比が記載され、randomとありますので、ランダム効果モデルで統合しているという意味です。
そしてその右側に点推定値が青い点、95%信頼区間が黒い線で表されています。この点推定値を示す青い点の大きさが重み、つまりサンプルサイズを反映しています。各研究を縦に見ていき最後にひし形で表されるのが、メタアナリシスした結果です。ひし形の中心が点推定値、横幅が95%信頼区間を表すと決まっています。 #37 さて、ここまでがメタアナリシスを行う過程でした。
少し難しかったと思いますが、後でRevManというソフトでやってみると案外簡単にできると感じることができると思います。
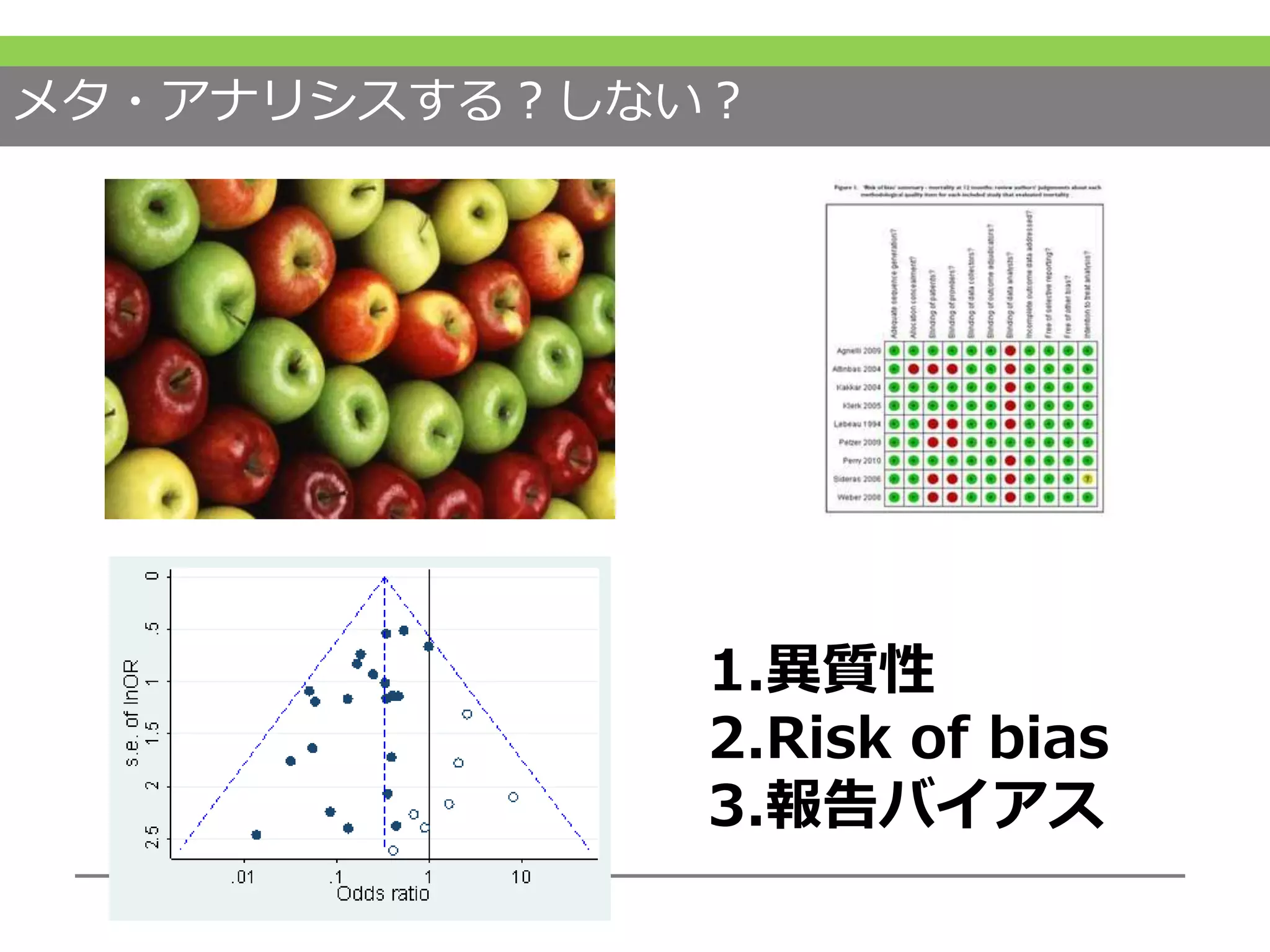
続きまして、異質性というものについて説明していきたいと思います。 #38 系統的レビューを行い、2つ以上の研究をレビューしたら、必ずメタアナリシスをしないといけないわけではありません。
メタアナリシスをするかしないかという判断については、その異質性、そして前回お話ししたRoBがあります。個々の研究でバイアスの程度がどのくらいかというものを加味する必要があります。さらにこの後お話しする報告バイアスというものを考慮して、結果を統合するかしないかということを決めていきます。混ぜていいかどうかということは結局のところ各研究が似ていると考えるか、似ていないと考えるかという価値判断に依存します。
https://en.wikipedia.org/wiki/Apples_and_oranges #39 さて、個々の研究の効果サイズが違うときに、それがなぜ起こっているのかという理由としては
1つめは単なる偶然ということが挙げられます。
もう1つの原因として、似ていると思ったものが実は似ておらず、全く違うものをみているという可能性があります。これが異質性と呼ばれるものです。 #40 異質性には大きく分けて2つの概念があります。1つは概念的異質性で、これは例えばりんごとみかんは同じものでしょうか?聞かれたときに、果物というカテゴリーでの研究の場合は同じという判断になります。しかし、柑橘類というカテゴリーで研究したいと考えている場合はそこにリンゴを入れることはマズいですね。この概念的異質性というものは、みなさんがどのようなカテゴリーで研究したいのか、というものを念頭におき、臨床的価値判断つまりclinical expertiseで判断するということになります。一方で統計学的異質性とはでてきた数字から判断する異質性です。どちらが重要かと言いますと、ここまでのお話からお分かりの通り、まずは概念的異質性を考えることが極めて重要です。 #41 これらの異質性をもう少し細かくみていきます。概念的異質性には臨床的異質性と方法論的異質性があります
臨床的異質性は例えばPやIといった患者背景、治療での異質性です。
方法論的異質性は研究のやり方自体による異質性のことを指し、risk of biasの違いなどよる異質性です。
もう1つは統計学的異質性です。これは概念的異質性の結果として
あるいは偶然の結果として異質性がどの程度か統計学的手法を用いて検討するものです。 #42 概念的異質性について重要なこととして、あらかじめprotocolで配慮が必要だということです。
明らかに異質性が高いものについては、別に統合する、一方だけ統合する、統合しないなどいった対応を事前に決めておくことが重要です。
例えば、ある薬を子供に投与した場合と大人に投与した場合は、おそらく異質性があると考えられますね
その場合は、子供の結果と大人の結果をそれぞれ別々に統合するといったようなことを、あらかじめ決めておきましょう。
#43 統計学的異質性は通常概念的異質性の結果として生じると考えられてはおりますが、概念的異質性があると判断されても統計学的異質性が計算結果としてないという結果になったり、その逆もあります。 #44 統計学的異質性の検討方法についてはここにあげたものがあります。 #45 まずフォレストプロットです。フォレストプロットは先ほどご説明したとおり、点推定値と、95%信頼区間をプロットしていった図になりますが、
この2つの図でどちらが異質性が高いとと思われますか?
当然、右の図の方が異質性が高いです。信頼区間の重なりが多いのか少ないのかといったところをvisualで判断します。 #47 次にQ統計量を用いて異質性を判断する方法がありますが
これは、、、、という注意点があります。 #48 検出力が1次研究数に依存するということはどういうことかというと、
検出力、つまり本当は異質性があるものをないと判断してしまう可能性がメタアナリシスに含まれる1次研究数に依存し、
研究数が少ないとそれだけで異質性なしと判断される恐れがあります。逆に研究数が多いと有意に異質性があると出やすくなります。
メタアナリシスでは通常そんなに多くの数の研究数を取り扱うことはないため、有意ととるカットオフを0.05ではなく、0.1にしているケースが多いです。 #49 また、異質性に対し、非定量的で、異質性があるとされても、一体どの程度の異質性があるかはわからないということに注意してください。
https://en.wikipedia.org/wiki/Emperor_penguin
https://pixabay.com/ja/%E3%83%9A%E3%83%B3%E3%82%AE%E3%83%B3-linux%E3%81%AE-%E3%83%9E%E3%82%B9%E3%82%B3%E3%83%83%E3%83%88-%E6%BC%AB%E7%94%BB%E3%81%AE%E3%82%AD%E3%83%A3%E3%83%A9%E3%82%AF%E3%82%BF%E3%83%BC-%E5%9B%B3-%E7%B7%91-8641/
#50 続いてI統計量、I2と呼ばれることが多いですが、これは定量的に異質性を判断することができ、どの程度異質性があるかを判断することができます。 #51 統計学的異質性が認められた場合、メタアナリシスすべきではありません。
また、年齢に異質性があるのではないか、投薬量に異質性があるのではないかなどと仮説を立てた上で、サブグループ解析といって別々のグループに分けて解析するといった方法で異質性の原因を探索することができます。
この辺りはややこしいので、またみなさんがプロトコルを完成させた時点で改めて我々と相談させていただければと思います。 #52 本日の最後の内容の出版バイアスについてお話します。 #53 報告バイアスとは、研究の報告が研究結果の方向性によって影響を受けるときに生じます。
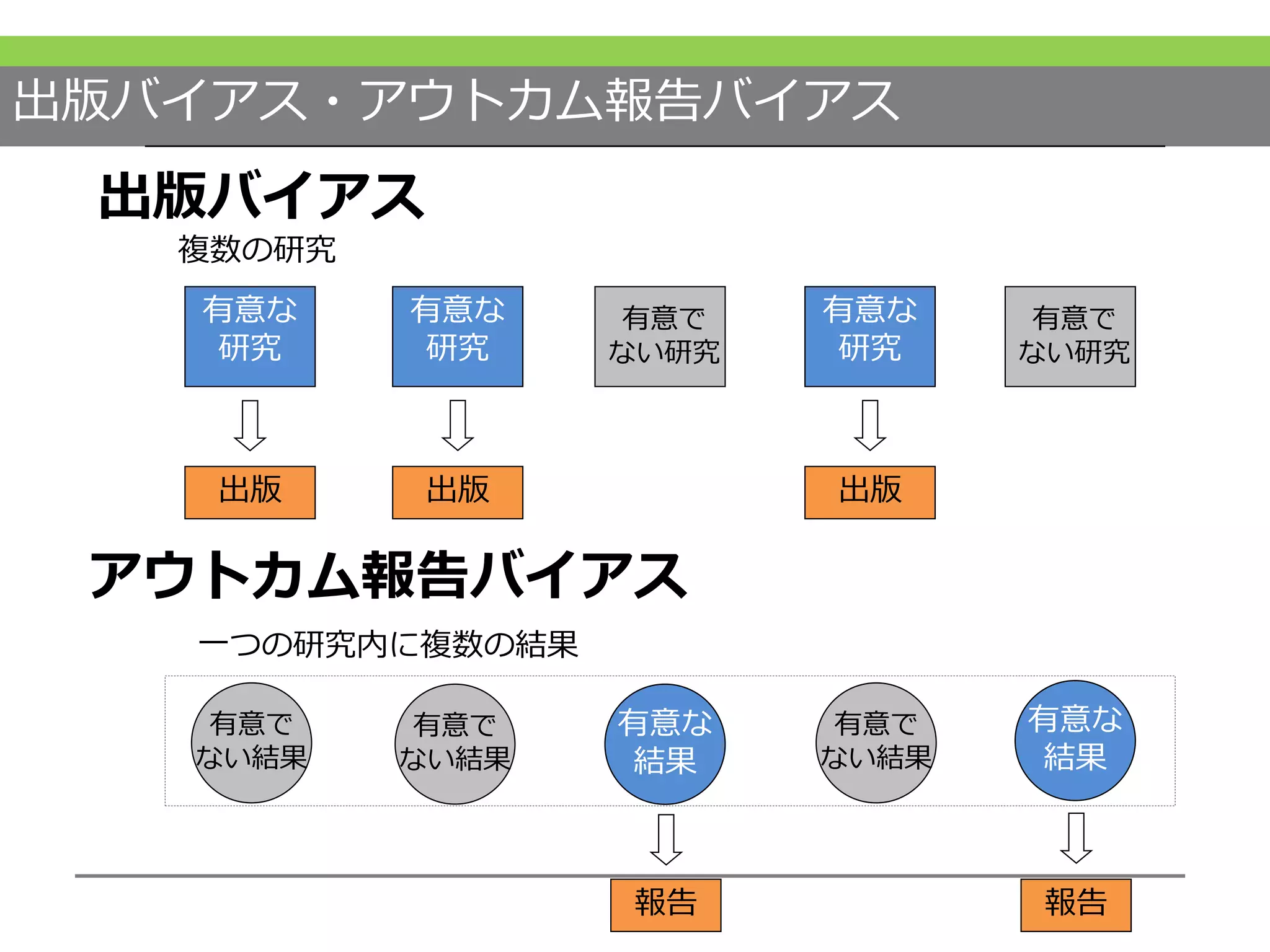
すでに分かっていることとして、統計学的に有意の結果が報告されやすいということが言われています。 #54 出版バイアスというのは、同じPICOをもつ研究が複数あったときに、結果が有意なものが選択的に出版されるということによるバイアスです。
アウトカム報告バイアスというものは1つの研究の中で、有意な結果が選択的に報告されることを指します。 #55 出版バイアスを起こりにくくする因子として、既存のエビデンスとしては… #56 また、ここに挙げた多くの領域で出版バイアスが報告されています。
#57 例えば、私が研修医だった2010年頃にTNF阻害薬はリウマチ分野を含め適応をとっていましたし、実際に使われていました。
しかし、実はその時点で、、、
これは非常に大きな問題です。検索して出てきた論文の結果だけで、結論を出すと判断を誤ることがあるということです。 #59 ではこの出版バイアスを検討するにはどうすればよいかというと、
1つはClinicalTrials.govやICTRPといった臨床試験の登録サイトでみなさんのリサーチクエスチョンを検索して、実際に臨床試験として登録はされているけれども出版されていない試験はないかを確認することになります。今は通常の雑誌であれば臨床試験として登録していないと、そもそも出版しないというルールが決まっていますので、通常臨床試験を行う前に登録サイトに登録がなされています。
もう1つはfunnel plotと呼ばれる方法で、みなさんが検索して出てきた結果をプロットし、偶然よりも大きな偏りをもって結果が報告されているかどうかを検討するというやり方です。
#60 Funnel plotでは通常横軸が効果量、縦軸が対数効果量の標準誤差を取ります。
実際に報告されているものだけをプロットすると右側になりますが、これは明らかにORが高い研究の報告がされていないということが予想されます。
そして、報告されていない結果を含めると左のように左右対称になります。
まずは目でみて、左右対称がないかを判断します。 #61 このfunnel plotを目で見るだけではなく、数字で検定したいという場合はこれらの方法があります。 #62 Funnel plotが非対称の理由としては、
小規模な研究で方法論、methodの質が低かった
異質性があった
偶然などが知られています。
#63 他にもやり方の変えたfunnel plotを出すといったやり方がされることもあります。
これについてはまた実際にやるときにご相談させていただければと思います。 #66 今日のお話の復習です。
まず、メタアナリシスとは複数の研究の結果を統合することでした。
フォレストプロットとは効果量とその95%信頼区間、そしてそのサンプルサイズが示されたプロットでした。
異質性はりんごとみかんを一緒にするのか、それとも別にするのかということを事前に決めておくということ。
出版バイアスとは、よかった結果だけを報告するというバイアスのことで、それを検証する方法としては、臨床試験登録サイトを検索することや、funnel plotを書いてその非対称性を検討することが挙げられました。 #69 リファレンスです。 #70 そして元スライドをご提供いただいた神戸大学の大西先生へ感謝申し上げます。