Stanコードへ
data{
int ld; //length of data
int nt; // number of treatment
int ns; // number of study
int study[ld]; // vector of the study id
int treatment[ld]; //vector of the treatment id
int dead[ld]; // vector of the number of dead
int sampleSize[ld]; // vector of the number of patient
}
parameters{
real d01;
real mu[ns];
}
r[ , ]やn[ , ]などの行列形式は,ネッ
トワークメタ分析に拡張した時に,
やや面倒になるので,今回は,各変
数を1列のベクターにしている
(long形式にしたものの各列を読み
込む感じです)
推定するパラメータは,mu(各研究におけ
るベースライン=各研究での治療0の効果)
とd01(治療0と治療1の差=治療0を基準と
したときの治療1の相対効果)
16
Stanコードへ
data{
int ld; //length of data
int nct; // number of compared treatment
int ns; // number of study
int study[ld]; // vector of the study id
int treatment[ld]; // vector of the treatment id
int dead[ld]; // vector of the number of dead
int sampleSize[ld]; // vector of the number of patient
int baseline[ld]; // vector of baseline treatment each study
}
parameters{
real d[nct];
real mu[ns];
}
各変数を1列のベクターにしている
(long形式にしたものの各列を読み
込む感じ)
なお,treatmentでリファレンス治療
SKは,0とコードした
推定するパラメータは,
mu(各研究におけるベースラインの効果)と
d[nct](リファレンスに対する6つの治療の
相対効果) 25






![メタ分析の前に・・・効果量
<質的変数>
①リスク差 = 介入群の比率 - 統制群の比率
②NNT(Number needed to treat) = 1/|リスク差|
③リスク比 = 介入群の比率/統制群の比率
④オッズ比 = [介入群の比率/(1-介入群の比率)]/[統
制群の比率/(1-統制群の比率)]
<量的変数>
①平均値差=介入群の平均値-統制群の平均値
②標準化平均値差=(介入群の平均値-統制群の平
均値)/プールされた標準偏差
7](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-7-320.jpg)



![使用データ(一対比較用)
● 血栓溶解治療のデータ(Caldwell et la., 2005)のうち,
ACC t-PA(治療0,controlにする)とPTCA(治療1)を比較
した11の試験。
r[,1] n[,1] r[,2] n[,2] #Study year
3 55 1 55 #Ribichini 1996
10 94 3 95 #Garcia 1997
40 573 32 565 #GUSTO-2 1997
5 75 5 75 #Vermeer 1999
5 69 3 71 #Schomig 2000
『Network Meta-Analysis for Decision-Making』のデータ
r = 死者数
n = 試験の参加患者数
# Study = 研究者名
year =研究発表年
※ベースになる治療は
0とコード化
11](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-11-320.jpg)




![Stanコードへ
data{
int ld; // length of data
int nt; // number of treatment
int ns; // number of study
int study[ld]; // vector of the study id
int treatment[ld]; //vector of the treatment id
int dead[ld]; // vector of the number of dead
int sampleSize[ld]; // vector of the number of patient
}
parameters{
real d01;
real mu[ns];
}
r[ , ]やn[ , ]などの行列形式は,ネッ
トワークメタ分析に拡張した時に,
やや面倒になるので,今回は,各変
数を1列のベクターにしている
(long形式にしたものの各列を読み
込む感じです)
推定するパラメータは,mu(各研究におけ
るベースライン=各研究での治療0の効果)
とd01(治療0と治療1の差=治療0を基準と
したときの治療1の相対効果)
16](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-16-320.jpg)
![Stanコードへ
model{
for(i in 1:ld){
if(treatment[i]==0){
dead[i] ~ binomial_logit(sampleSize[i],mu[study[i]]);
}else{
dead[i] ~ binomial_logit(sampleSize[i],mu[study[i]]+d01);
}
}
# prior
d01~normal(0,10000);
mu~normal(0,10000);
}
死者数が,binomial_logit(試験の参加人数,
死亡確率を構成する式)から生成
・治療0は,その試験のmuのみ
・治療1は,その試験のmu + d01
d12とmuの事前分布としては,幅のひろー
い正規分布
スライドからは割愛したが,modelブロッ
クの下のgenerated quantities(生成量)ブ
ロックでは,d01からオッズ比(exp(d01)
で計算)や有害の確率,モデル比較用の対
数尤度を計算
17](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-17-320.jpg)
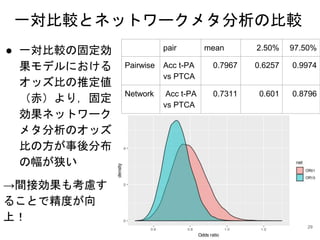
![推定結果
Mean SD 2.5% 97.5%
d01 -0.2332 0.1182 -0.4668 -0.0019
オッズ比 0.7975 0.0946 0.6270 0.9981
有害となる確率 0.0243 0.1540 0.0000 0.0000
推定は収束し,
教科書とほぼ一致
死亡に関して,ACC t-PAを基
準にした時のPTCAのオッズ
比は0.798[0.627 0.998]
→PTCAの方が死亡率が低い
18](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-18-320.jpg)




![使用データ(ネットワークメタ分析用)
● 7つの治療薬について検討した36試験からなる血栓溶
解薬のデータ(Caldwell et la., 2005)
● na[ ]はアーム数,t[ ]は治療ID,r[ ]は死者数,n[ ]は試験
の参加患者数,# Study = 研究者名,year =研究発表年
→Stanだとちょっとこの行列の扱い(というか欠測値)の扱
いがやりにくいので,各変数を列にしたlong型へ
na[] t[,1] t[,2] t[,3] r[,1] n[,1] r[,2] n[,2] r[,3] n[,3] #study year
3 1 3 4 1472 20251 652 10396 723 10374 #GUST
O-1
1993
2 1 2 NA 3 65 3 64 NA NA #ECSG 1985
2 1 2 NA 12 159 7 157 NA NA #TIMI-1 1987
2 1 2 NA 7 85 4 86 NA NA #PAIM
S
1989
『Network Meta-Analysis for Decision-Making』のデータ
23](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-23-320.jpg)
![推定のイメージ
1. リファレンス(SK)のベースライ
ンに対する相対効果dは0に設定
2. リファレンスと直接比較してい
る試験を使って,それらのdを
推定する
3. リファレンスとの直接比較の推
定値を使って,リファレンスが
含まれない試験についても,直
接比較の推定値を活用して推定
する
※一貫性の検討をする場合のため
にもデータの順番は意識する
ベースライン 比較 推定方法
SK PTCA 直接 d[6]
SK t-PA 直接 d[1]
SK Acc t-PA 直接 d[2]
...
t-PA PTCA 間接 d[2]-d[4]
Acc t-PA TNK 間接 d[5]-d[2]
24](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-24-320.jpg)
![Stanコードへ
data{
int ld; // length of data
int nct; // number of compared treatment
int ns; // number of study
int study[ld]; // vector of the study id
int treatment[ld]; // vector of the treatment id
int dead[ld]; // vector of the number of dead
int sampleSize[ld]; // vector of the number of patient
int baseline[ld]; // vector of baseline treatment each study
}
parameters{
real d[nct];
real mu[ns];
}
各変数を1列のベクターにしている
(long形式にしたものの各列を読み
込む感じ)
なお,treatmentでリファレンス治療
SKは,0とコードした
推定するパラメータは,
mu(各研究におけるベースラインの効果)と
d[nct](リファレンスに対する6つの治療の
相対効果) 25](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-25-320.jpg)
![model{
for(i in 1:ld){
if(baseline[i]==0){
if(treatment[i]==0){
dead[i] ~ binomial_logit(sampleSize[i],mu[study[i]]);
}else{
dead[i] ~ binomial_logit(sampleSize[i],mu[study[i]]+d[treatment[i]]);
}
}else{
if(baseline[i]==treatment[i]){
dead[i] ~ binomial_logit(sampleSize[i],mu[study[i]]);
}else{
dead[i] ~ binomial_logit(sampleSize[i],mu[study[i]]+d[treatment[i]]-d[baseline[i]]);
}
}
}
# prior
d~normal(0,10000);
mu~normal(0,10000);
}
リファレンス(SK)との比較の場合:
・リファレンス治療の死亡率は,各試験のmuから生成
・それ以外の治療の死亡率は,mu(リファレンスの効果)
+ d(各研究の相対効果)から生成
試験のベースラインがリファレンス(SK)以外の場合:
・試験のベースラインの死亡率は,muから生成
・他の治療の死亡率は,mu(各試験のベースラインの効
果) + d(各治療のリファレンスに対する相対効果) - d(リフ
ァレンスに対するベースライン治療の相対効果)から生成
例) TNKの相対効果のd(Acc t-PA→TNK)は,d(SK→TNK)
からd(SK→Acc t-PA)を引いたもの 26](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-26-320.jpg)
![推定結果
● 推定は収束し,教科書と同様の結果になった。
● リファレンス(SK)に対する,各治療の相対効果(d)
をみると,SKとは直接比較していない,TNKの効
果(d[5])も推定されている!
mean se_mea
n
sd 2.50% 97.50% n_eff Rhat
d[1] -0.0032 0.0002 0.0304 -0.0627 0.0562 23842 0.9998
d[2] -0.1567 0.0003 0.0434 -0.2418 -0.0729 21865 1.0001
d[3] -0.043 0.0003 0.0465 -0.1334 0.0465 28616 1
d[4] -0.1106 0.0004 0.0601 -0.2289 0.0053 23642 1
d[5] -0.1517 0.0005 0.0763 -0.3028 -0.0022 22117 1
d[6] -0.4746 0.0006 0.0998 -0.672 -0.2797 23850 0.9999
27](https://image.slidesharecdn.com/networkmetaanalysis-181215135645/85/slide-27-320.jpg)