Download as PDF, PPTX










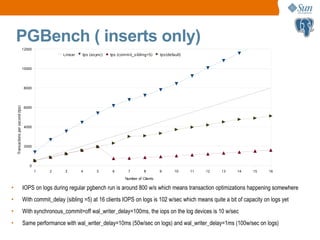
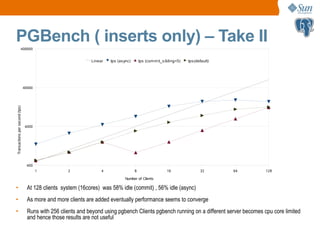
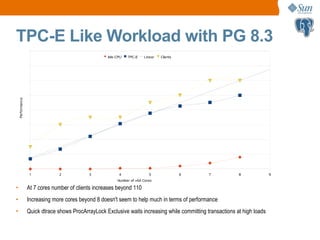

![IGEN with PostgreSQL on T2000
32 64 128 256 512 1024 1280 1536
0
20000
40000
60000
80000
100000
120000
140000
160000
iGen OLTP, 4 minute averages, varying thinktimes [ms], 32 HW-threads
1ms think 5ms think 10ms think 50ms think 100ms think 200ms think
Clients
TPM
• Sun Enterprise T2000 has 32 hardware threads of CPU
• Data and log files on RAM (/tmp)
• Database reloaded everytime before the run](https://image.slidesharecdn.com/pgconproblems-190925045742/85/Problems-with-PostgreSQL-on-Multi-core-Systems-with-MultiTerabyte-Data-14-320.jpg)






















This document discusses PostgreSQL performance on multi-core systems with multi-terabyte data. It covers current market trends towards more cores and larger data sizes. Benchmark results show that PostgreSQL scales well on inserts up to a certain number of clients/cores but struggles with OLTP and TPC-E workloads due to lock contention. Issues are identified with sequential scans, index scans, and maintenance tasks like VACUUM as data sizes increase. The document proposes making PostgreSQL utilities and tools able to leverage multiple cores/processes to improve performance on modern hardware.




























![Slow things down to make them go faster [FOSDEM 2022]](https://cdn.slidesharecdn.com/ss_thumbnails/slowthingsdownfosdem-220206162647-thumbnail.jpg?width=640&height=640&fit=bounds)


















































