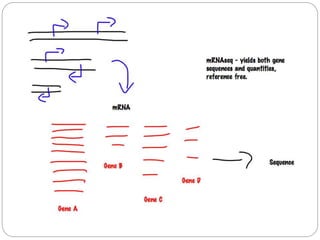
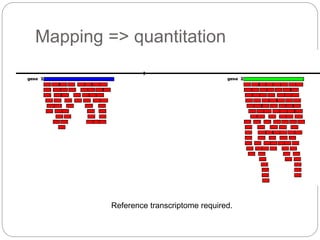
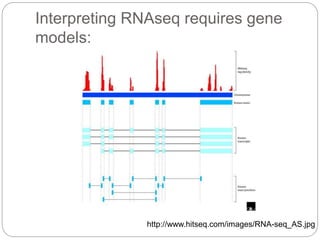
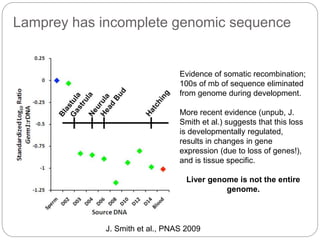
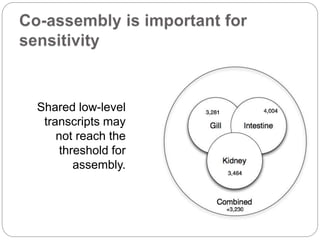
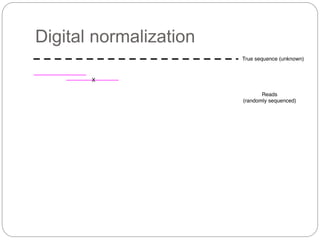
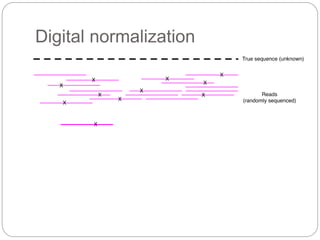
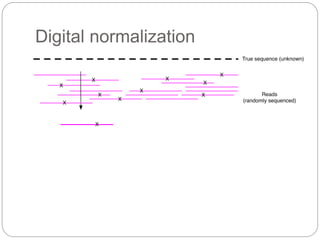
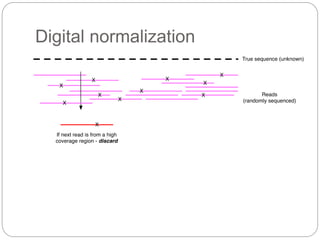
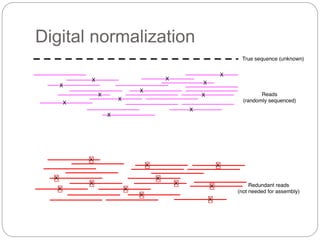
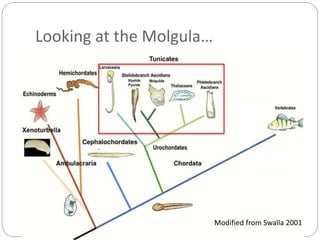
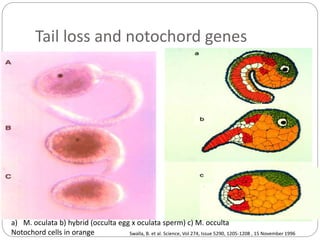
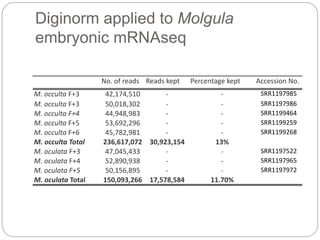
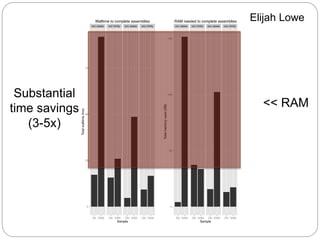
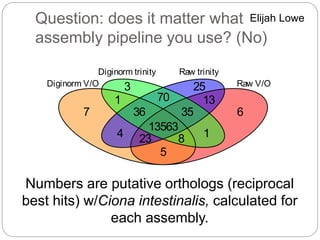
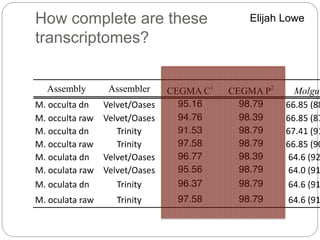
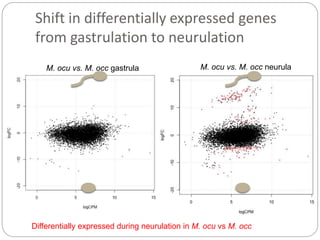
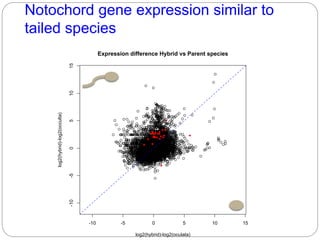
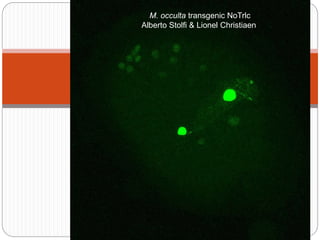
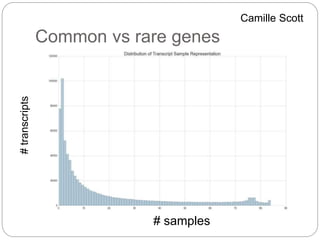
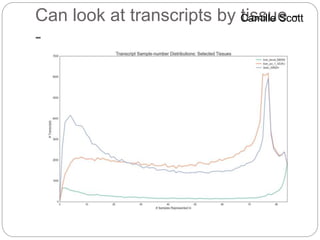
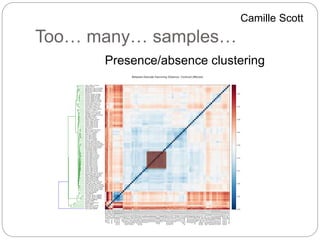
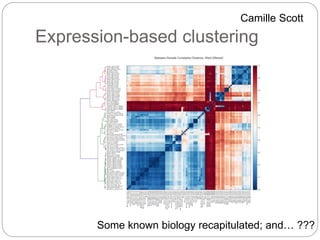
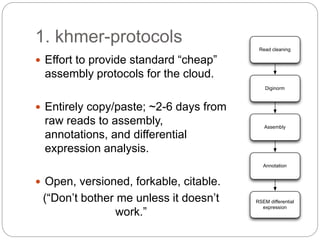
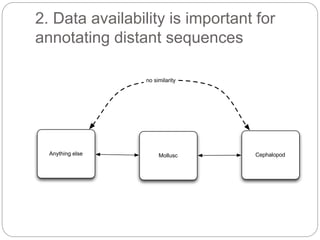
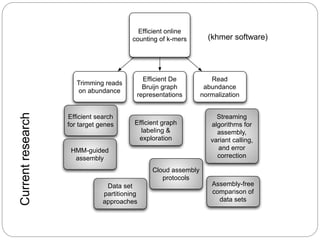
This document discusses challenges and opportunities in applying mRNA sequencing (mRNAseq) to non-model organisms. It describes using digital normalization to cope with large amounts of lamprey mRNAseq data that would otherwise be too computationally intensive to assemble. Digital normalization was applied successfully to Molgula ascidian mRNAseq data, enabling transcriptome analysis. The lamprey transcriptome was assembled from over 5 billion reads from 50 tissues, producing over 600,000 transcripts. Next steps include addressing contamination issues and using the more complete transcriptome to enable various evolutionary and biological studies of lamprey. The document advocates making protocols and data openly available to help characterize genes in non-model organisms.























































![[2013.10.29] albertsen genomics metagenomics](https://cdn.slidesharecdn.com/ss_thumbnails/2013-131029070115-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
















































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)


