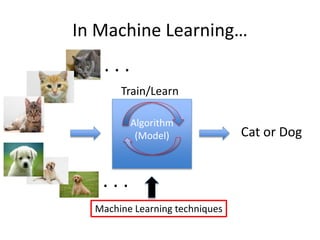
The document discusses the evolution of deep learning and its essential components, differentiating between general and narrow artificial intelligence. It outlines the key concepts of machine learning, neural networks, feature representation, and the advancements that have enabled deep learning's success, such as unsupervised feature learning and improved computational power. Additionally, it highlights various industrial applications of deep learning techniques in companies like Google, Facebook, and Microsoft, as well as challenges faced in non-pattern recognition domains.




















![Stacked Autoencoders
1. Train one layer autoencoder at a time [unsupervised learning] and stack
them
2. Then train the final network using the available labels [supervised learning]
Low level features
Higher level features
Higher level features
INPUT LABEL
Techniques for Representation
Learning
Input](https://image.slidesharecdn.com/introductiontodeeplearning-160507133124/85/Deep-Learning-Towards-General-Artificial-Intelligence-22-320.jpg)












![Variations of Transfer Learning
• Multi-Instance Learning (when labels are not
available at the instance level)
Document Classification Model
Based on the similarity of the sentence/word
embedding [Kotzias, Denil and deFreitas, 2014]](https://image.slidesharecdn.com/introductiontodeeplearning-160507133124/85/Deep-Learning-Towards-General-Artificial-Intelligence-35-320.jpg)
![Variations of Transfer Learning
• Max-margin Learning without labels
[From machine learning to machine reasoning, Leon Bottou, 2014]](https://image.slidesharecdn.com/introductiontodeeplearning-160507133124/85/Deep-Learning-Towards-General-Artificial-Intelligence-36-320.jpg)
![Variations of Transfer Learning
• Max-margin Learning without labels
[NLP almost from scratch, Ronan Collobert et al., 2011]](https://image.slidesharecdn.com/introductiontodeeplearning-160507133124/85/Deep-Learning-Towards-General-Artificial-Intelligence-37-320.jpg)









































































































