The document provides the course calendar and lecture plan for a machine learning course. The course calendar lists the class dates and topics to be covered from September to January, including Bayes estimation, Kalman filters, particle filters, hidden Markov models, Bayesian decision theory, principal component analysis, and clustering algorithms. The lecture plan focuses on clustering methods, including k-means clustering, mixtures of Gaussians models, and using the expectation-maximization (EM) algorithm to estimate the parameters of Gaussian mixture models.


![4
1 2
:D-dimensional random vector
N dataset of : X:={ , , , }
: A group of data points whose inter-distances are small
compared with the distances to the points outside of the cluster
N
Cluster
Prototy
x
x x x x
of cluster: 1
: Find a set of vectors , such that the sum of the squared
disstances of each point to its cvlosest vector is minimized.
k
k
k
k K
K
pe
Aim
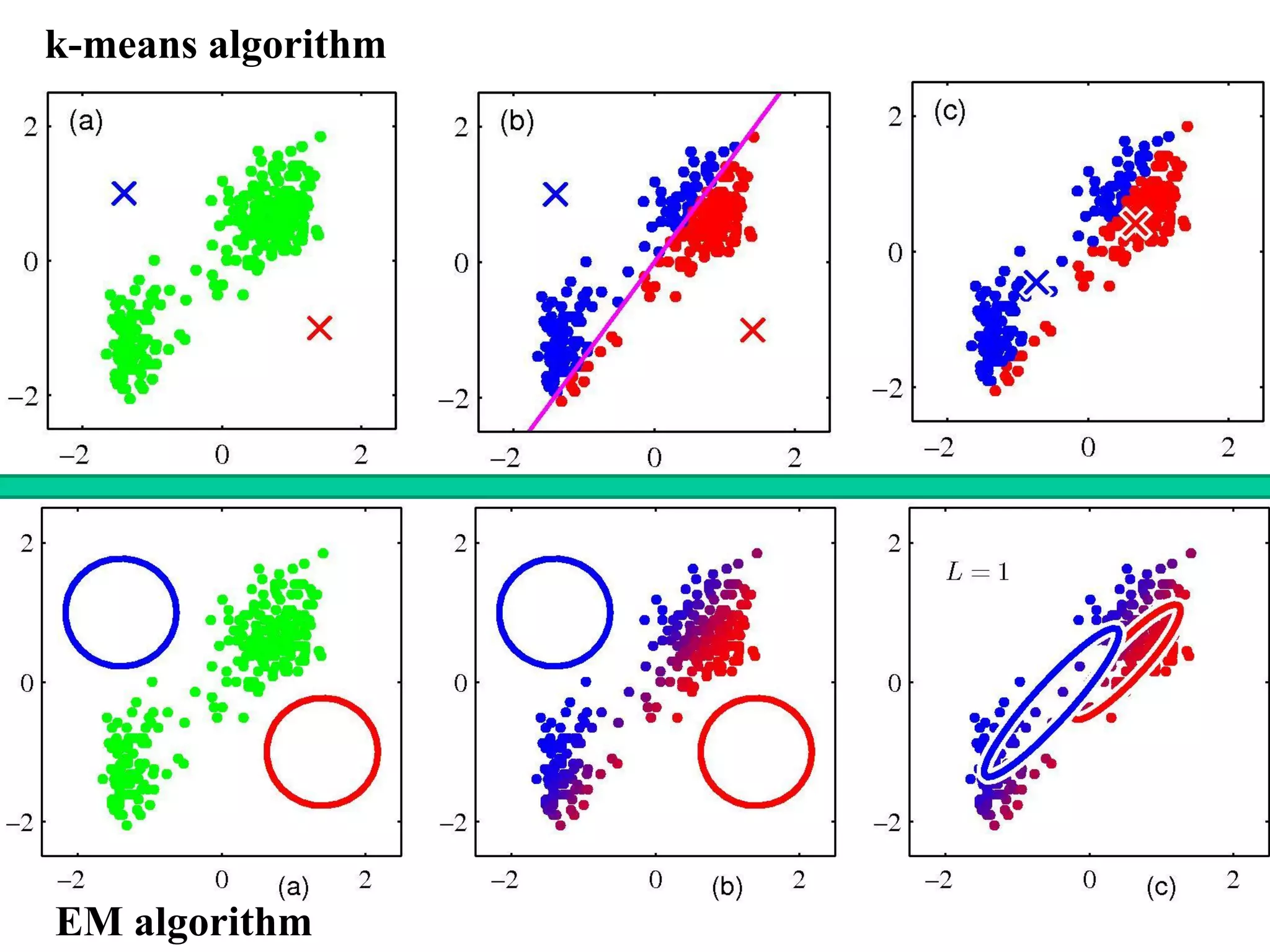
2. K-means Algorithm
The K-means algorithm is a non-statistical approach of clustering of
data points in multi-dimensional feature space.
Problem: Partition the dataset into some number K of clusters
(K is known)
Fig. 1
1 [Bishop book[1] and its web site]](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-4-2048.jpg)
![5
Fig. 1
1 [Bishop book[1] and its web site]](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-5-2048.jpg)



![9
Example 1 [Bishop book[1] and its web site]
Fig.2
(0)
1
(0)
2](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-9-2048.jpg)
![Fig. 3 [1]
Application of k-means algorithm for color-based image
segmentation [Bishop book[1] and its web site]
K-means clustering applied to the color vectors of pixels in RGB
color-space](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-10-2048.jpg)
![11
1
[Mixture of Gaussians]
Conside a superposition of Gaussians (Normal distributions)
,
K
k k k
k
K
p x x
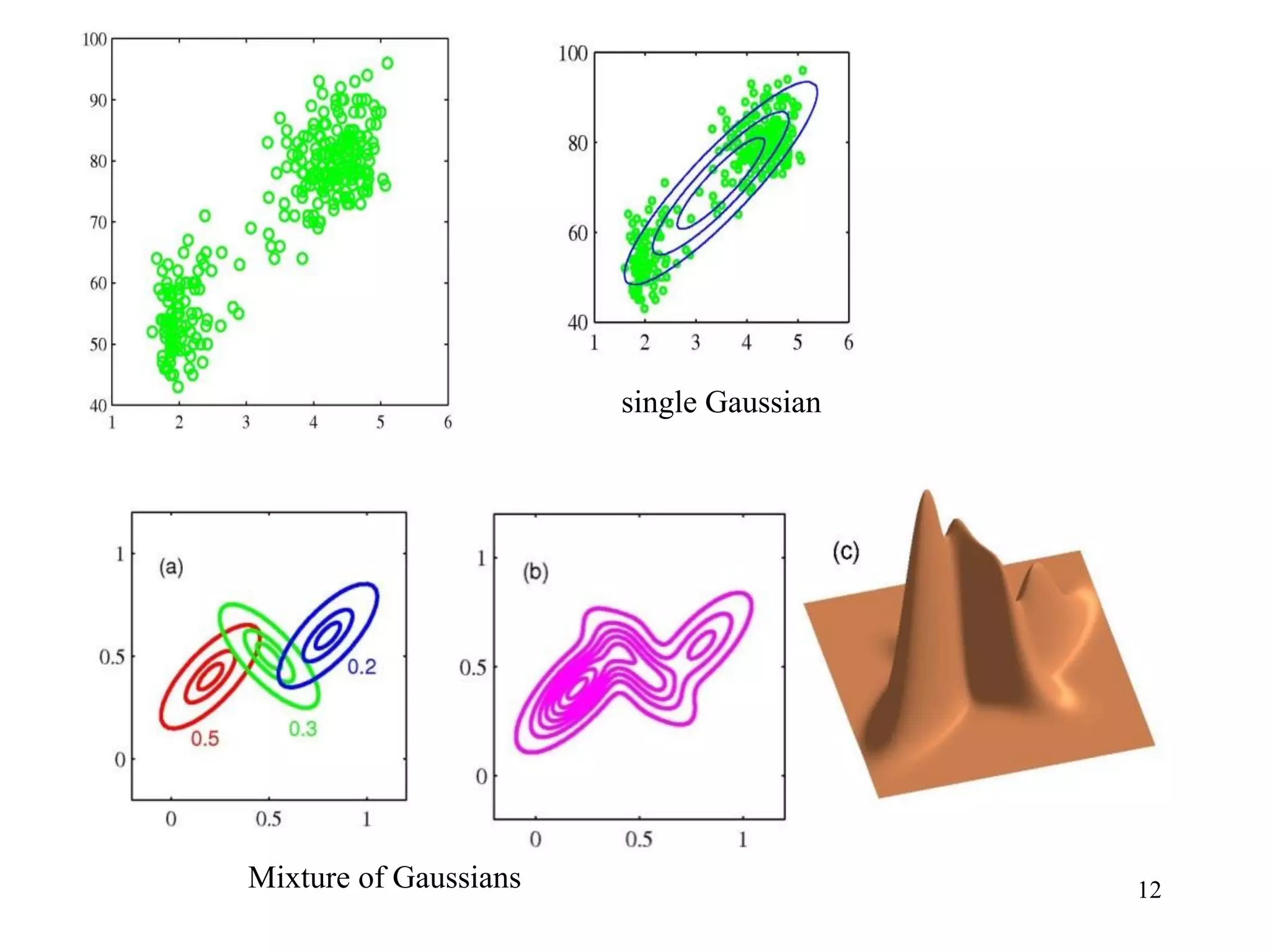
3. Mixtures of Gaussians
- Limitations of single Gaussian pdf model
Examples [Bishop[1]]
Single Gaussian model does not capture the multi-modes feature.
Fig 4
Mixture distribution approach: uses the linear combination of basic
distributions such as Gaussians
mixing coefficients mixture component
(5)
single Gaussian Mixture of Gaussians](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-11-2048.jpg)





![18
Three equations ()-() do not give solutions directly because
, contain unknowns , , and in complex ways.
[EM algorithm for Gaussian Mixture Mode]
Simple iterative scheme which altaernate the
nk kz N
E (Expectation)
and M (Maximization) steps.
: Evaluate the posterior probabilities (responsibilities)
using the current parameters
: Re-estimate parameters , , a
nkz
E step
M step
nd using the
evaluated
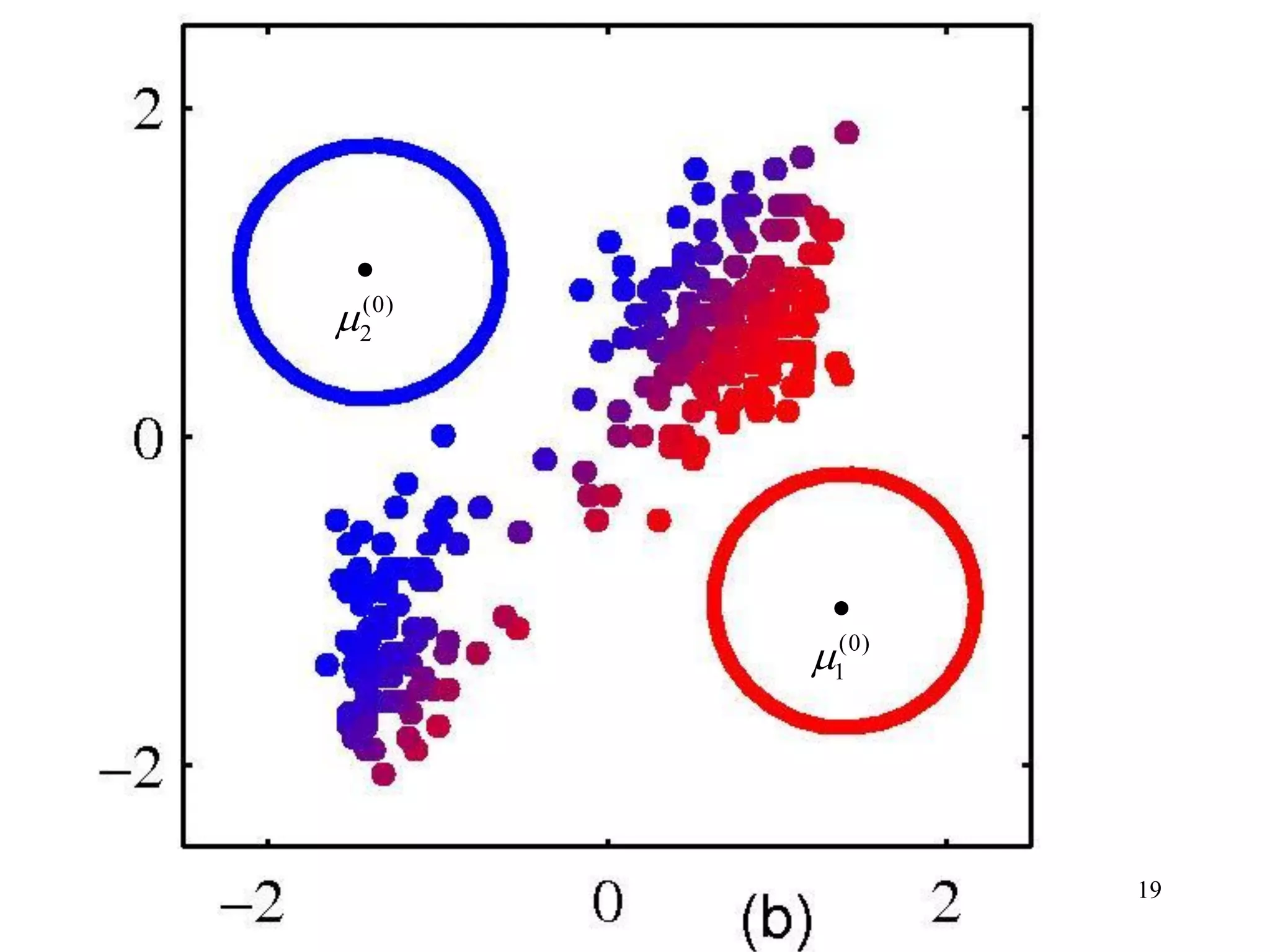
Color illustration of in two-category case
nk
nk
z
z
](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-18-2048.jpg)
![20
Example 2 EM algorithm [Bishop book[1] and its web site]
(0)
1
(0)
2](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-20-2048.jpg)
![22
References:
[1] C. M. Bishop, “Pattern Recognition and Machine Learning”,
Springer, 2006
[2] R.O. Duda, P.E. Hart, and D. G. Stork, “Pattern Classification”,
John Wiley & Sons, 2nd edition, 2004](https://image.slidesharecdn.com/2012mdsp-pr12kmeansmixtureofgaussian-130701022427-phpapp02/75/2012-mdsp-pr12-k-means-mixture-of-gaussian-22-2048.jpg)


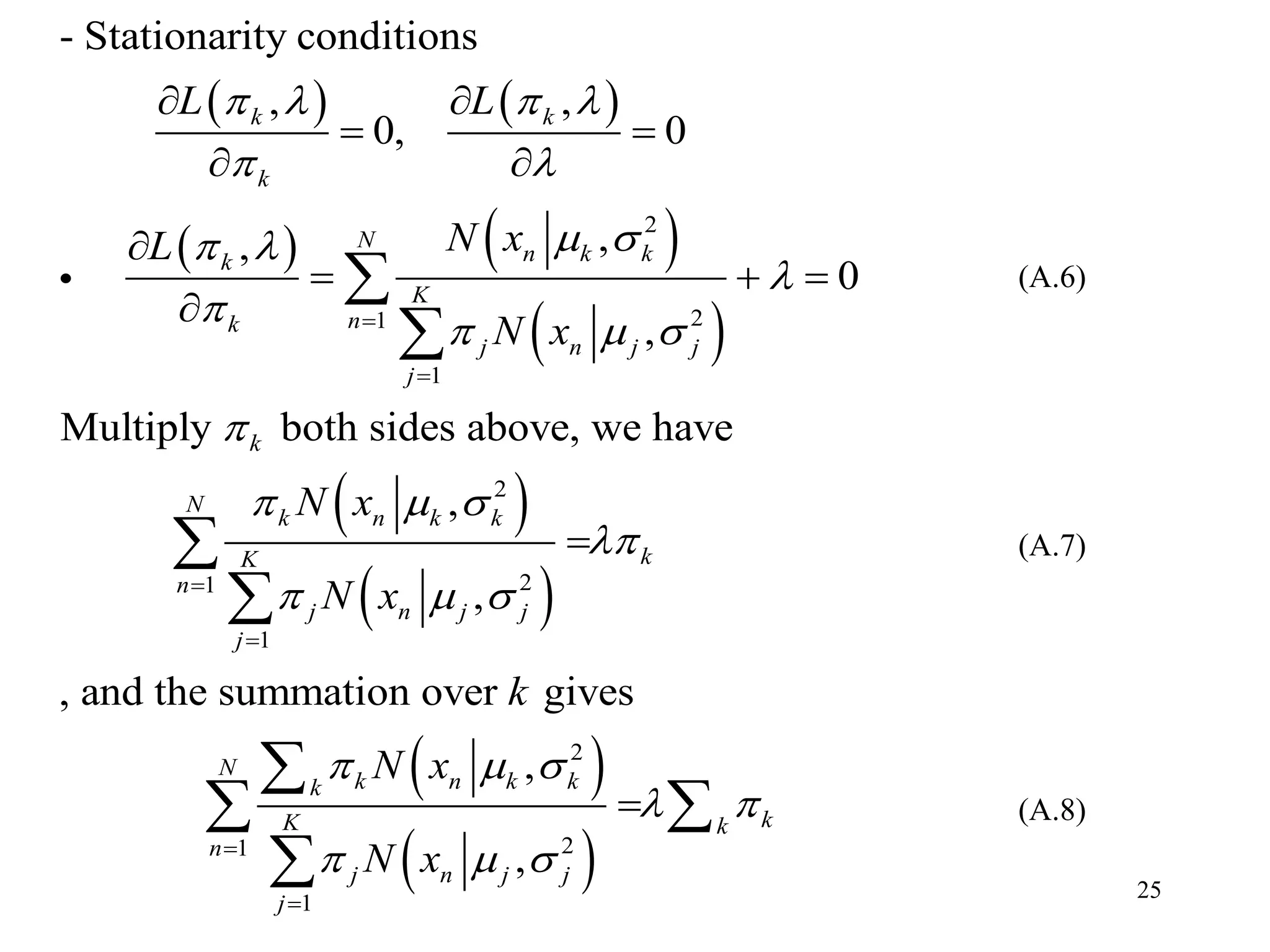
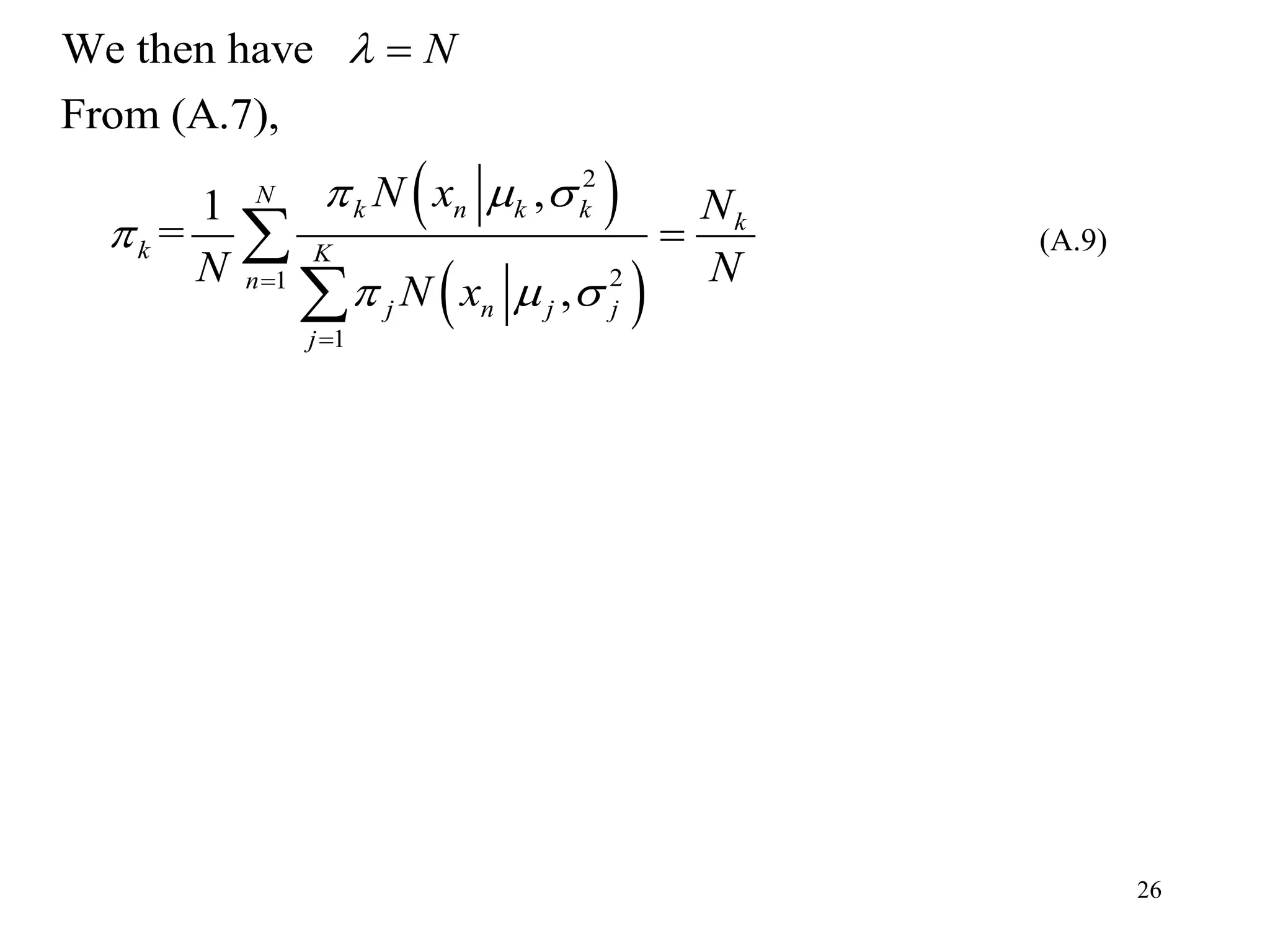

































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

