Downloaded 13 times







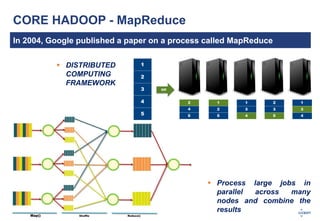
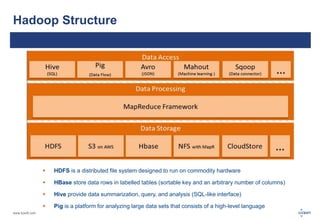
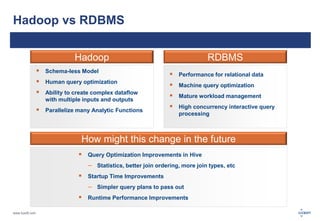

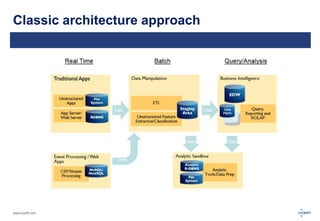
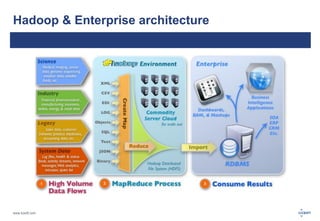
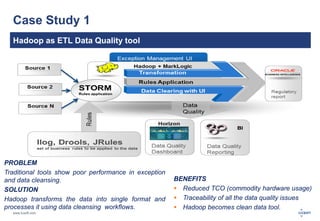
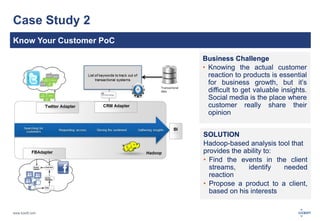
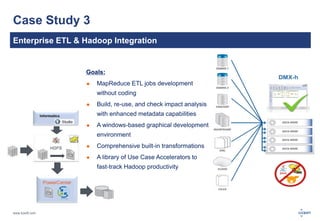



The document discusses big data, its challenges, and the advantages of using Hadoop over traditional relational databases (RDBMS). It highlights the limitations of RDBMS for processing large datasets and the structure and components of Hadoop that make it suitable for handling big data. Additionally, it presents case studies demonstrating Hadoop's effectiveness in ETL processes and customer analytics.







![Kb 40 kevin_klineukug_reading20070717[1]](https://cdn.slidesharecdn.com/ss_thumbnails/kb40kevinklineukugreading200707171-101026100915-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































































