Downloaded 51 times




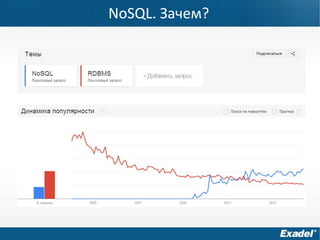


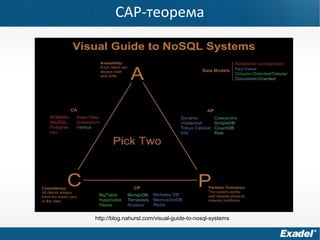

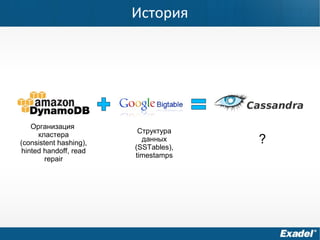
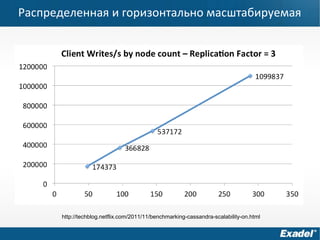






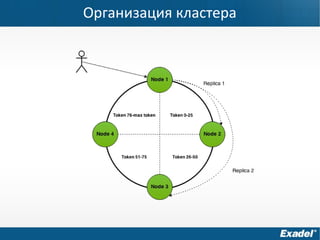
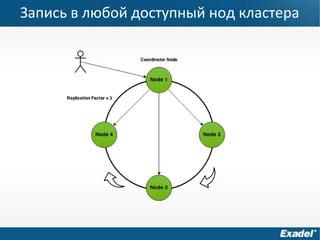
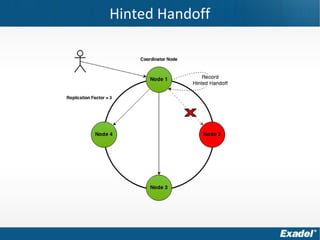
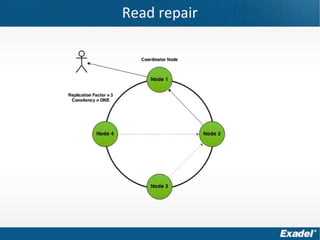


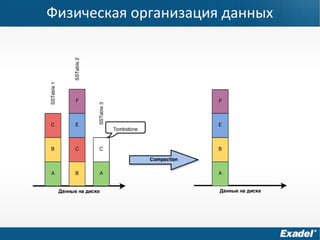

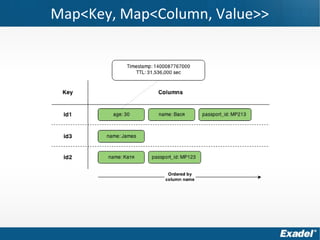

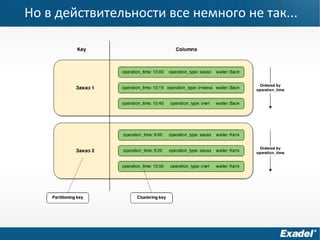



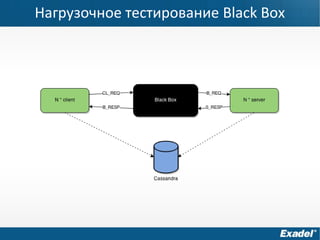


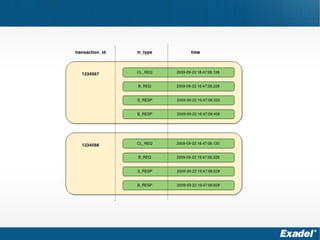

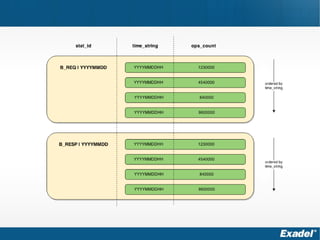





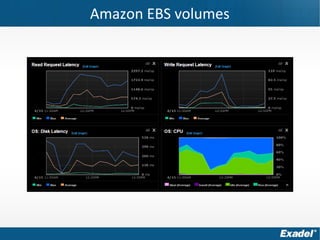







Документ предоставляет обзор Apache Cassandra и концепции NoSQL, описывая его внутреннее устройство, возможности и ограничения. Основное внимание уделяется архитектуре, администрированию и практическим примерам использования базы данных, а также нюансам, которые следует учитывать при работе с Cassandra. Рассматриваются ситуации, когда Cassandra подходит или не подходит для использования, включая аспекты масштабируемости и производительности.














































































