Downloaded 1,594 times

















![Contact Information If you have further questions or comments: Amr Awadallah CTO, Cloudera Inc. [email_address] 650-362-0488 twitter.com/awadallah twitter.com/cloudera](https://image.slidesharecdn.com/awadallah-final-tdwibiexecsum2009-090805180646-phpapp01/75/How-Hadoop-Revolutionized-Data-Warehousing-at-Yahoo-and-Facebook-22-2048.jpg)


Hadoop was developed to solve problems with data warehousing systems at Yahoo and Facebook that were limited in processing large amounts of raw data in real-time. Hadoop uses HDFS for scalable storage and MapReduce for distributed processing. It allows for agile access to raw data at scale for ad-hoc queries, data mining and analytics without being constrained by traditional database schemas. Hadoop has been widely adopted for large-scale data processing and analytics across many companies.
Presentation by Amr Awadallah discusses how Hadoop transformed data warehousing at Yahoo and Facebook.
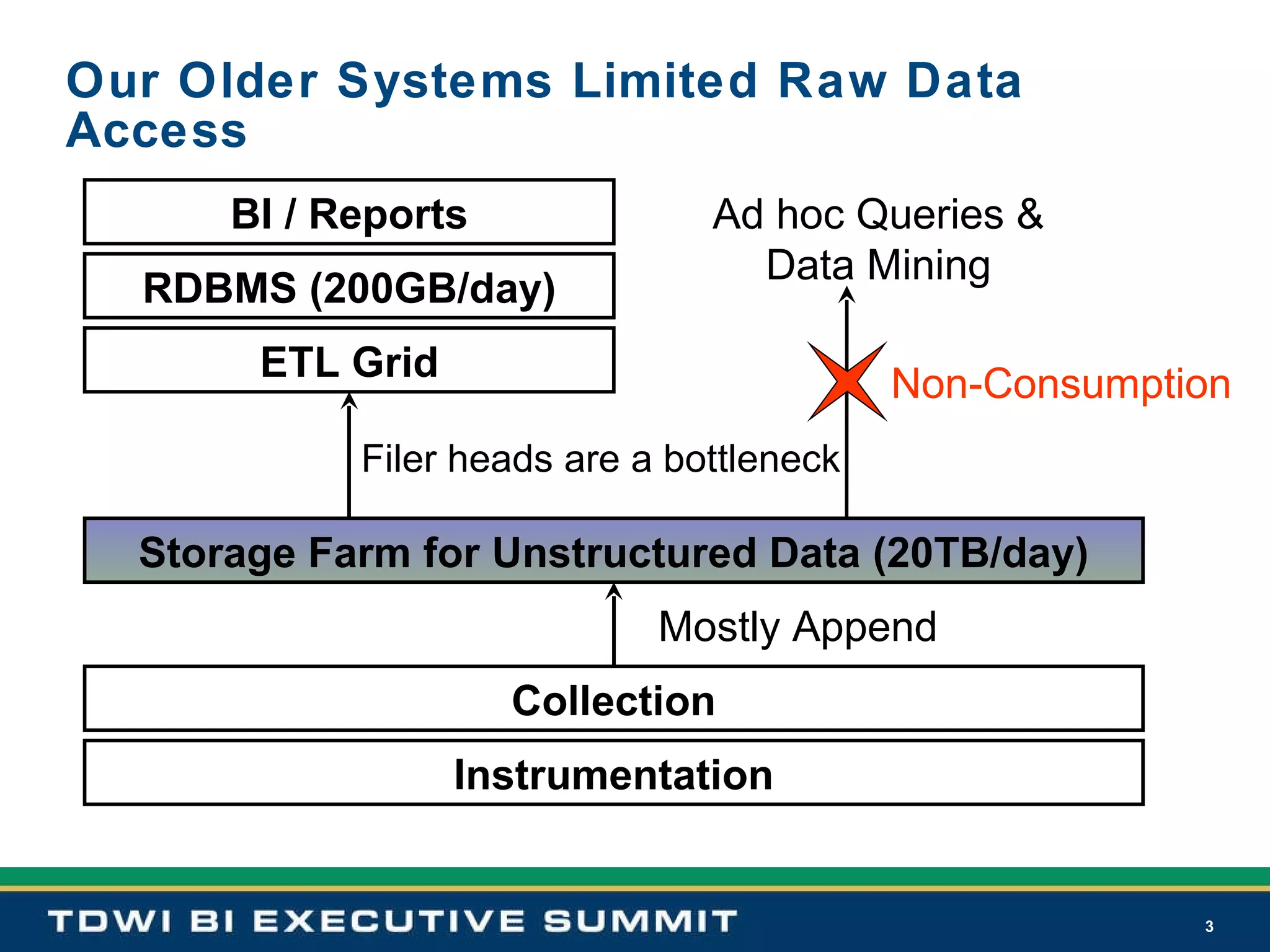
Older systems faced raw data access limitations, slow ETL processes, and data reprocessing needs, which Hadoop aimed to solve.
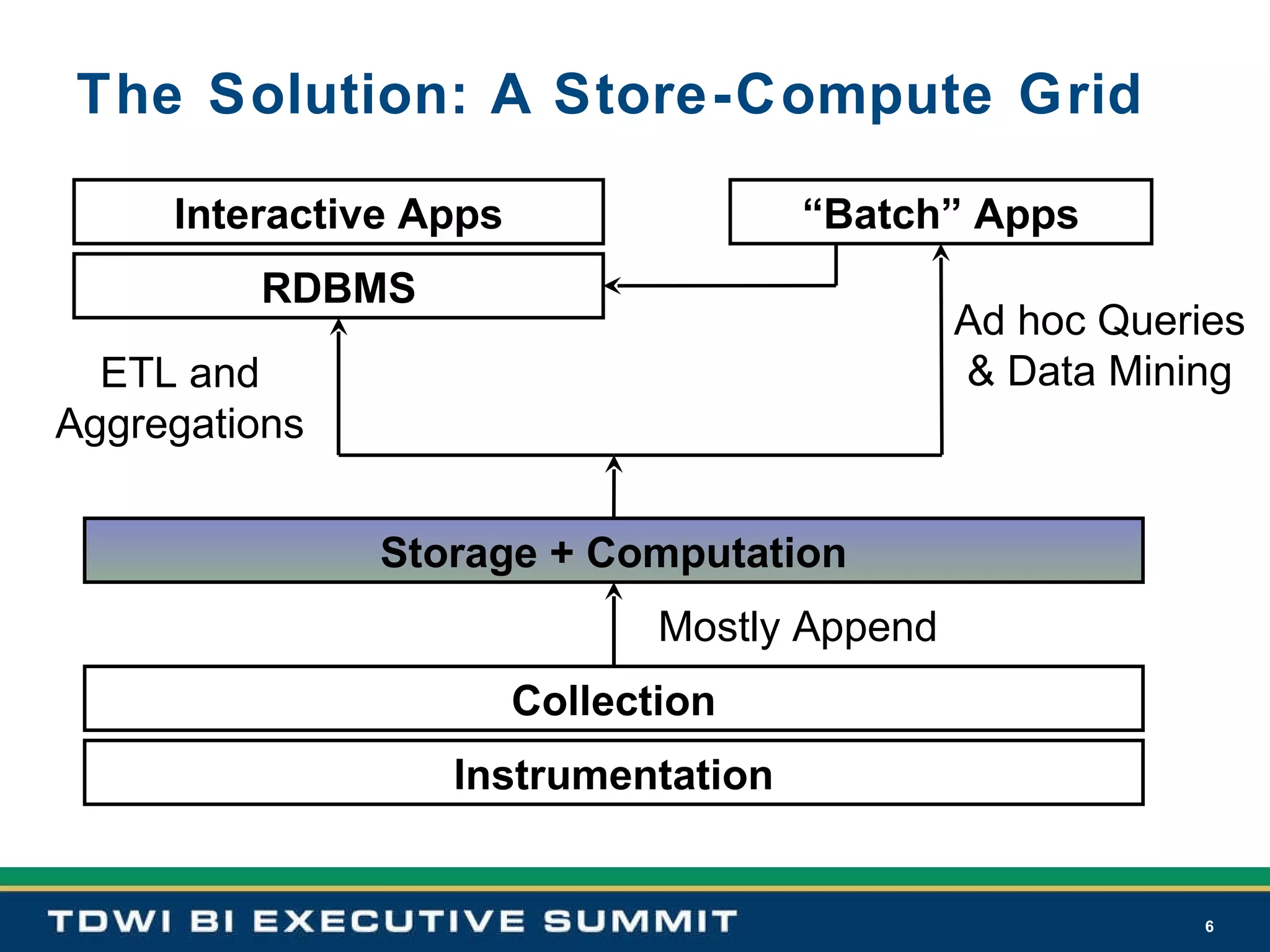
Introduces Hadoop as a scalable, fault-tolerant grid OS combining HDFS and MapReduce, detailing its history and major milestones.
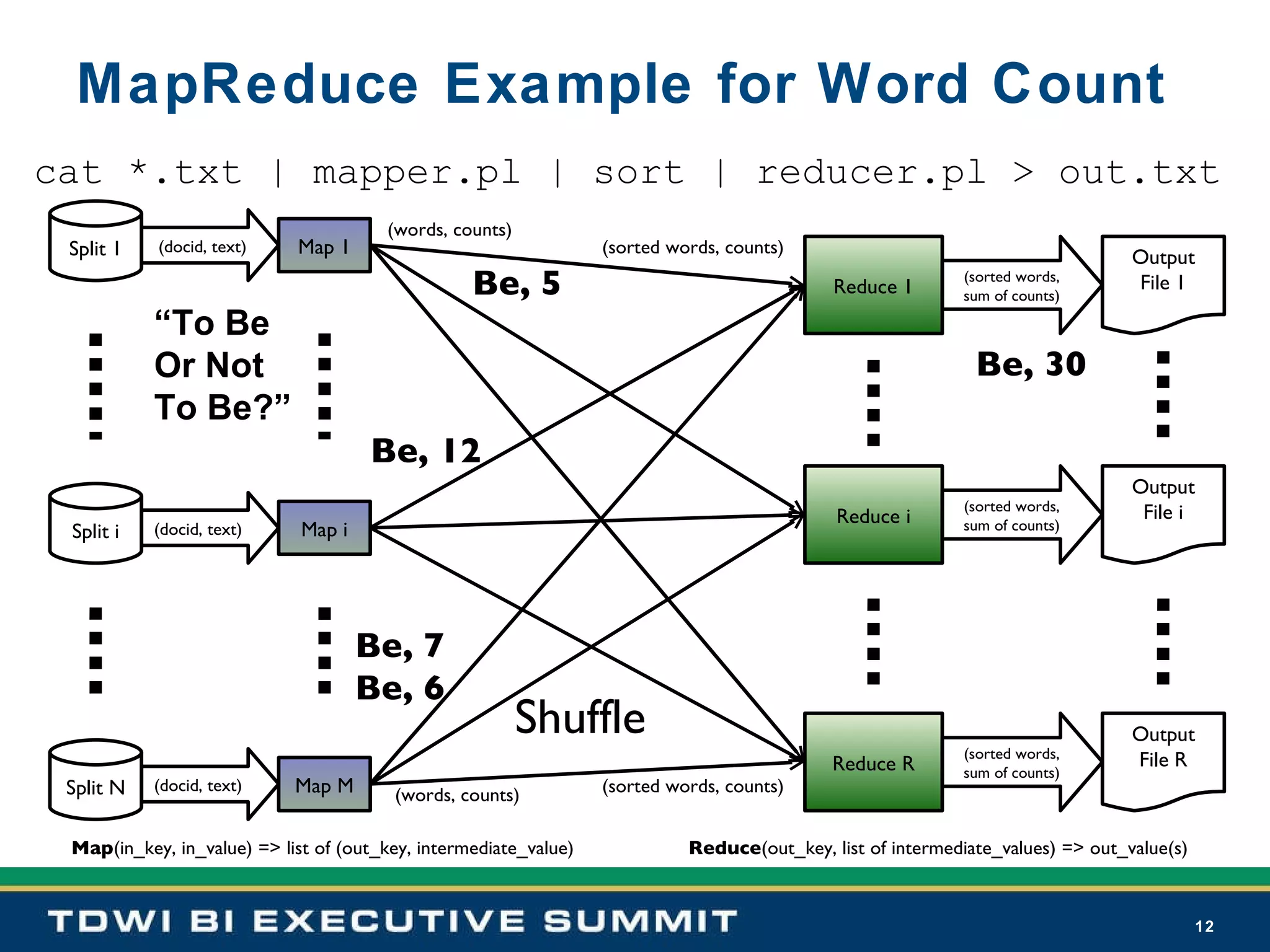
Hadoop's design axioms emphasize self-management, scalability, and processing efficiency through HDFS and MapReduce.
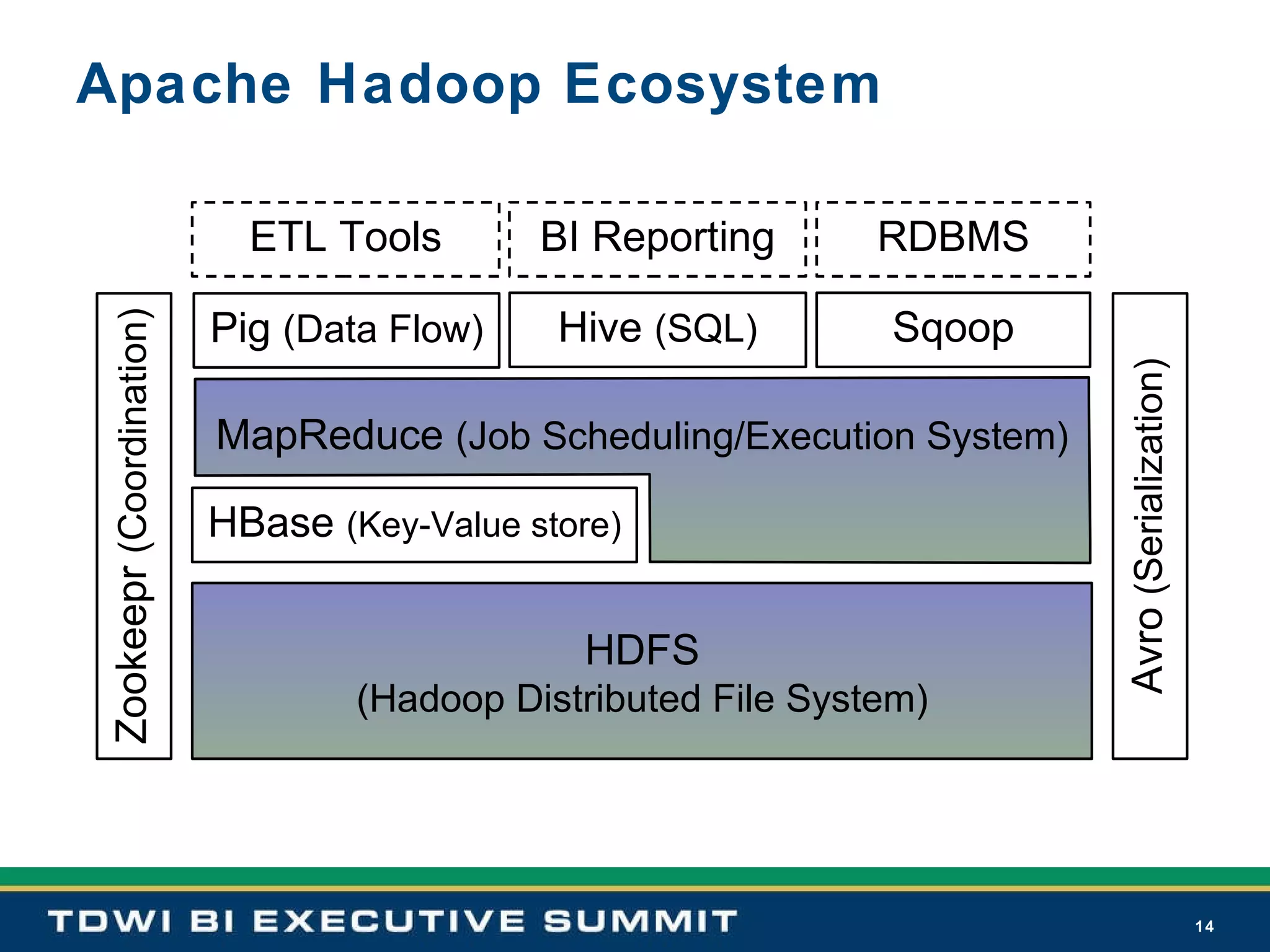
Highlights Hadoop's diverse applications, including web indexing, fraud detection, and its ecosystem of languages like Pig and Hive.
Comparison of Hadoop and RDBMS, emphasizing Hadoop’s unstructured data handling, scalability, and associated criticisms.
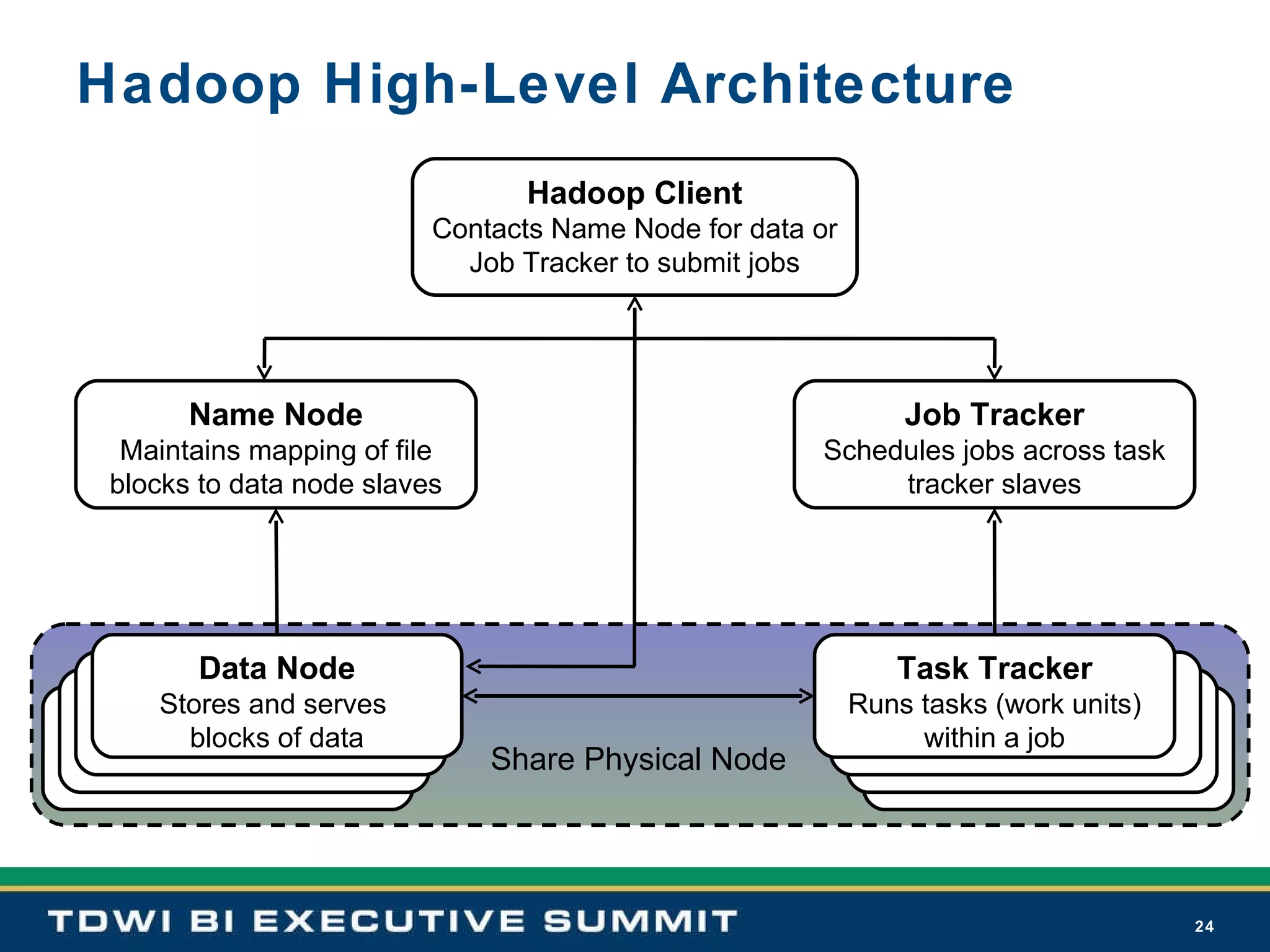
Hadoop is positioned as an economically scalable data grid OS that enhances BI system agility, followed by contact and architectural details.



























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













