Download as PDF, PPTX




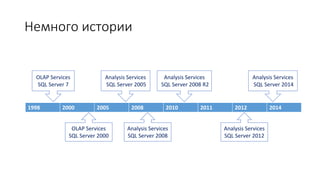
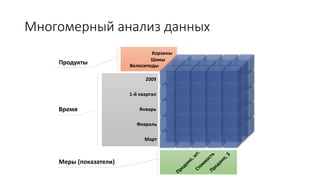
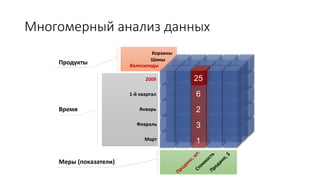

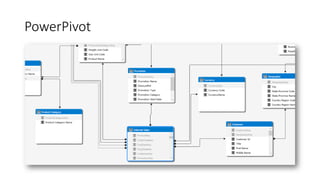
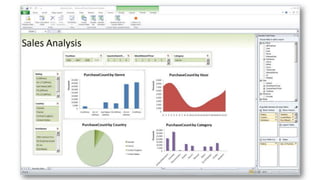
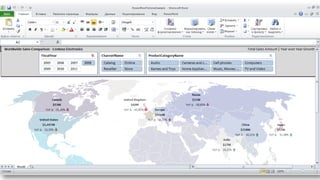
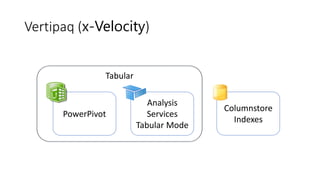


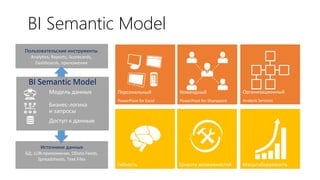
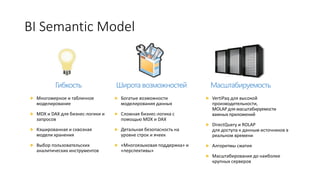
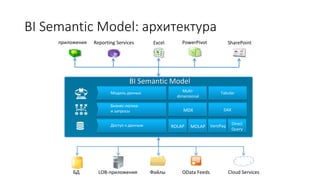



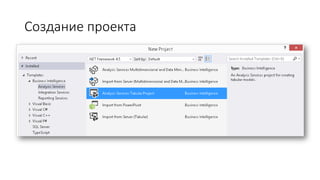





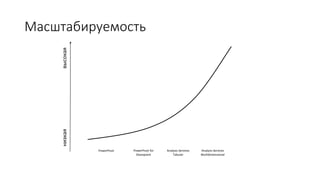




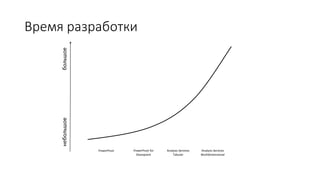


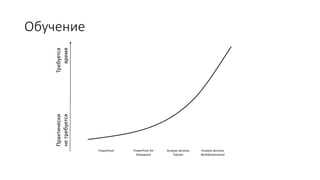

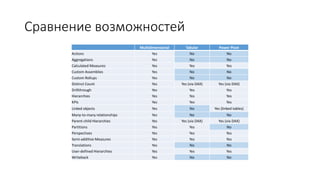

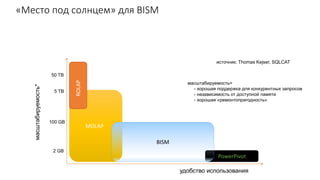


Документ рассматривает табличную модель SQL Server Analysis Services 2014 как альтернативу многомерным кубам, описывая их архитектуру, возможности и ключевые отличия. Он подчеркивает преимущества табличной модели, такие как высокая производительность и простота разработки, а также приводит рекомендации по выбору между табличным и многомерным режимами в зависимости от требований бизнеса. В заключение, документ предлагает сравнительный анализ возможностей разных моделей, включая таблицы PowerPivot и их функции.






























































