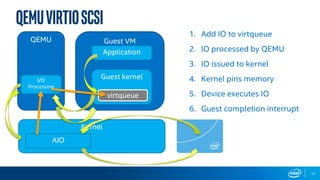
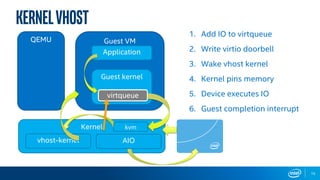
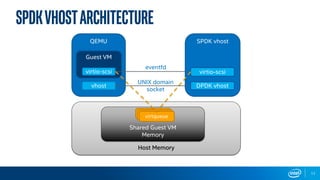
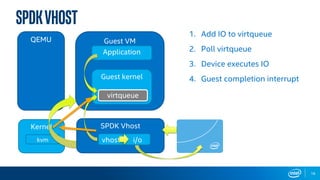
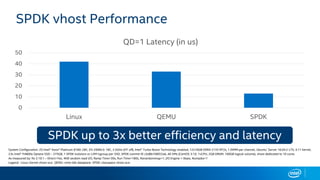
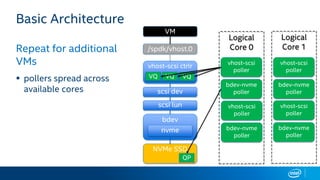
The document discusses Intel's storage software products and highlights the performance of their technologies, including the Storage Performance Development Kit (SPDK). It notes that performance can vary based on system configurations and emphasizes the importance of consulting additional benchmarks and sources for accurate performance evaluation. Additionally, it outlines the benefits of using SPDK for maximizing IOPS and reducing latency in various storage applications.






















































![[Oracle DBA & Developer Day 2016] しばちょう先生の特別講義!!ストレージ管理のベストプラクティス ~ASMからExada...](https://cdn.slidesharecdn.com/ss_thumbnails/mktgdd2-3stragemanagementfordl2-200702092359-thumbnail.jpg?width=640&height=640&fit=bounds)
































































