Downloaded 114 times

























![DATA MODEL
{
column family
“users”: { key
“alice”: {
“city”: [“St. Louis”, 1287040737182],
columns
row (name, value, timestamp)
“name”: [“Alice” 1287080340940],
,
},
...
},
“locations”: {
},
...
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-44-320.jpg)
![IT’S A DISTRIBUTED HASH TABLE
WITH A TWIST...
COLUMNS IN ARE STORED TOGETHER ON ONE NODE,
IDENTIFIED BY <keyspace, key>
{
column family
“users”: {
key
“
alice”: {
“city”: [“St. Louis” 1287040737182],
,
columns
“name”: [“Alice” 1287080340940],
,
},
...
},
}
...
bob
alice s3b
3e8](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-45-320.jpg)

![COLUMNS
SUPPORTED QUERIES
EXACT MATCH
{
RANGE “users”: {
“alice”: {
“city”: [“St. Louis”, 1287040737182],
PROXIMITY “friend-1”: [“Bob” 1287080340940],
,
friends “friend-2”: [“Joe”, 1287080340940],
“friend-3”: [“Meg” 1287080340940],
,
“name”: [“Alice” 1287080340940],
,
},
...
}
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-47-320.jpg)




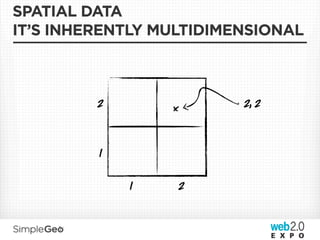
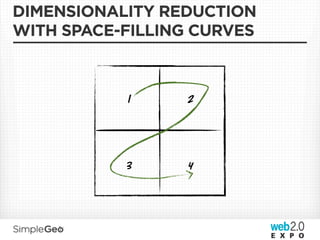
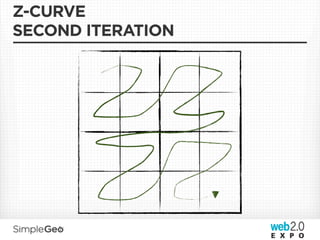
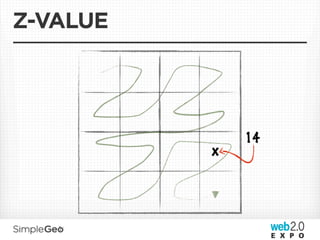
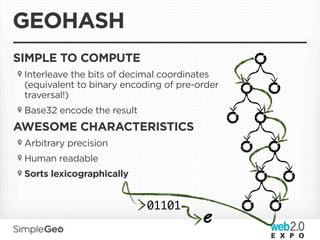
![DATA MODEL
{
“record-index”: {
key
<geohash>:<id>
“9yzgcjn0:moonrise hotel”: {
“”: [“”, 1287040737182],
},
...
},
“records”: {
“moonrise hotel”: {
“latitude”: [“38.6554420”, 1287040737182],
“longitude”: [“-90.2992910”, 1287040737182],
...
}
}
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-58-320.jpg)
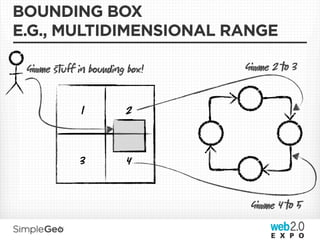







![DATA MODEL
{
“record-index”: {
“layer-name:37 .875, -90:40.25, -101.25”: {
“38.6554420, -90.2992910:moonrise hotel”: [“” 1287040737182],
,
...
},
},
“record-index-meta”: {
“layer-name:37 .875, -90:40.25, -101.25”: {
“split”: [“false”, 1287040737182],
}
“layer-name: 37 .875, -90:42.265, -101.25” {
“split”: [“true”, 1287040737182],
“child-left”: [“layer-name:37 .875, -90:40.25, -101.25” 1287040737182]
,
“child-right”: [“layer-name:40.25, -90:42.265, -101.25” 1287040737182]
,
}
}
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-79-320.jpg)
![DATA MODEL
{
“record-index”: {
“layer-name:37 .875, -90:40.25, -101.25”: {
“38.6554420, -90.2992910:moonrise hotel”: [“” 1287040737182],
,
...
},
},
“record-index-meta”: {
“layer-name:37 .875, -90:40.25, -101.25”: {
“split”: [“false”, 1287040737182],
}
“layer-name: 37 .875, -90:42.265, -101.25” {
“split”: [“true”, 1287040737182],
“child-left”: [“layer-name:37 .875, -90:40.25, -101.25” 1287040737182]
,
“child-right”: [“layer-name:40.25, -90:42.265, -101.25” 1287040737182]
,
}
}
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-80-320.jpg)
![DATA MODEL
{
“record-index”: {
“layer-name:37 .875, -90:40.25, -101.25”: {
“38.6554420, -90.2992910:moonrise hotel”: [“” 1287040737182],
,
...
},
},
“record-index-meta”: {
“layer-name:37 .875, -90:40.25, -101.25”: {
“split”: [“false”, 1287040737182],
}
“layer-name: 37 .875, -90:42.265, -101.25” {
“split”: [“true”, 1287040737182],
“child-left”: [“layer-name:37 .875, -90:40.25, -101.25” 1287040737182]
,
“child-right”: [“layer-name:40.25, -90:42.265, -101.25” 1287040737182]
,
}
}
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-81-320.jpg)
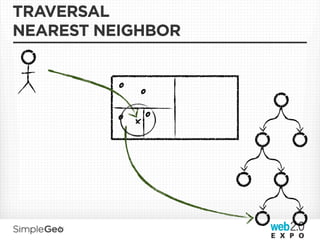
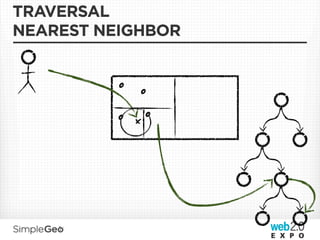
![SPLITTING
IT’S PRETTY MUCH JUST A CONCURRENT TREE
Splitting shouldn’t lock the tree for reads or writes and failures
shouldn’t cause corruption
• Splits are optimistic, idempotent, and fail-forward
• Instead of locking, writes are replicated to the splitting node and the
relevant child[ren] while a split operation is taking place
• Cleanup occurs after the split is completed and all interested nodes are
aware that the split has occurred
• Cassandra writes are idempotent, so splits are too - if a split fails, it is
simply be retried
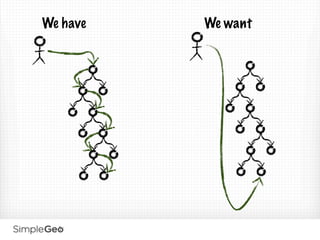
Split size: A Tunable knob for balancing locality and distributedness
The other hard problem with concurrent trees is rebalancing - we
just don’t do it! (more on this later)](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-82-320.jpg)









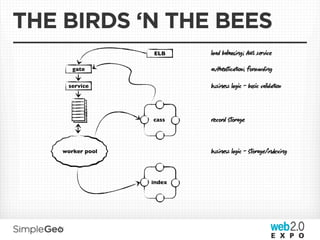
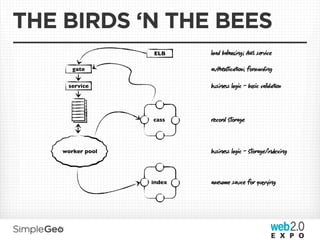












![SAMPLE MANIFEST
# /root/learning-manifests/apache2.pp
package {
'apache2':
ensure => present;
}
file {
'/etc/apache2/apache2.conf':
ensure => file,
mode => 600,
notify => Service[‘apache2’],
source => '/root/learning-manifests/apache2.conf',
}
service {
'apache2':
ensure => running,
enable => true,
subscribe => File['/etc/apache2/apache2.conf'],
}](https://image.slidesharecdn.com/scalablecloudstorage-110407212701-phpapp01/85/Scalable-Data-Storage-Getting-You-Down-To-The-Cloud-116-320.jpg)










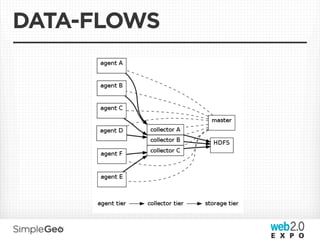






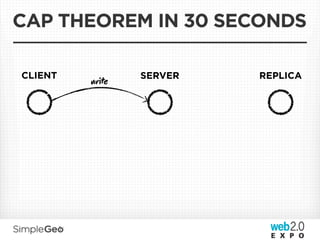
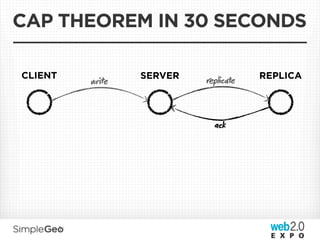
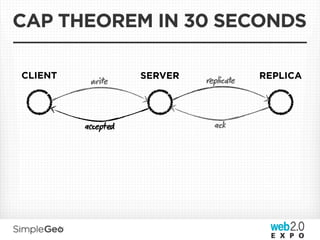
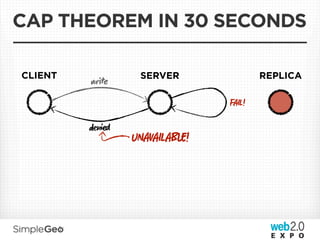
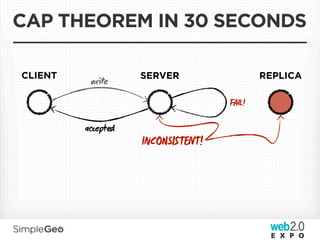
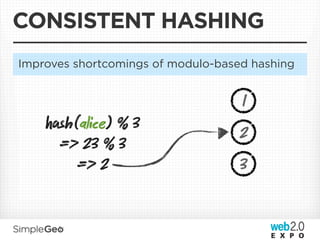
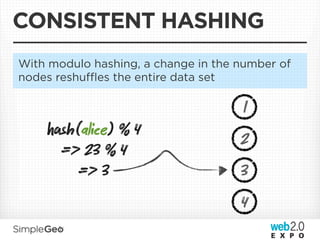
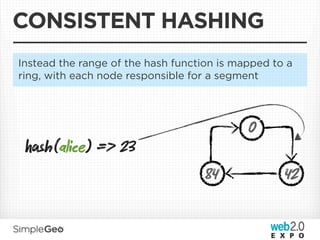
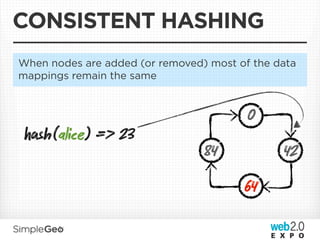
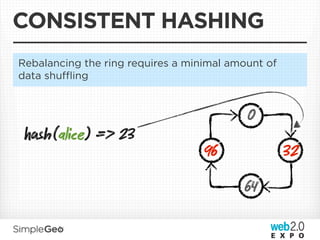
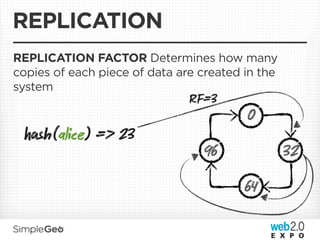
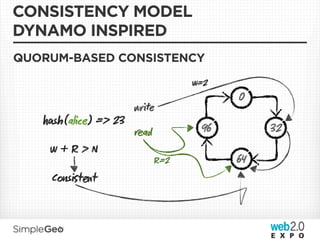
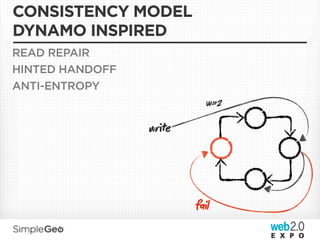
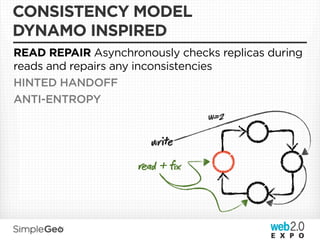
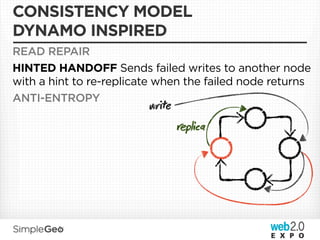
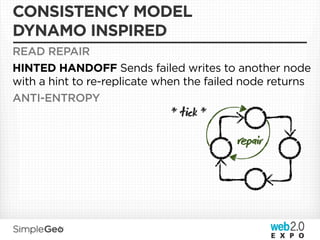
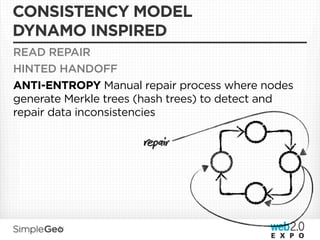
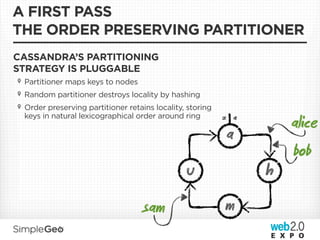
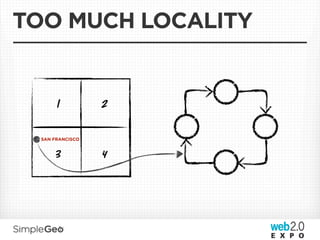
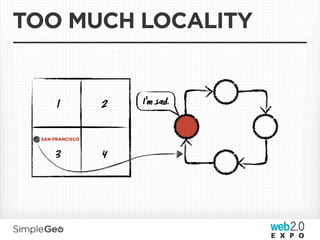
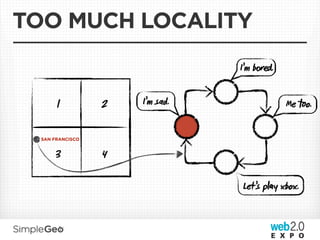
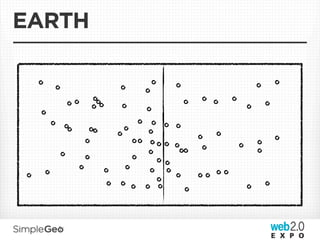
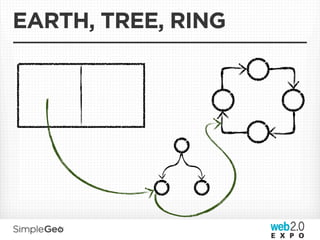
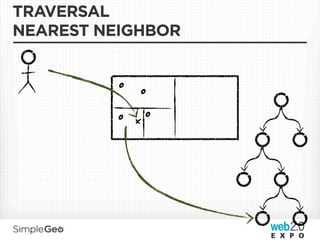
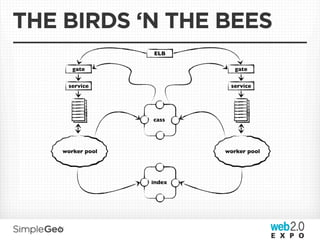
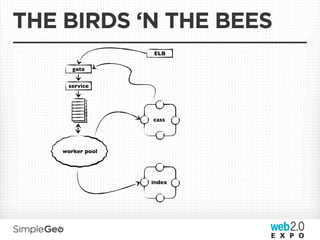
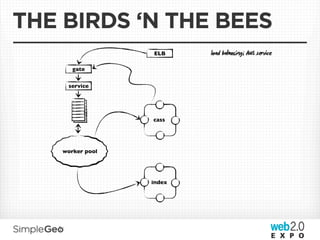
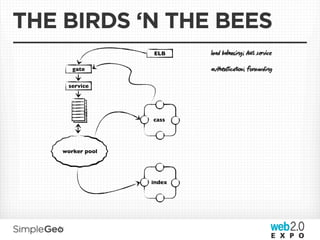
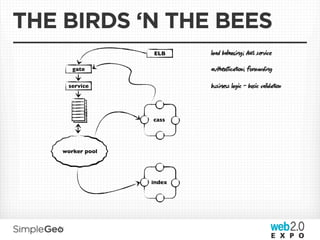
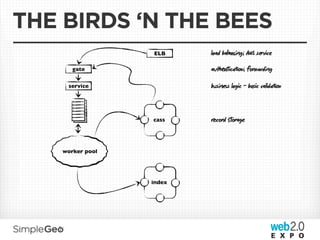
The document discusses the transition from traditional relational databases to scalable cloud-based solutions, highlighting the challenges and limitations of conventional systems such as MySQL in the context of high-scale data management. It emphasizes the principles of the CAP theorem, ACID properties, and introduces Apache Cassandra as a distributed storage solution that offers tunable consistency and fault tolerance through a peer-to-peer architecture. Additionally, it explores data modeling techniques and the importance of locality and partitioning in managing large datasets, particularly for use cases involving spatial data.















































